Transformer 是一種深度學習模型架構,專為處理序列數據(如文本或語音)而設計。它於 2017 年由 Vaswani 等人在論文 "Attention Is All You Need" 中首次提出,並迅速成為自然語言處理(NLP)領域的主流模型。
下面的影片在實際實做某些概念時可能方法會有些不同,請辯證著看。
下面是幼齡向但我覺得講的最好懂的Transformer解說,之後就算有小學或國中年紀的人自己修改出新算法,我也不意外 哈哈。
Stanford CS224N NLP with Deep Learning | 2023 | Lecture 8 - Self-Attention and Transformers
講解的感覺才研一研二,大概我眼花

Stanford CS224N NLP with Deep Learning Playlist
台大李宏毅老師的transformer相關影片:
【機器學習2021】自注意力機制 (Self-attention) (上)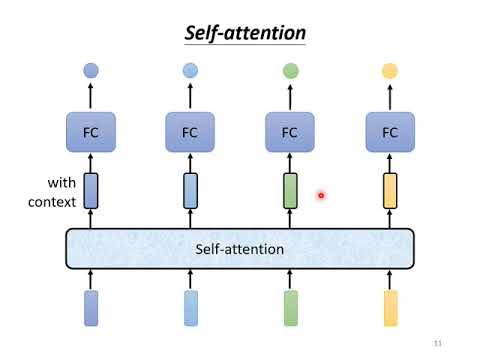
【機器學習2021】自注意力機制 (Self-attention) (下)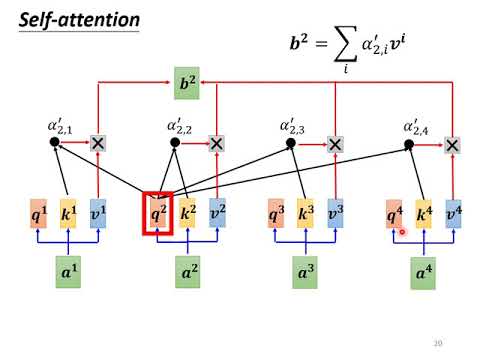
【機器學習2021】Transformer (上)
【機器學習2021】Transformer (下)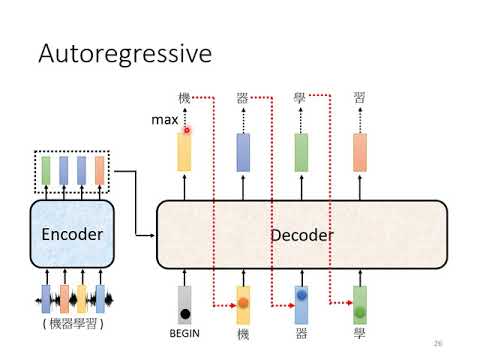
以下是 Transformer 的主要特點和組件:
自注意力機制 (Self-Attention Mechanism)
允許模型在不同位置的輸入序列中關注(或 "注意")不同的部分。
這意味著模型可以根據上下文動態地重新加權其輸入特徵。
多頭注意力 (Multi-Head Attention)
Transformer 使用多個自注意力層(稱為 "頭")並行運作,使模型能夠同時關注輸入序列的多個不同部分。
這些 "頭" 的輸出會被組合起來,然後通過一個線性層。
位置編碼 (Positional Encoding)
由於 Transformer 沒有內置的序列順序感知能力(如 RNN 或 LSTM),所以它使用位置編碼來給予序列中的每個元素一個位置信息。
這些編碼是加到輸入嵌入中的,使模型能夠考慮元素的順序。
堆疊的編碼器和解碼器層 (Stacked Encoder and Decoder Layers)
Transformer 由多個編碼器和解碼器層堆疊而成。
每個編碼器層包含一個多頭注意力子層和一個前饋神經網絡子層。
解碼器還包含一個額外的多頭注意力子層,用於關注編碼器的輸出。
殘差連接 (Residual Connections)
幫助避免深度網絡中的梯度消失問題。
每個子層的輸出都會加上其輸入,然後通過層正規化。
前饋神經網絡 (Feed-Forward Neural Networks)
在每個編碼器和解碼器層中都有一個前饋神經網絡。
這些網絡在每個位置都獨立且相同地應用於輸入。
Transformer 架構的這些特點使其在許多 NLP 任務中都表現出色,特別是在大量數據上。此外,許多現代的 NLP 模型,如 BERT、GPT 和 T5,都是基於 Transformer 架構的。
明天將會是從零開始寫 transformer 的blog 跟程式碼,這部分我大概今天寫不完,這些內容對之後可能要自己改或寫出個新算法可能有點幫助,也不知道算法模塊的自動搭建和輔助設計跟測試的 python 套件會不會有人去寫就是了
哈哈。
另外還有 transformer相關預訓練模型的直接使用, 微調, 跟訓練的相關內容也會在明天呈現。
之後就是兩個玩具專案(快的話三個)的實作內容。

