對我來說 Prometheus 可以說是為 Grafana 注入靈魂的要角之一,並且是在 Kuberentes 上建立監控的首要基礎,少了如 CPU、Memory 等基本的監控指標,對開發人員來說有如瞎子摸象般的不便,更談何生產出高水準的產品呢?接下來我們就從 Prometheus 來開始認識這對哥倆好。

官方在官網上對其的自述是:
From metrics to insight. Power your metrics and alerting with a leading open-source monitoring solution.
從指標到洞察,藉由一個處於領先地位的開源監控解決方案強化你的指標和告警。
Prometheus 是一款以時序資料庫(Time Series Database)為基礎的開源監控告警系統。每當提及 Prometheus 自然就會聯想到 SoundCloud,一個熱門線上音樂分享平台,可以理解成分享音樂版的 Youtube。隨著 SoundCloud 在微服務架構的發展,所衍生出的複雜度使傳統監控系統,如 Graphite 和 StateD 開始無法滿足需求。
因此,他們於 2012 年著手打造一款全新的監控系統,就是我們都耳熟能詳的「Prometheus」。Prometheus 的作者 Matt T. Proud,在 2012 年加入 SoundCloud 之前,就一直任職於 Google,他從 Google 的叢集管理器 Borg(Kubernetes 的前身)和監控系統 Borgmon 中取得開發 Prometheus 的靈感,並且都由 Go 語言寫成。
不可否認,Prometheus 作為專門針對微服務架構的監控系統解決方案,與容器技術有著緊密的連結。2015 年,為了統一雲原生的接口與相關標準,開發社群成立了隸屬於 Linux 基金會的雲原生計算基金會(CNCF,Cloud Native Computing Foundation)。在同年,Prometheus 被公之於眾,與 CNCF 的理念高度契合。不久之後,於 2016 年,它緊隨 Kubernetes 之後,成為 CNCF 的第二個孵化項目,同年6月正式釋出1.0版本。
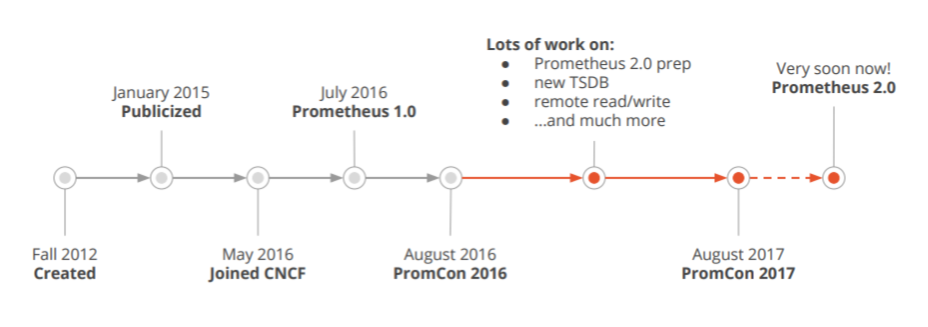
而 Prometheus 得益於廣大社群幫助,持續以高度活躍的速度成長著, 2017 年底釋出了基於全新儲存層的2.0版本,最終在 2018年8月9日 CNCF 在年度 PromCon 上宣佈:Prometheus 是繼Kubernetes 之後的第二個從 CNCF「畢業」的專案。
在 SoundCloud 的官方部落格中,有一篇關於他們爲什麼需要新開發一個監控系統的文章 Monitoring at SoundCloud,在這篇文章中,他們介紹到他們需要的監控系統必須滿足下面四個特性:
