昨天我們介紹了什麼是 SQL 的索引 (Index),今天我們就分別來看看 Postgresql 分別提供給我們什麼類型的索引
PostgreSQL 提供了幾種索引型別:B-tree,Hash,GiST,SP-GiST,GIN 和 BRIN。每種索引型別依適合類型的查詢使用不同的演算法
預設情況下, CREATE INDEX 指令會建立適合最常見情況的 B-tree 索引
-- 本篇主要的篇幅會在說明 B-tree 是什麼
B-tree 索引: 其中 B-tree 中的 B 代表 Balance,可以處理為某種排序的資料比較和範圍查詢。特別是,只要使用以下運算子之一進行比較時,PostgreSQL 查詢計劃程序就會考慮使用 B-tree 索引
先來說明一下什麼是 B-tree
是一種在電腦科學自平衡的樹,能夠保持資料有序。
這種資料結構能夠讓尋找數據、順序訪問、插入數據及刪除的動作,都在對數時間內完成
總而言之他就是一種資料結構
下面這是一個簡易的 B-tree,這顆樹上總共有 8 筆資料(id = 1 ~ id = 8)
就是下圖中最紅色框框中 0001 ~ 0008 (你可以想像成 8 片葉子)
其他的部分都只是樹上的節點 node,並且每個 node 都會有指針(可以想成他會記住下一個節點的位址),形成一個鏈表,以便於進行範圍查詢,並用於指導查詢到達正確的葉子節點

這邊我們來假設幾種情況,看看 B-tree 是如何運作的
指針 指向,最後的葉子節點 (id = 4)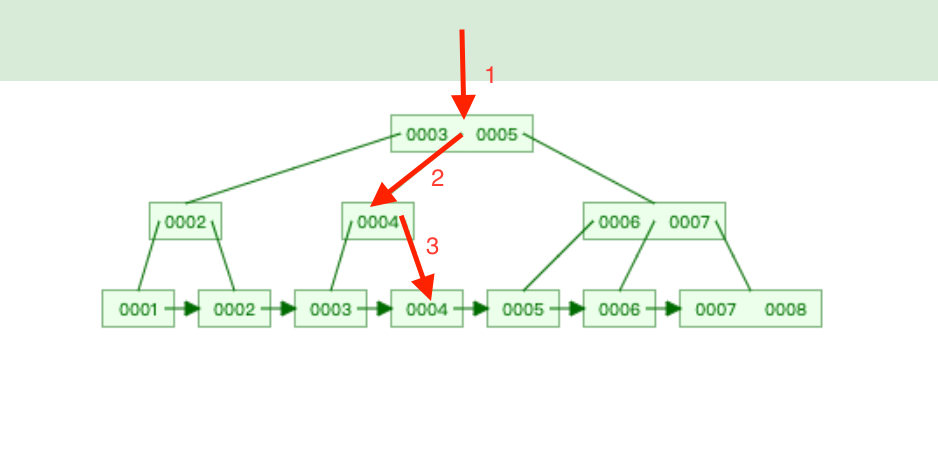
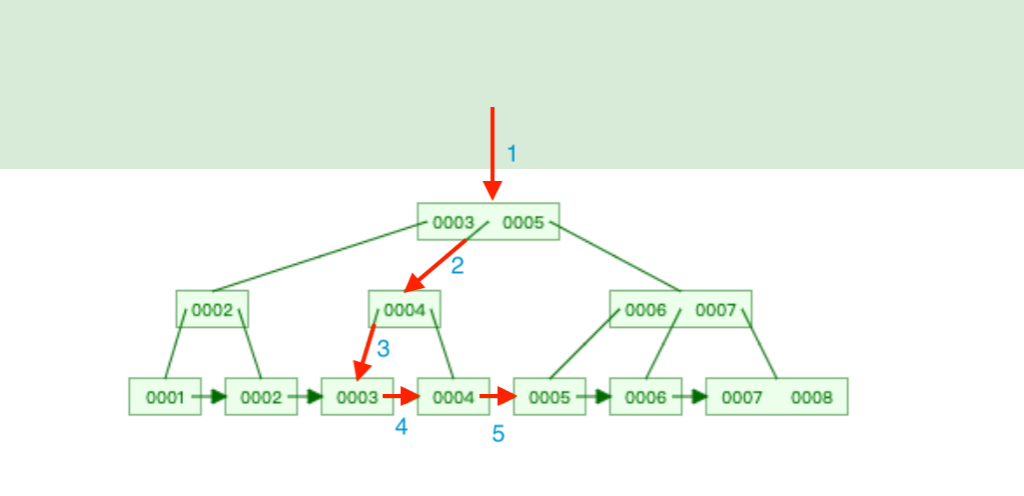
-- 假設要幫 users table 中的 column (name) 建立 B-tree 索引
CREATE INDEX idx_users_name ON users (name);
Hash 索引適用於等值查詢。將每個唯一的鍵值 (key-value)映射到一個特定的位置。但是,Hash 索引不支持範圍查詢
但是假設你的查詢主要是基於等值查詢,例如 WHERE column_name = 'value',那麼 Hash 索引可能會很有用。
舉個實際的例子:
假設我們有一個使用 Hash 索引的 users 資料表,鍵值 (key-value) 是用戶的 id (user_id)
CREATE INDEX idx_users_id ON users USING HASH (id);
剩下的索引類型筆者也很少用到,所以就大致說明
GIN 索引適合於包含多個元素的列,例如全文檢索
使用情境:
假設我們有一個部落格平台,其中有一個 posts 資料表,儲存了所有的文章內容
如果我們想要快速搜索包含特定關鍵字的文章,比如說,我們想找到所有包含 "PostgreSQL" 這個關鍵字的文章
我們就會需要用到 GIN 索引
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR(255),
content TEXT
);
-- 創建 index
---to_tsvector('english', content) 會將 content 列的文本轉換成一個 tsvector 對象,用於全文搜索
CREATE INDEX idx_posts_content ON posts USING gin(to_tsvector('english', content));
使用全文索引進行搜索:
-- @@ 是一個運算子,用於比較 tsvector 和 tsquery 類型的對象 這個運算子主要用於全文索引查詢中
SELECT title, content
FROM posts
WHERE to_tsvector('english', content) @@ to_tsquery('english', 'PostgreSQL');
