我們這幾天的練習下來,可以知道beautifulsoup擁有大量、簡單且方便的搜尋方法,但因為request的特性關係,無法爬取渲染過後的內容。selenium透過模擬使用者開啟瀏覽器的方式,可以搜尋到渲染後的網頁原始碼,但是搜尋的方法少,也因為需要開啟driver的方式,所以速度放慢了不少。
再selenium我們得知有一個方法可以得到網頁的source
source = driver.page_source
诶!!! source?
沒錯就是那個suorce,相當於整個網頁的HTML的那個source,那我們不就可以把整個網頁透過beautifulsoup執行,來達到更方便的效果!!
沒錯,這邊我們有請萬年冤大頭,還是那個booking
from bs4 import BeautifulSoup
import requests
content = requests.get("https://www.booking.com/.......").text
soup = BeautifulSoup(content, 'html.parser')
all_titles = soup.find_all("div", attrs={"data-testid":"title"})
for title in all_titles:
print(title.text)

這邊可以看到,其實這一段程式碼是不會爬取到任何資料的,那我們結合selenium來看看會發生甚麼事情
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
url = "https://www.booking.com/searchresults.zh-tw.html?ss=台北&checkin=2023-10-10&checkout=2023-10-12&group_adults=2&no_rooms=1&group_children=0"
driver = webdriver.Edge()
driver.get(url)
source = driver.page_source
#content = requests.get(url).text
soup = BeautifulSoup(source, 'html.parser')
all_titles = soup.find_all("div",attrs={"data-testid":"title"})
for title in all_titles:
print(title.text)
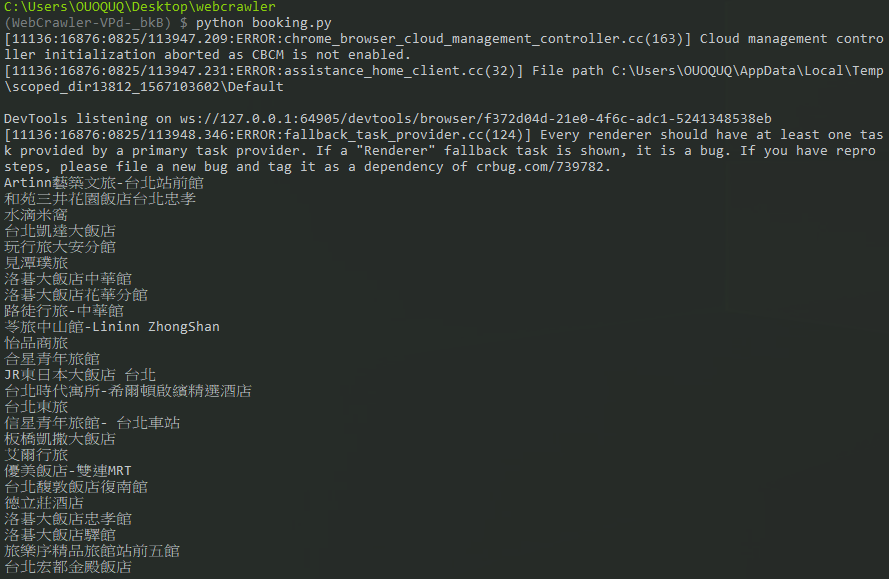
沒錯,就是這麼好用,那麼我們如果想要得東西不只是這些,連下一頁我都想要,這樣呢?那就樣有請selenium,前面我們有講到他具有click的方法,那我們就來試試吧
from selenium.webdriver.common.by import By
#由於要尋找元素,所以得使用by
next = driver.find_element(By.CSS_SELECTOR, 'div[class="b16a89683f cab1524053"]')
#老樣子先去網站找到div的class再拿來這裡使用
next_button = next.find_element(By.TAG_NAME, 'button')
#由於無法直接找到button所以先找到button上層的div再透過tag抓到button
#這邊再一次獲取source,以及title
source = driver.page_source
soup = BeautifulSoup(source, 'html.parser')
all_titles = soup.find_all("div",attrs={"data-testid":"title"})
for title in all_titles:
print(title.text)
然後來試試看吧...
