今天我們要用python的sklearn來實作K-means,首先我們先利用python的random套件來隨機產生資料點,筆者這邊隨機產生了100個x座標介於0到100且y座標介於0到100的資料點。
import random
coordinates = []
for _ in range(100):
coordinates.append([random.randint(0, 100), random.randint(0, 100)])

下一步我們直接使用skleanr.cluster裡的KMeans函式來建構K-means模型,這邊選擇的分群為3,讀者們可以調整看看分群的數量,看看有什麼樣不同的結果。建構完成過後,就可以直接將先前產生的隨機點放進模型去做訓練。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)
kmeans.fit(coordinates)
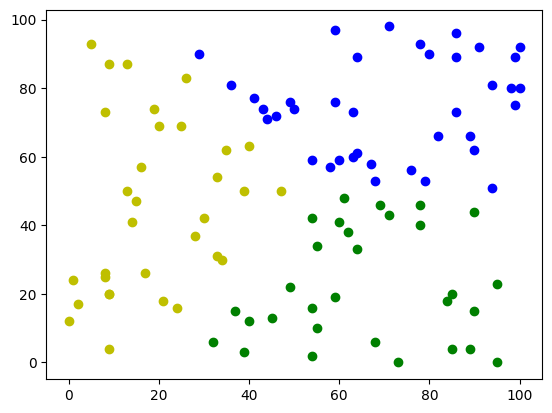
訓練完成過後可以使用predict函式來對資料預測是哪一個分群或是在訓練時使用fit_predict函式,可以訓練後直接回傳分群結果。筆者這邊利用了python的matplotlib.pyplot對預測結果做圖,直接圖像化來清楚的看見分群結果。
import matplotlib.pyplot as plt
predictions = kmeans.predict(coordinates)
for i, prediction in enumerate(predictions):
if (prediction == 1):
plt.plot(coordinates[i][0], coordinates[i][1], "bo")
elif (prediction == 2):
plt.plot(coordinates[i][0], coordinates[i][1], "go")
else:
plt.plot(coordinates[i][0], coordinates[i][1], "yo")
plt.show()
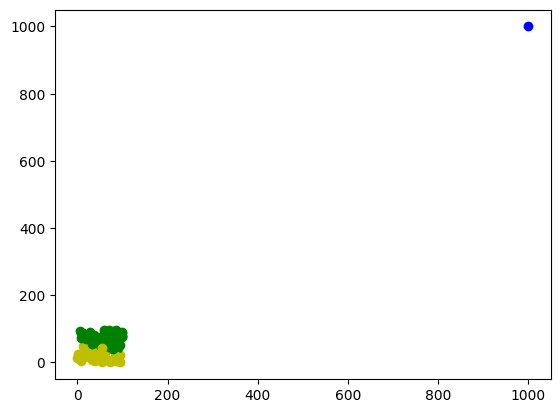
從結果來看,好像我們做出來的結果還不錯,但是這其實是建立在我們的資料沒有離群值(outlier)的情況之下。以下的例子,筆者將一點離群值加入coordinates之中再重新訓練一次模型,可以看到最後得出來的結果好像跟我們期望的就有點差別了。所以資料預處理其實是很重要的,在訓練模型前,我們應該先檢查資料的可靠度,對資料進行刪減過後再做訓練。
coordinates.append([1000, 1000])
kmeans = KMeans(n_clusters = 3)
predictions = kmeans.fit_predict(coordinates)
for i, prediction in enumerate(predictions):
if (prediction == 1):
plt.plot(coordinates[i][0], coordinates[i][1], "bo")
elif (prediction == 2):
plt.plot(coordinates[i][0], coordinates[i][1], "go")
else:
plt.plot(coordinates[i][0], coordinates[i][1], "yo")
plt.show()