在現代資料棧(Modern Data Stack,以下簡稱MDS)中,資料通常會被分成三大層:
通常談到資料倉儲和資料模型的時候,大家第一個聯想到的是集市層的資料設計。雖然在特定情況下,DV也可以在集市層應用到,但是最能體現DV設計優勢的還是整合層。這主要是因為在複雜性高的環境內,除了調整格式、排錯、重複資料刪除以外,整合層也需要起到資料合併(Data Merging)與鏈接的作用。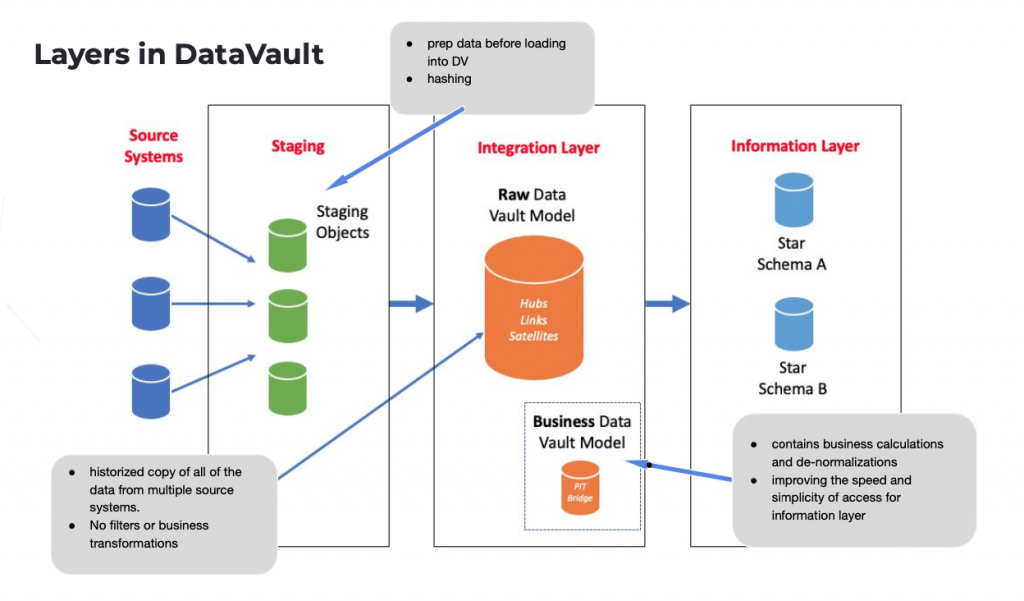
相對的,如果用在集市層的話,DV多鏈接的設計會變得非常不方便。想要做個簡單的屬性查照也會需要多層的SQL JOIN,而你的用戶體驗也是可想而知的差 (`□′)╯┴┴
例如,你的公司有兩個對應客戶資料的作業系統A、B。系統A是客服系統,儲存了各種客戶關係管理(Customer Relationship Management)的資料。系統B是收費系統,維持了客戶付款紀錄與收入計費的資料。
在屬性完全沒有重複的狀況下,在整合層其實就可以直接可以用一個表來完成資料合併。
但如果兩個系統有許多重複屬性,而資料也不一定是同步或者同等的呢?
雖然可以用前綴(Prefix)的方式硬是將兩個對應資料合併起來,譬如system_a_name、system_b_name,但當屬性或者原資料表變多的時候,你的表列就會變得非常複雜。
另外一個辦法是直接在整合層加入某種程度的業務邏輯,而直接選一個值。這個雖然實現上簡單(e.g. coalesce(a.name, b.name)),但實踐上不一定可行。譬如說,在你的整合層你決定以系統A為主,然後集市層直接沿用。如果有使用者想要看到系統B的資料,那你就會需要特地為了這列資料新開一個管道,把資料從原始層帶到集市層。這樣下去很容易會把你的整合層搞的很亂。
這個情況下,DV的設計就變得非常方便。可以在整合層內保有所有的信息,但同時簡單化資料的對照與提取。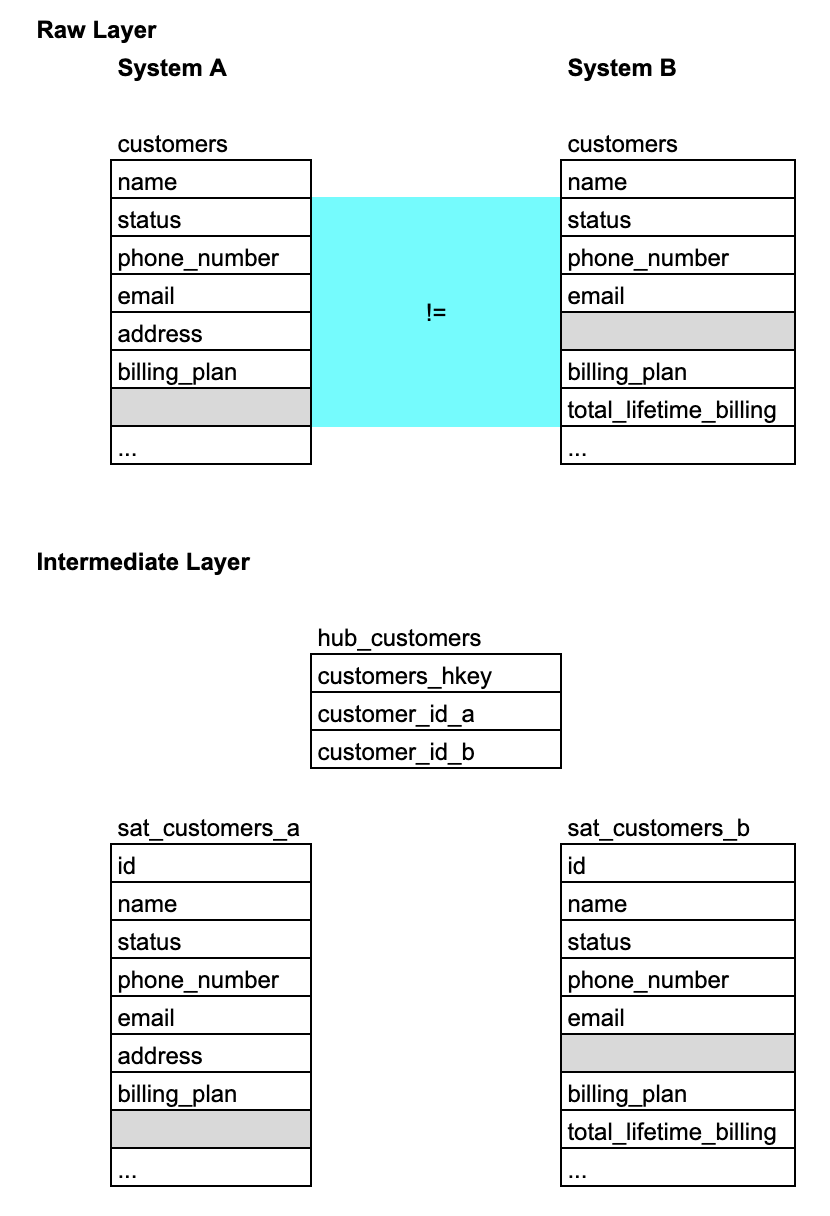
理論部分(真的)結束了!下一篇開始介紹如何用dbt簡單實現DV實體,與一些常用的組件擴充。

