Hello 大家好!歡迎回來!昨天剛剛分享完深度學習技術 (Deep Learning Techniques),那今天我打算跟大家分享自然語言處理 (Natural Language Processing)。事不宜遲,現在開始!
自然語言處理 (NLP)是人工智慧的一個分支,是一個跨學科領域,結合了語言學、計算機科學和人工智慧,關注電腦與人類語言之間的交互作用,使得計算機能夠理解、解讀和生成人類語言。它涉及開發算法和模型,使計算機能夠理解和處理自然語言,實現機器翻譯、情感分析、問答系統、文本摘要等任務。
自然語言處理對於高效且完整地分析文字和語音資料至關重要。它可透過日常對話中典型的方言、俚語和語法不規則性的差異來運作。以下是一些自動化任務的例子:
 [1]
[1]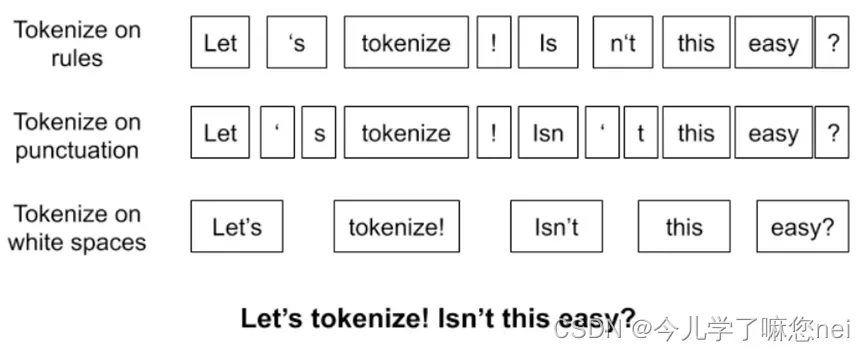 [2]
[2] [3]
[3] [4]
[4] [5]
[5] [6]
[6]雖然 NLP 看起來很好,但還是有一些限制 == 這需要關於外在世界的廣泛知識以及運用操作這些知識的能力,自然語言認知,同時也被視為一個人工智能完備 (AI-complete) 的問題。同時,在自然語言處理中,「理解」的定義也變成一個主要的問題。
是的,「理解」是一個蠻重要的問題,例如:
「我把飯遞給弟弟,因爲煮好了」和「我把飯遞給弟弟,因爲餓了」,兩者都是一個同樣的結構,但我們在中文裏常常省略這些代詞,如果輸入給 NLP,它可能會分不清楚哪一個對應哪個:到底是飯煮好了還是弟弟煮好了?//到底是弟弟餓了還是飯餓了?如果不理解兩者的屬性,就會區分不出來。
對,有些字可能有多重意義。不少的中文相關笑話即是利用類似結構的中文造句而成,此類笑話通常帶有「中文博大精深」之類的詞彙。
某外國人苦學漢語10年,到東方參加漢語考試。試題為「請解釋下列句子」: 阿呆給長官送紅包時,兩個人的對話頗有意思。 長官:「你這是什麼意思?」 阿呆:「沒什麼意思,意思意思。」 長官:「你這就不夠意思了。」 阿呆:「小意思,小意思。」 長官:「你這人真有意思。」 阿呆:「其實也沒有別的意思。」 長官:「那我就不好意思了。」 阿呆:「是我不好意思。」
那個外國人淚流滿面,交白卷回國了。
又或者拿英文作爲例子:
bat 這個單字在以下句子中表示不同的事物
當然,透過字義去除混淆,NLP 軟體可訓練其語言模型或引用字典定義,來識別單字的預期含義,所以這也不算是什麽太大的問題。
我是 Mr. cobble,明天見!


{kind=link}