進到AI世界的第四天,經過歷史老師和地理老師摧殘後,終於輪到生物老師來教學啦!
但是你看了一下黑板上的描畫,有的由一堆相連的圈圈組成,像一串葡萄,有些又像是高聳的樹林……欸?怪獸長這樣嗎?
你知道人類在生物分類中所屬的位置嗎?
真核域(Eukarya)>動物界(Animalia)>脊索動物門(Chordata)>哺乳綱(Mammalia)>靈長目(Primate)>人科(Hominidae)>人屬(Homo)>智人(Homo sapiens)
第一眼看上去很複雜,再認真看過了一遍就會發現……還是很複雜。
你可能要問了,我不是來學習機器學習的嗎?怎麼突然教起生物來了?!(國中時被丟棄的回憶突然瘋狂運轉起來)
別擔心,這堂課我們不會用這些,只是如果依照人類假設,未來能夠出現超人工智慧,那這個新出現的物種,要怎麼在生物分類中被定義呢?
這是一個很有趣的問題。因為嚴格來說,AI並沒有實質上的形體,不能算做是「生物」,但是當這個物種有智慧以及情感時,難道還不能算做是生命嗎?
如果要我分的話,我只能勉強在域的部分多加一個「擬生命域」之類的,後面我想了很久還是遲遲沒法下筆。畢竟做為一個在生物領域和資訊領域都不熟悉的人,我不太敢下妄語,以免被圍毆。
不過各位讀者可以留言處留下想法,大家一起來為AI做出一個生物分類,說不定能碰撞出有趣的火花!
前面說了一堆,你可能會問了,「我生物課本都翻了,阿這到底跟生物分類有什麼關係啊?」
就像是我們在Day2 不要以為勇者不用學歷史-簡述AI的發展中提到的,AI、機器學習、深度學習之間的關係是這樣的:
AI>機器學習>深度學習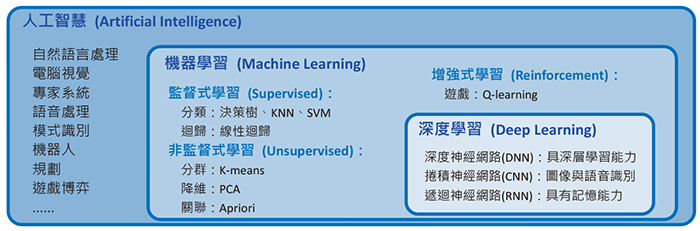
資料來源:中台山月刊249期--科技與生活:人工智慧常用技術簡介──機器學習篇
從圖片中理解會比較清楚,這和生物分類是非常相似的,並且這樣理解也不會將機器學習與深度學習混淆。
那接下來我們就來講講其中比較關鍵的監督式學習、非監督式學習、強化學習中各自的演算法。
顧名思義,就是有人「監督」。我在給機器的每一份資料中都做了標籤,讓他在學習的過程中可以在同樣標籤的資料裡找出相關性並做出預測。
監督式學習最大的缺點就是太過耗費人力,跟Day2提到的專家系統一樣,因為每一筆資料都要先人工看過再給予標籤,所以會非常複雜。
而標籤這件事也成為了他的兩面刃。因為學習過的資料都已經被明確分類過,所以在已知資料的部分,你問的問題他都能夠回準確回答;但在未知資料的預測上就不太理想,而且標籤是人工下的,所以機器在學習的同時,也會一起把人類的偏見學進去。
監督式學習就像城市中溺愛式的家庭(簡稱媽寶),生活中的每一件事情都會有人在一旁教,所以當他在生活中遇到事情的時候,就照著教的做就好了,即使是歧視乞丐這樣的行為。但如果遇到沒被教過的事情,他就會很茫然,不知道如何下手。
下面列出幾個常用的監督式學習演算法:
(在這裡只要先認識他們的名字就好了,之後會有更大的篇幅來聊聊他們的身世)
與監督式學習相反,非監督式學習的方法是不給他任何的標籤,讓他自己從這些資料中摸索出其中隱藏的結構和關聯。
他最大的缺點是正確率方面會差於監督式學習,因為沒有標準答案(標籤),分的不好也不會察覺,而且在分析的時候,很容易過度重視與目標不相關的因素,所以在同樣的資料裡,他出現錯誤的數量會比監督式學習多。