事實上,多維度數據模型與強大的查詢語言恰恰是時序數據庫所必需的。因此,Prometheus 不只是單純的監控系統,它同時也具備了時序數據庫的身份。可能你會問,為何 Prometheus 不選擇利用現有的時序數據庫作為其後端儲存?這背後的原因是 SoundCloud 不只追求監控系統具有時序數據庫的功能,更重視其部署和維護的便利性。
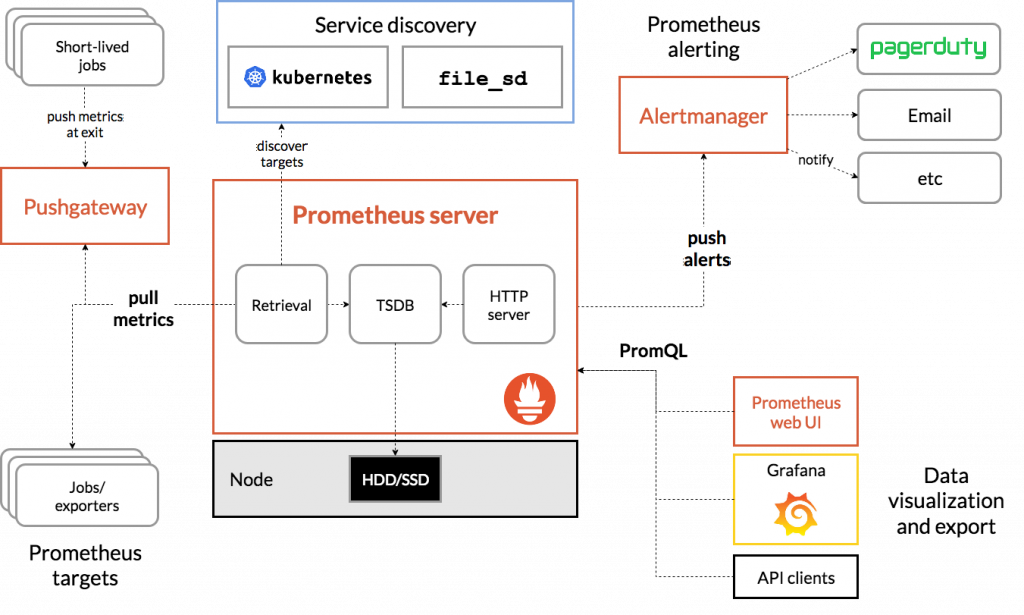
Prometheus 透過其獨特的服務發現機制來識別各式目標。這些目標可能是長期或短期運行的工作,甚至是透過 Exporter 進行監控的第三方應用程式。它將擷取到的數據資料儲存下來,並可以透過 PromQL 語法在儀表板或其他視覺化系統中進行查詢。此外,當出現異常情況時, Prometheus 也能向 Alertmanager 傳遞告警,進而透過網頁通知、電子郵件、即時訊息等方式告知使用者。
從上述描述中,我們可以明確地看到,Prometheus 不單只是一個時序數據庫,它在其整體生態系統中還擔任了完整的監控功能。選擇時序數據庫時,我們通常會基於多維面向來評估,如寬列儲存、SQL 式查詢支援、水平伸縮性、讀寫分離和高效率等。而在監控系統架構的部分,除了這些基礎評估因素外,更需要考慮如何減少元件和服務來降低整體成本和系統複雜度,以及如何有效地進行水平擴展。基於上述多項考量,可以發現結構更簡潔的 Prometheus 以拉模式(Pull Mode)為主要收集模式,達到最初的目的。
而Prometheus主要由六個核心模組構成:
Prometheus 雖具有多項優點,但也有其局限性,主要表現在以下幾個方面:
透過這篇文章,我們對 Prometheus 獲得了一些基礎的認識。在 Prometheus 的領域中,所需的知識範疇確實相當廣泛,涵蓋了容器、後端、微服務、網路、資料庫、監控等各種面向。建立這些基礎知識無疑是十分重要的。我猜許多人跟我一樣,在第一次遇見由前人建立的基於 Prometheus 的監控系統時,都會感到有些手足無措,知其然卻不知其所以然。這樣的狀態很容易讓人陷入被動,不知如何進一步擴展應用,或在遇到問題時如何有效地進行維護。希望這系列文章能助各位深化對Prometheus的了解,從而更加得心應手地運用和維護它。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day10
References
How relabeling in Prometheus works | Grafana Labs
Grafana 系列文章(十五):Exemplars - 东风微鸣 - 博客园
終於有人把Prometheus入門講明白了 | 留言送書_osc_b6tyukpz - MdEditor

