今天要介紹的是監督式學習的演算法篇的部分~
迴歸主要是預測連續數值型的輸出。它可以通過分析多筆資料來建立數學關係,以預測新的數值輸出。如此一來提高預測的準確性。例如昨天的例子所述,它可用於股票分析以及房地產等應用,也可涉足於其他更多領域。
類神經網路顧名思義就是模擬人**"類"腦"神經"**網路,它由許多人工神經元(類似大腦中的神經細胞)組成,這些神經元相互連接,用於處理和學習數據。ANN一共有三層,每一層都有不同的功能。輸入層接收數據,隱藏層處理數據,而輸出層則產出最終結果。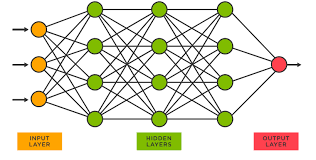
神經網絡最特別的地方在於他會根據使用者輸入的資料,不斷調整權重值,使其達成更準確的預測,是不是很像我們的人生軌跡,藉由不斷學習變得越來越聰明,最後能夠在各種不同的任務中做出準確的決策~
應用舉例: 銀行使用借款人的學歷和年收入作為預測還貸款可能性的依據,並進行持續的權重調整。例如,我們將一開始學歷的初始權重設為5,但調整後增至8;年收入的初始權重為5,但後來降至2。我們可以將學歷和年收入輸入到一個層中,並使用隱藏層根據數據結果調整權重值,以更準確地反映這些特徵對預測的影響,使其達成精準預測。
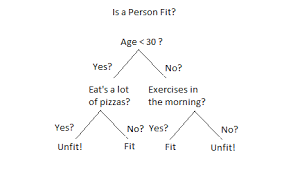
Decision Tree的特色是它以樹狀結構呈現,每個節點都表示為一個特徵,分支代表該特徵的不同取值,而葉子節點表示最終的分類或數據的預測結果。這種模型通過選擇最具區分性的特徵來進行分割,自動生成決策規則,使其能夠根據輸入特徵來進行預測。但它容易有過度擬合(Overfitting)的問題,因此要不斷的增加訓練資料、或是減少維度、降低屬性來避免。
Overfitting: 指模型在訓練過程中過度擬合訓練數據,導致對新數據的泛化性能下降。簡單來說就是模型在訓練的時候表現良好,但在實際應用中的則表現不佳、不準確。而Overfitting通常是因為模型太複雜或訓練數據過少引起的。
相信以下這張圖各位一看就懂甚麼是決策樹~
SVM通常用於給定兩筆(或多筆)不同類別的數據,找出最佳的分界線,以使這兩個類別的數據點盡可能遠離分界線,同時確保未知數據點易於分類。這個分界線被稱為「超平面」,而SVM的目標就是找到這個超平面,以實現最佳的分類效果。


 iThome鐵人賽
iThome鐵人賽