大家週三好,嗚嗚這週要上六天班好漫長,今天我們要繼續 SRE 方法論的第四條:緊急事件處理,這裡是今天讀的原文出處:Introduction,話不多說,我們開始囉!
以前常常聽到「我們家的系統是高可用性,有 5 個 9 那麼多!」,一直都不太知道這個數字怎麼來的,還有可用性的定義到底是什麼?今天藉由 Google SRE Book 來帶我們看看吧!
書上沒有直接定義高可用性,所以借用一下維基百科的定義:
高可用性(英語:high availability,縮寫為 HA),指系統無中斷地執行其功能的能力,代表系統的可用性程度。是進行系統設計時的準則之一。高可用性系統與構成該系統的各個組件相比可以更長時間運行。
評價一個系統是否是「高可用性」,我們可以從 MTTR 知道一些端倪,下面就來說說書裡提到的兩個專有名詞:
如果我們做一個時間序的圖,會長成下面這個樣子:
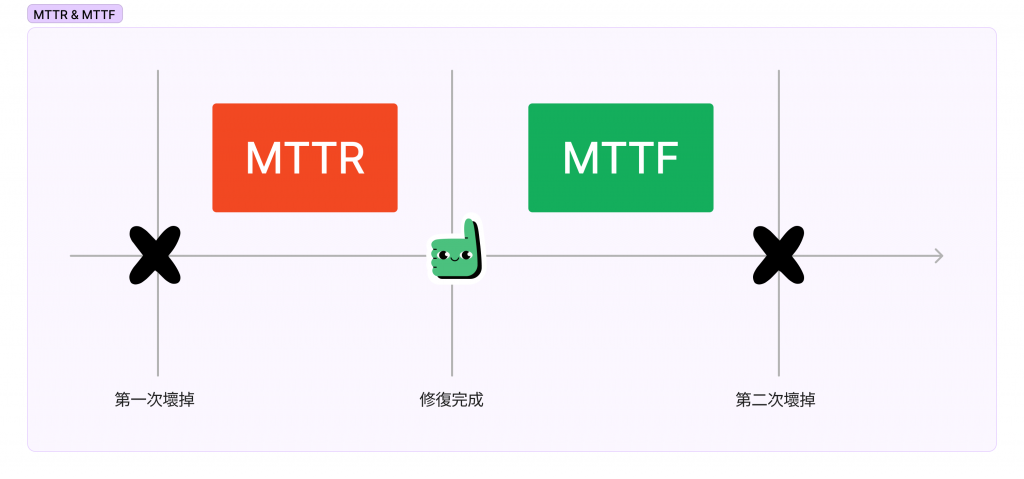
那麼如何計算可用性呢?
可用率(%)=(實際運行時間 / 預定運行時間)× 100%
所以若像上面提到的 5 個 9,那就是在一年 525,600 分鐘中,只能也 5 分鐘的停機時間。(好驚人!
另外書中提到 自動修復 > 人工干預 的概念,但倘若真的需要人工干預,建立「維運手冊」則是一個很好控制修復時間的手段:
通過事先預案並且將最佳方法記錄在「運維手冊(playbook)」上通常可以使MTTR 降低3倍以上。
上面提過高可用性的定義,那我們先來看看高可靠性的定義:
高可靠性:一個服務連續無故障運行的時間,無故障運行的時間越長,可靠性就越高。
根據這個定義,我們可以用這個公式來衡量系統可不可靠:
故障率(%)= 故障次數 / 單位時間(即小時、週、月等)× 100%
可以看得出來高可用性跟高可靠性是有些相關性存在的,下面來腦洞思考一下會發生什麼事:
OS:如果一個系統可用性低,好像很難評估他是否高可靠(畢竟常常不能用)。
好拉!這就是今天思考題的部分拉!不知道大家是怎麼看兩個指標的呢?
今天了解了緊急事件的名詞與流程,也提到了維運手冊的部分。我也十分認同建立維運手冊的重要性,除了可以讓每次發生意外時,降低緊張感,也可以模糊化特定角色的重要性(講白話就是我就算請假,若剛好有意外發生,職代也可以好好地將維運工作完成!),明天的內容是「變更管理」!那麼就明天見拉!掰噗!