但因為他有自己的分類邏輯,在未知領域的表現頗佳,預測的正確率也會優於監督式學習。
非監督式學習就像一個被遺棄在野外的孤兒,在成長的過程中一切都沒有人教,完全都是由自己摸索,透過觀察來學會處理事情的方法。比如透過分類來知道哪些食物能吃,哪些可能有毒。
即使因為沒人教,所以平時比起監督式學習的小孩容易吃到有毒的食物,但在森林中碰見大家都沒看過的果子時,他可以依靠曾經的經驗來分辨能不能吃,這可比指遵照答案不太會變通的監督式學習小孩好多了。
下面簡單介紹一下常用的演算法:
(在這裡只要先認識他們的名字就好了,之後會有更大的篇幅來聊聊他們的身世)
顧名思義,是介於監督式學習以及非監督式學習之間的方式。操作的方法是給予一些帶標籤的資料,以及大量無標籤的資料,以此來訓練演算法。
這可以省去大量人工的時間,也能更有效率的做機器學習。
這就像是原本居住在城市中的小孩,因為戰亂流落到了野外(好慘),既有著之前學習到的知識,又必須在未知的環境中用過去的知識歸納出經驗。因為已經有基礎的概念,所以能省去他慢慢摸索的時間,也能避免掉許多放錯重點的問題。
半監督式學習有許多種不同的演算法,最經典的方法是自訓練 (Self-training),但因為之後文章不會談到,所以就不多做敘述,有興趣的可以去翻翻資料。
強化學習和以上三種模式不同,採取讓機器和環境互動,並從中獲得正向/負向反饋,從而在過程中累積經驗,做出對達成目標越來越有效率的行動。
強化學習中最重要的就是設定目標以及獎勵機制,如果做了對的事(更接近目標)就給予正向回饋,反之則給予負面回饋,用回報來判定這次行動的好壞,從而進一步優化未來的行動。
這是非常有效的方法,有人說這是最接近人類與自然互動的方式,但是強化學習仍然有缺點。
強化學習需要大量的數據訓練才能獲得良好的性能並於現實世界中應用,但龐大的數據需要花費大量時間和資源來計算。在訓練的過程中,因為每次訓練都會涉及大量隨機性的試驗和錯誤,所以模型在訓練過程中不會是穩步提升的,而是呈現不斷變動的不穩定性,而獎勵機制的設計也是一件困難的事情。
這就像是一個參加比賽的人,目標是得到最高分贏得比賽,而在過程中他透過不斷的參加比賽,從每次的成績中了解到什麼樣的行為可以最有效率的達到贏得比賽這個目標。
Q-學習 (Q-Learning)是強化學習中常用的演算法,但和半監督式學習一樣,因為之後文章不會談到,就不多做敘述了。
深度學習是基於機器學習的一種方法,他是使用人工神經網絡(Artificial Neural Networks),通過多層次的神經網絡來自動地學習數據中的特徵表示,藉由這種方法,可以更高效的解決複雜的任務。
深度學習的核心理念是模擬人類腦神經的傳遞方式,經過這樣多層次的處理,可以學習、處理更加抽象和高層次的特徵,比如圖像識別(從圖像中識別物體或特徵)、語音識別(從語音中識別出言語內容)以及自然語言處理(對文本進行理解和生成)等。
介紹一些常用的方法:
(在這裡只要先認識他們的名字就好了,之後會有更大的篇幅來聊聊他們的身世)
一種基本的前饋神經網絡(資料信息只會向前傳,沒有循環反饋的路徑),由多個隱藏層組成,每個隱藏層包含多個神經元,可以應用於分類和回歸問題。
應用場景:圖像分類、手寫數字識別、聲音識別等。
看完之後是不是覺得明明每個字都認識,但合在一起就不知道是什麼意思了XD
沒關係,今天只要大概認識他們就行了,之後會再用更大的篇章來介紹它們的身世背景。