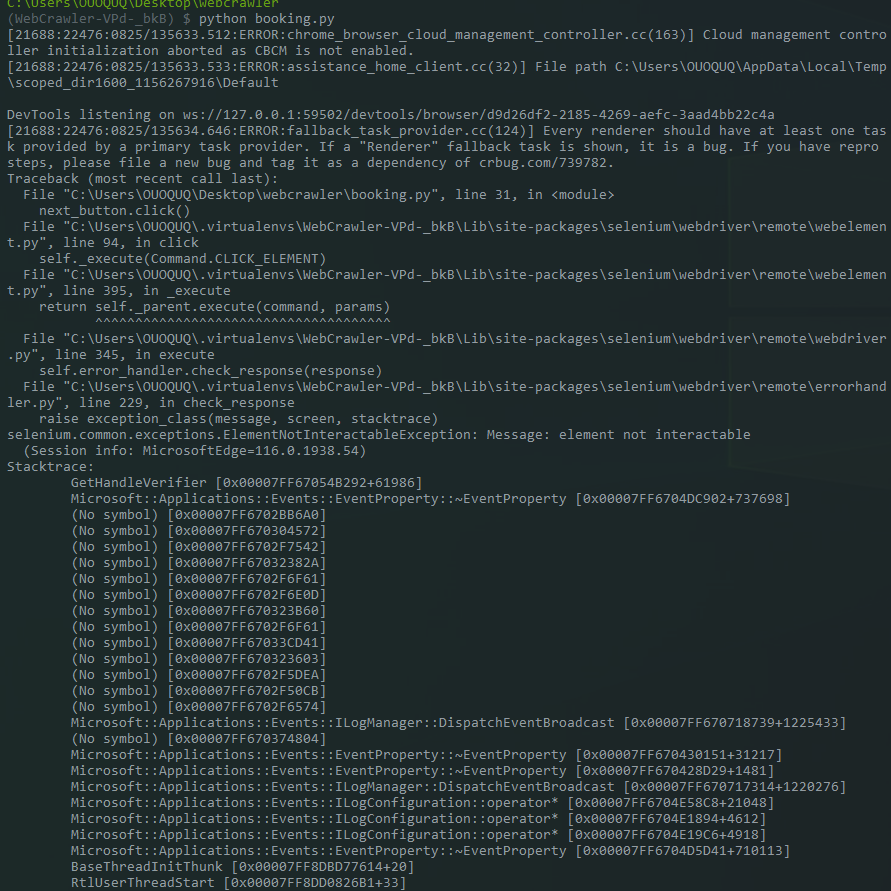
诶? 出錯了?
這邊訊息出現了driver無法點擊next_button,那我們來除錯一下,先把他註解一下
# next_button.click()
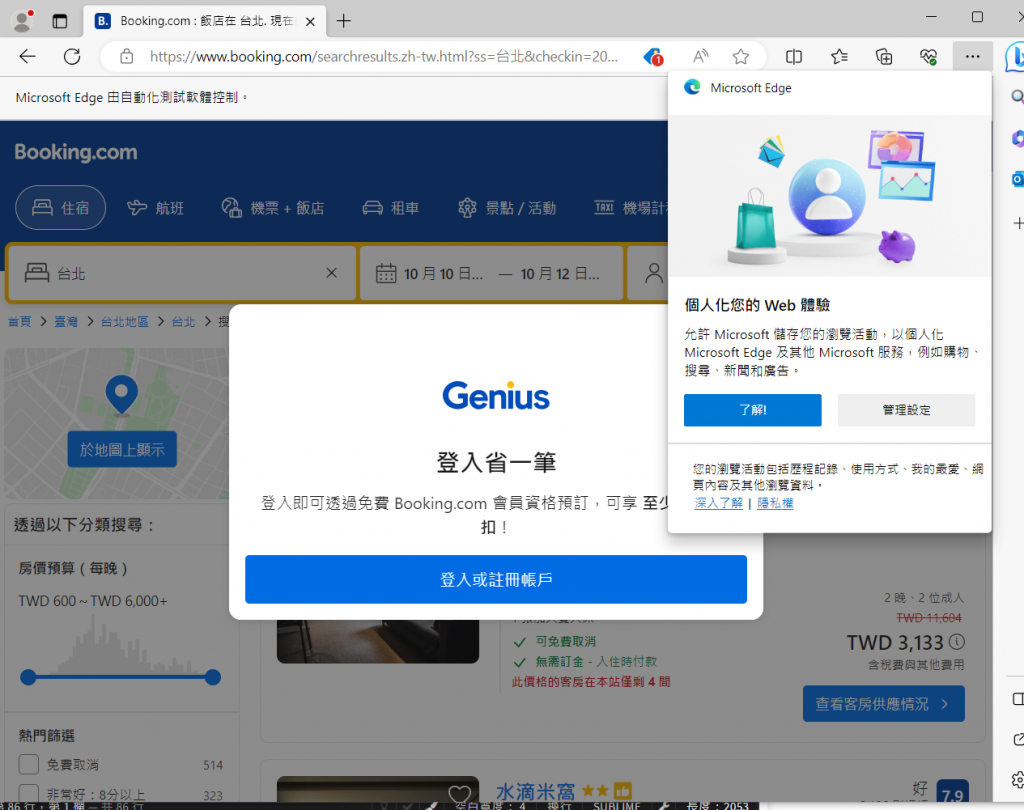
可以看到成功開啟後程式不會崩潰,難道說這顆==下一頁==的按鈕有我們看不見的東西保護他!?還真的有,但是我們看的見,而且他就在我們眼前,這個大大的請你登入的畫面,dirver是模擬用戶使用,所以當每個用戶第一次開啟這個介面的時候,都會出現這個畫面,可以發現我們並沒有辦法跳過這個畫面直接點擊到button,那driver也沒有辦法,所以我們就衍伸出兩個解決方案
刷新頁面讓網站認為我們已經來過了
點擊關閉再點擊button
那麼往我們下一篇就來試試看ㄅㄚ


 iThome鐵人賽
iThome鐵人賽