CREATE INDEX index_name ON table_name USING gin (column_name);
SP-GiST 索引適用於非平衡數據結構,如 IP 地址、多邊形等,特別適用於分區數據。這類索引允許開發者對非常大的數據集進行有效的查詢。
假設我們有一個 locations 資料表,其中儲存了地點的經緯度資訊。如果我們想要快速找到某個區域內的所有地點,SP-GiST 索引會非常有用。
CREATE TABLE locations (
id SERIAL PRIMARY KEY,
latitude DOUBLE PRECISION,
longitude DOUBLE PRECISION
);
-- 創建 SP-GiST 索引
CREATE INDEX idx_locations_lat_long ON locations USING spgist (POINT(latitude, longitude));
使用 SP-GiST 索引進行搜索:
SELECT *
FROM locations
WHERE POINT(latitude, longitude) @> POINT(25.0, 121.0);
CREATE INDEX index_name ON table_name USING spgist (column_name);
GiST 索引是一種用於多種類型的搜索樹,非常適合用於幾何和空間數據結構,例如,範圍查詢和最近鄰查詢。
假設我們有一個 geolocations 資料表,其中儲存了地理位置資訊。如果我們想要快速找到距離某點最近的地點,GiST 索引就會派上用場。
CREATE TABLE geolocations (
id SERIAL PRIMARY KEY,
location GEOMETRY
);
-- 創建 GiST 索引
CREATE INDEX idx_geolocations_location ON geolocations USING gist (location);
使用 GiST 索引進行搜索:
SELECT *
FROM geolocations
WHERE location <-> 'POINT(25.0 121.0)' < 0.1;
CREATE INDEX index_name ON table_name USING gist (column_name);
BRIN 索引適合於大型且自然排序的數據表,例如時間戳。BRIN 索引將表中連續的區塊映射到索引條目,非常節省空間。
假設我們有一個 events 資料表,其中儲存了事件的時間戳。如果我們想要快速查找某個時間範圍內的所有事件,BRIN 索引會很有幫助。
CREATE TABLE events (
id SERIAL PRIMARY KEY,
event_time TIMESTAMPTZ
);
-- 創建 BRIN 索引
CREATE INDEX idx_events_time ON events USING brin (event_time);
使用 BRIN 索引進行搜索:
SELECT *
FROM events
WHERE event_time BETWEEN '2023-09-24 00:00:00' AND '2023-09-24 23:59:59';
CREATE INDEX index_name ON table_name USING brin (column_name);
索引是一個強大的工具,能夠大大提高查詢效率。選擇正確的索引類型對於獲得最佳性能至關重要
希望通過這些例子,可以更好地理解 PostgreSQL 中不同類型的索引
resource: https://postgrespro.com/blog/pgsql/4161516


 iThome鐵人賽
iThome鐵人賽