在增強式學習中,Agent 泛指被訓練、負責學習的對象,其中,Agent 包含以下四個重要元素:
Agent state (負責學習的對象的狀態):在強化學習中,Agent 使用策略(policy) 並依據目前的狀態作出應對的行為(action),從中最大化環境()environment與狀態(states) 之間,在轉換中獲得的預期回饋的對象(entity)。
Policy (方針/策略):定義負責學習的對象(agent state)在給定時間的行為。 政策是從感知的環境(environment)狀態到處於這些狀態時,要採取的行動的映射。 以心理學來解釋,一組刺激-反應規則(stimulus–response rules)或關聯。 策略可能是簡單的函數或查找表,或是涉及大量計算,例如搜索過程。策略是強化學習代理的核心,因為它本身就足以確定做出決策行為(determine behavior)。 一般來說,策略可能是隨機的,指定每個動作(action)的概率(probabilities)。
Value functions (價值函數):狀態的價值是Agent從該狀態開始在未來期望積累的獎勵總額。獎勵決定了環境狀態的直接、內在的可取性,而價值則表示在考慮了可能出現的狀態以及這些狀態中,可用的獎勵後狀態的長期可取性。 例如,一個狀態可能總是產生較低的即時獎勵,但仍然具有較高的價值,因為它經常跟隨其他產生高獎勵的狀態。 反之。 以人類為例,獎勵有點像快樂(如果高)和痛苦(如果低),而價值觀則對應於我們對環境處於特定狀態時的高興或不高興的更精緻和更有遠見的判斷。
Model (模型):模仿環境行為、允許對環境的行為進行推斷。例如,給定一個狀態和動作,該模型可能會預測由此產生的下一個狀態和下一個獎勵。 模型(Model)用於規劃,我們指的是通過在實際經歷之前考慮未來可能出現的情況來決定行動方案的任何方式。 使用模型和規劃來解決強化學習問題的方法稱為基於模型的方法,而不是更簡單的無模型方法,這些方法是明確的試錯學習器,幾乎被視為與規劃相反。 增強式學習系統同時通過反複試驗進行學習,學習環境模型,並使用該模型進行規劃。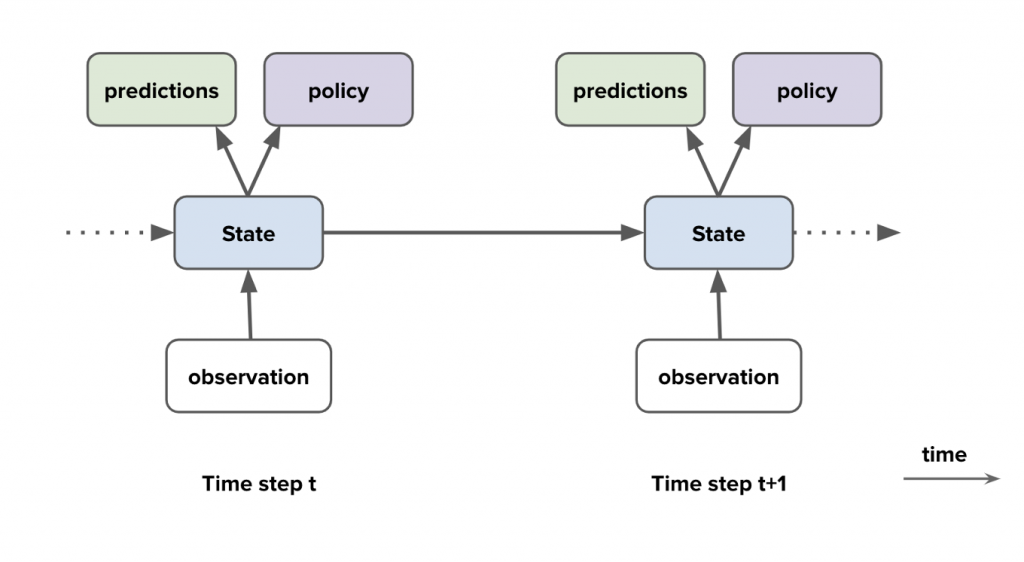
圖片來源:
Agent components
https://storage.googleapis.com/deepmind-media/UCL%20x%20DeepMind%202021/Lecture%201%20-%20introduction.pdf
參考資料:
1. Google Machine Learning
2. Reinforcement Learning An Introduction - second edition (Richard S. Sutton and Andrew G. Barto)


 iThome鐵人賽
iThome鐵人賽