LSTM(長短期記憶網絡)是一種特殊類型的循環神經網絡(RNN),專門設計用於解決長序列中的長期依賴問題。傳統的RNN在處理長序列時會遇到梯度消失或梯度爆炸的問題,這使得網絡難以學習和記憶遠距離的依賴關係。LSTM通過引入一種叫做“門”的機制來解決這個問題。
LSTM的組成部分
一個LSTM單元主要由以下幾個部分組成:
LSTM的工作原理
遺忘門: LSTM首先決定要從單元狀態中丟棄哪些信息。這是通過一個sigmoid層完成的,它查看當前輸入和上一個隱藏狀態,並輸出一個在0到1之間的數值給每個在單元狀態中的數字。1表示“完全保留”,0表示“完全丟棄”。
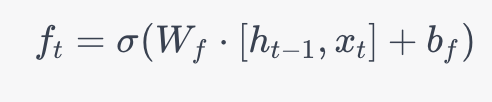
輸入門: LSTM然後決定將哪些新信息存儲在單元狀態中。這分為兩步。首先,一個sigmoid層決定哪些值將更新。然後,一個tanh層創建一個新的候選值向量,可能會添加到狀態中。
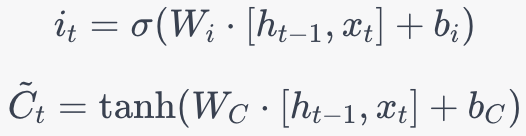
更新單元狀態: 現在,可以使用遺忘門的輸出和輸入門的輸出來更新單元狀態。
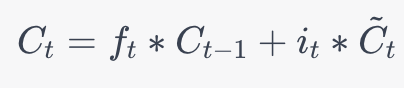
輸出門: 最後,決定輸出什麼值。輸出依賴於單元狀態,但是是一個過濾後的版本。首先,運行一個sigmoid層來決定單元狀態的哪個部分將輸出。然後,將單元狀態通過tanh(將值推到-1和1之間)並將它與sigmoid門的輸出相乘,以便只輸出決定輸出的部分。
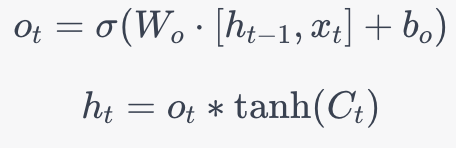
這些步驟共同使LSTM能夠在長序列中有效地學習長期依賴。
GRU(門控遞歸單元,Gated Recurrent Unit)是一種用於遞歸神經網絡(RNN)的特殊類型的激活單元。GRU 是由 Cho 等人在 2014 年提出的,旨在解決傳統 RNN 在處理長序列時面臨的梯度消失和梯度爆炸問題。
GRU 的基本結構包括兩個門:
以下是 GRU 的數學表示:
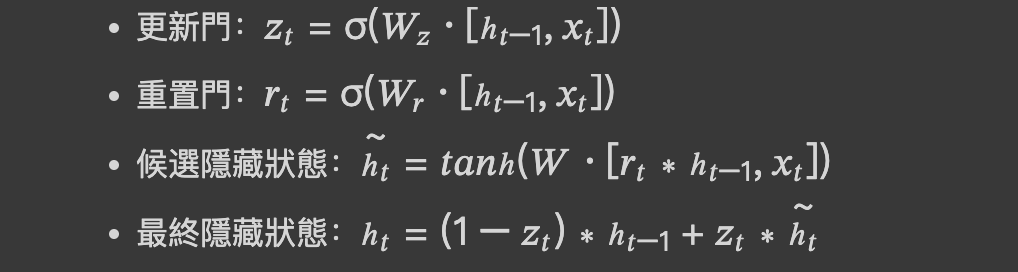
其中,σ 是 Sigmoid 激活函數,tanh 是雙曲正切激活函數,∗ 表示逐元素乘法。
GRU 常用於自然語言處理(NLP)、時間序列分析、語音識別等任務。
與單向 RNN 不同,雙向 RNN 在兩個方向上都有信息流動:一個從輸入到輸出,另一個從輸出到輸入。這使得網絡能夠有更全面的了解上下文信息,通常會產生更好的性能。這種類型的 RNN 常用於自然語言處理(NLP)和語音識別等任務。
注意力機制允許 RNN 專注於輸入序列的特定部分,而不是整個固定大小的上下文。這在機器翻譯或問答系統中特別有用,其中輸入和輸出序列的長度可能會變化。注意力機制通常與 LSTM 或 GRU 結合使用。
1.https://www.kaggle.com/code/hassanamin/time-series-analysis-using-lstm-keras/notebook
我在跑完幾個算法的範例之後,剩下的幾天會專注於建立幾個Github上面的玩具項目。目前希望最少做兩個玩具項目,一個是物件辨識,一個是大模型相關的。
30天之後大概也會每週做一個玩具項目。
大模型相關的也會參考這本書:https://intro-llm.github.io/
大模型的玩具項目,我是希望能觸及到大模型相關的所有知識跟實作。
物件辨識也是希望能做到程式那在手機上聽到訊息後透過鏡頭分辨物體然後判斷熱量或價格這類的。
另外,有時間NLP方面的可能就看 Stanford CS224N: NLP with Deep Learning 補強基礎。
不過目前大概就是以實作玩具以及能拿來面試的項目為主,我自己覺得我一次能做好一件事就很好了。

