今天我們會介紹Flow的內容,包含:Flow的架構、Flow的種類、及Flow的應用。P.S. 沒寫公式這篇超難講,難度超高啊啊啊
我們先回顧一下之前提過的內容;例如,VAE和GAN,同樣也是生成式模型的架構,三者在架構上有何差異,如下圖。
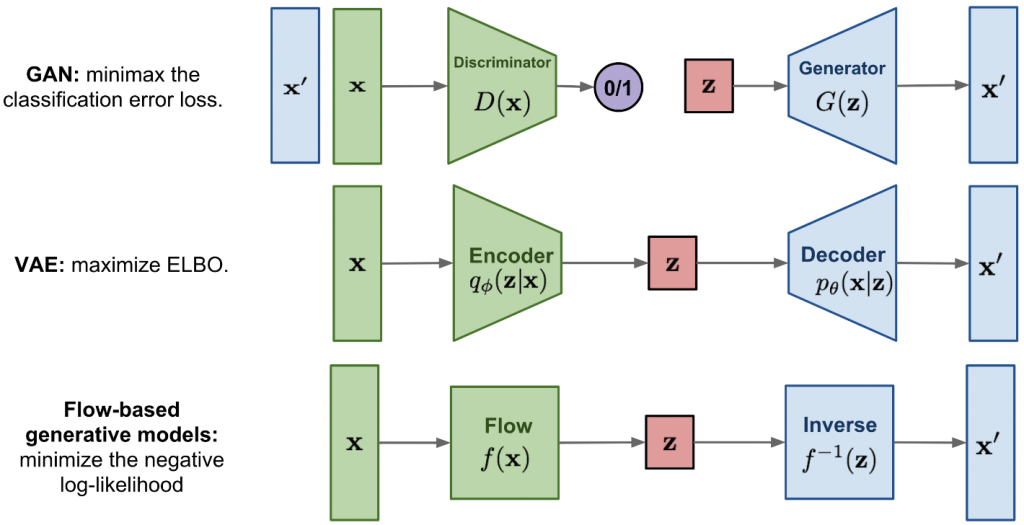
列表如下:
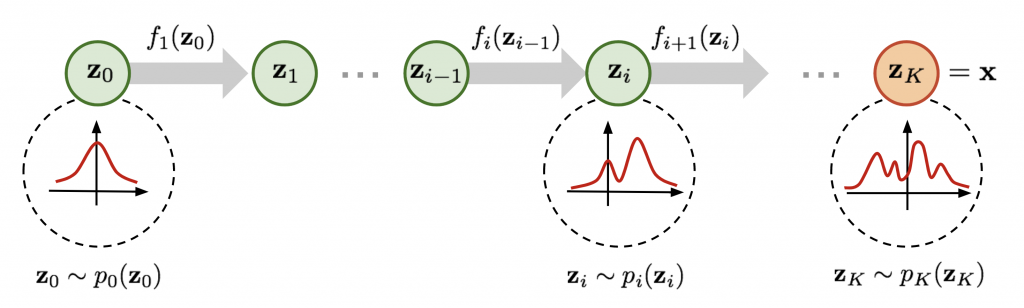
有鑒於Flow架構的基本概念包含:Jacobian matrix、Determinant、及Change of Variable Theorem,簡單來說,在將流正規化 ( Normalizing Flows ) 的時候,透過這三個概念,就可以推導及簡化機率密度的函數,他這個作法是將一個個高斯分佈做疊加,達到模擬對數似然函數的目的,如下圖所示。
關於Flow的變體有很多種類,但不外乎是基於Jacobian matrix的性質;例如,Nonlinear Independent Components Estimation ( NICE )、Real Non-Volume Preserving ( Real NVP )、Generative Flow ( Glow ),也有結合auto regressive的Masked autoregressive flow ( MAF ) 等等。
原則上因為是生成模型,所以很適合作為建模任務使用;例如,語音生成、圖像生成、視頻合成,甚至是圖像壓縮及異常檢測都有其應用。
今天我們回顧了Flow的架構,它是一個直接模擬數據分佈的模型,其性質可以很好的找到反函數,明天會介紹Diffusion的內容,明天見!


 iThome鐵人賽
iThome鐵人賽