在前一天跟大家分享了 Data pipeline 的種類,在每種 Data pipeline 當中多半都有資料處理的步驟。實際上在各種資料應用的場景,從資料分析到模型訓練,都需要高品質的資料處理。今天來跟大家分享常會使用到的資料處理方式。
我們常常聽到 Garbage in Garbage out 狀況。我們做出的決策如果是建立在不好的資料品質上,決策的,同樣的在機器學習以及AI的訓練當中,資料的品質是非常的重要。資料如果沒有經過清洗甚至會讓團隊在後續流程花上許多不必要的時間。
資料的產生過程當中往往會伴隨著許多重複紀錄的資訊,需要將重複資料刪除。
在資料集當中常會碰到一些遺失資料的情況,此時就要針對這些情形作進一步的處理,處理遺失資料常會使用的一些方法:
有網友分享了資料處理的一些想法和步驟如下圖,如果遇到相關情形可以參考。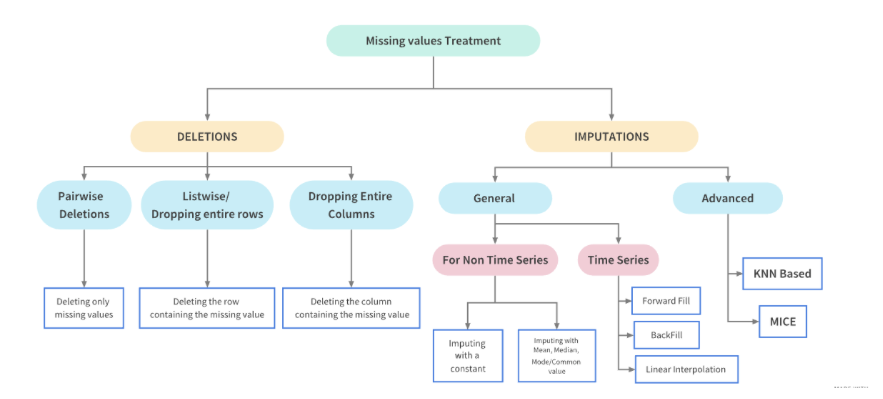
圖片出處:https://www.kaggle.com/code/parulpandey/a-guide-to-handling-missing-values-in-python/notebook
儘管資料沒有遺失,但是在資料當中也常會出現異常的狀況。需要找出異常的值並將其進行轉換。異常的直我們稱之為 outlier我們可以透過幾種方式尋找出異常值。
在原始資料(Raw Data)到實際使用的資料往往都會需要經過一些轉換,有時候是單純的格式的轉換,數值的轉換。另外也常會遇到的情況是把某一類型的資料定義成單一數值,如此進行資料的分類轉換。幫助資料的使用者能夠按照期望的格式及值進行後續的分析或運作。
資料使用者也常會需要整合不同資料源之間的資料,藉此整合出最適合專案最適合的資料集。這時就會需要進行 Data Integration。在不同類型不同結構的資料源之間做整合,是一件特別有挑戰的任務,會需要用到資料連結(Record Linkage)以及資料融合(Data Fusion)相關技術
在使用資料的時候會有資料使用者期望的資料格式,透過資料的正規化將資料縮放到某一個範圍之內,例如 0 ~ 1 或是 0 ~ -1,以利於後續使用。常見的正規化有 min-max normalization、 z-score normalization 以及 decimal scaling。可以針對適用的場景進行資料的正規化。
Reference
https://tw.alphacamp.co/blog/data-processing-and-data-cleaning
https://www.geeksforgeeks.org/data-preprocessing-in-data-mining/

