跨度指標處理器從已收集的追蹤數據生成指標,包括請求、錯誤和持續時間(RED)指標。
跨度指標生成兩種指標:
如果你的系統沒有使用指標進行監控,但已實施分散式追蹤,那麼跨度指標尤其有趣。你可以從追蹤管道中直接獲得指標。
即使你已經有了指標,跨度指標也可以提供系統的深入監控。生成的指標將展示你的監控中的應用級別的洞察,只要跟踪在你的應用程序中傳播。
最後但同樣重要的是,跨度指標降低了使用exemplars的入門門檻。exemplars是在給定時間間隔內取得的特定追蹤的代表。由於跟踪和指標在指標生成器中共存,因此可以自動添加示例器,為這些指標提供額外的價值。
要在Tempo/GET中啟用服務圖,請啟用指標生成器,並添加一個啟用span-metrics生成器的overrides部分。詳細配置信息請參見此處。
跨度指標處理器通過檢查每個接收到的跨度來工作,並計算每個維度唯一組合的跨度總數和持續時間。維度可以是服務名稱、操作、跨度類型、狀態碼以及跨度中存在的任何屬性。
該處理器的設計目的是為了反映 OpenTelemetry Collector 中具有相同名稱的processor的實現。
注意:要了解更多關於基數的信息,以及如何對指標生成器進行乾運行,請參見基數文檔。
以下指標被輸出:
| 指標 | 類型 | 標籤 | 描述 |
|---|---|---|---|
| traces_spanmetrics_latency | 直方圖 | 維度 | 跨度的持續時間 |
| traces_spanmetrics_calls_total | 計數器 | 維度 | 跨度的總計數 |
| traces_spanmetrics_size_total | 計數器 | 維度 | 接收的跨度的總大小 |
注意:在 Tempo 1.4 和 1.4.1 中,直方圖指標被稱為
traces_spanmetrics_duration_seconds。這之後被更改,以保持與 Grafana Agent 和 OpenTelemetry Collector 生成的指標一致。
默認情況下,指標處理器將以下標籤添加到每個指標:service、span_name、span_kind、status_code、status_message、job和 instance。
service - 生成跨度的服務的名稱span_name - 跨度的唯一名稱span_kind - 跨度的類型,可以是以下五個值之一:
SPAN_KIND_SERVER - 跨度由其他服務的調用生成SPAN_KIND_CLIENT - 跨度對其他服務進行了調用SPAN_KIND_INTERNAL - 跨度在其生成的服務內部沒有交互SPAN_KIND_PUBLISHER - 跨度創建了被推到總線或消息代理的數據SPAN_KIND_CONSUMER - 跨度消費了在總線或消息系統上的數據status_code - 跨度的結果,可以是以下三個值之一:
STATUS_CODE_UNSET - 跨度的結果未設置 / 未知STATUS_CODE_OK - 跨度操作成功完成STATUS_CODE_ERROR - 跨度操作完成時出錯status_message(可選啟用)- 詳細說明 status_code 標籤原因的消息job - 工作的名稱,是命名空間和服務的組合;只在 metrics_generator_processor_span_metrics_enable_target_info: true 時添加instance - 實例 ID;只在 metrics_generator_processor_span_metrics_enable_target_info: true 時添加可以使用維度配置選項創建額外的用戶定義標籤。當配置的dimensions與默認標籤之一衝突(例如 status_code)時,相應維度的標籤前綴為雙下劃線(即__status_code)。
還支持使用 dimension_mapping 配置選項自定義維度的標記。
可以在 enable_target_info 配置選項中啟用一個名為 traces_target_info 的可選指標,該指標使用所有資源級屬性作為維度。
如果您使用基於比率的取樣器,則可以使用以下自定義取樣器以不丟失指標信息。但是,您還需要將 metrics_generator.processor.span_metrics.span_multiplier_key 設置為 "X-SampleRatio"。
package tracer
import (
"go.opentelemetry.io/otel/attribute"
tracesdk "go.opentelemetry.io/otel/sdk/trace"
)
type RatioBasedSampler struct {
innerSampler tracesdk.Sampler
sampleRateAttribute attribute.KeyValue
}
func NewRatioBasedSampler(fraction float64) RatioBasedSampler {
innerSampler := tracesdk.TraceIDRatioBased(fraction)
return RatioBasedSampler{
innerSampler: innerSampler,
sampleRateAttribute: attribute.Float64("X-SampleRatio", fraction),
}
}
func (ds RatioBasedSampler) ShouldSample(parameters tracesdk.SamplingParameters) tracesdk.SamplingResult {
sampler := ds.innerSampler
result := sampler.ShouldSample(parameters)
if result.Decision == tracesdk.RecordAndSample {
result.Attributes = append(result.Attributes, ds.sampleRateAttribute)
}
return result
}
func (ds RatioBasedSampler) Description() string {
return "Ratio Based Sampler which gives information about sampling ratio"
}
在某些情況下,您可能希望減少由 spanmetrics 處理器產生的指標數量。您可以配置處理器以使用include過濾器來匹配跨度中必須存在的標準,以便包含在內。在包含過濾器之後,您可以使用exclude過濾器來拒絕之前被過濾策略包含的部分。
目前,僅支持通過以下值類型的資源和跨度屬性進行過濾。
此外,可以根據以下固有的跨度屬性進行過濾:
以下固有類型可用於過濾。
在實施過濾策略時,可以直接針對固有鍵進行操作。例如:
---
metrics_generator:
processor:
span_metrics:
filter_policies:
- include:
match_type: strict
attributes:
- key: kind
value: SPAN_KIND_SERVER
在此示例中,kind為 “server” 的跨度被包含在指標導出中。
根據非固有屬性選擇跨度時,需要指定屬性的範圍,與 TraceQL 中指定的方式相似。例如,如果resource包含要在過濾策略中使用的location屬性,則需要將引用指定為 resource.location。這要求用戶知道並指定屬性要找到的範圍,並避免在不同的範疇中存在衝突值的模糊性。以下可能有助於說明。
---
metrics_generator:
processor:
span_metrics:
filter_policies:
- include:
match_type: strict
attributes:
- key: resource.location
value: earth
在上面的示例中,我們使用的是 strict 的match_type,這是值的直接比較。您可以使用 regex,這是 match_type 的另一個選項,來建立一個正則表達式進行匹配。
---
metrics_generator:
processor:
span_metrics:
filter_policies:
- include:
match_type: regex
attributes:
- key: resource.location
value: eu-.*
- exclude:
match_type: regex
attributes:
- key: resource.tier
value: dev-.*
在上面,我們首先使用 include 語句包含所有具有 resource.location 的跨度,該位置以 eu- 開頭,然後排除那些以 dev- 開頭的。通過這種方式,可以實現靈活的篩選方法,以確保只生成重要的指標。
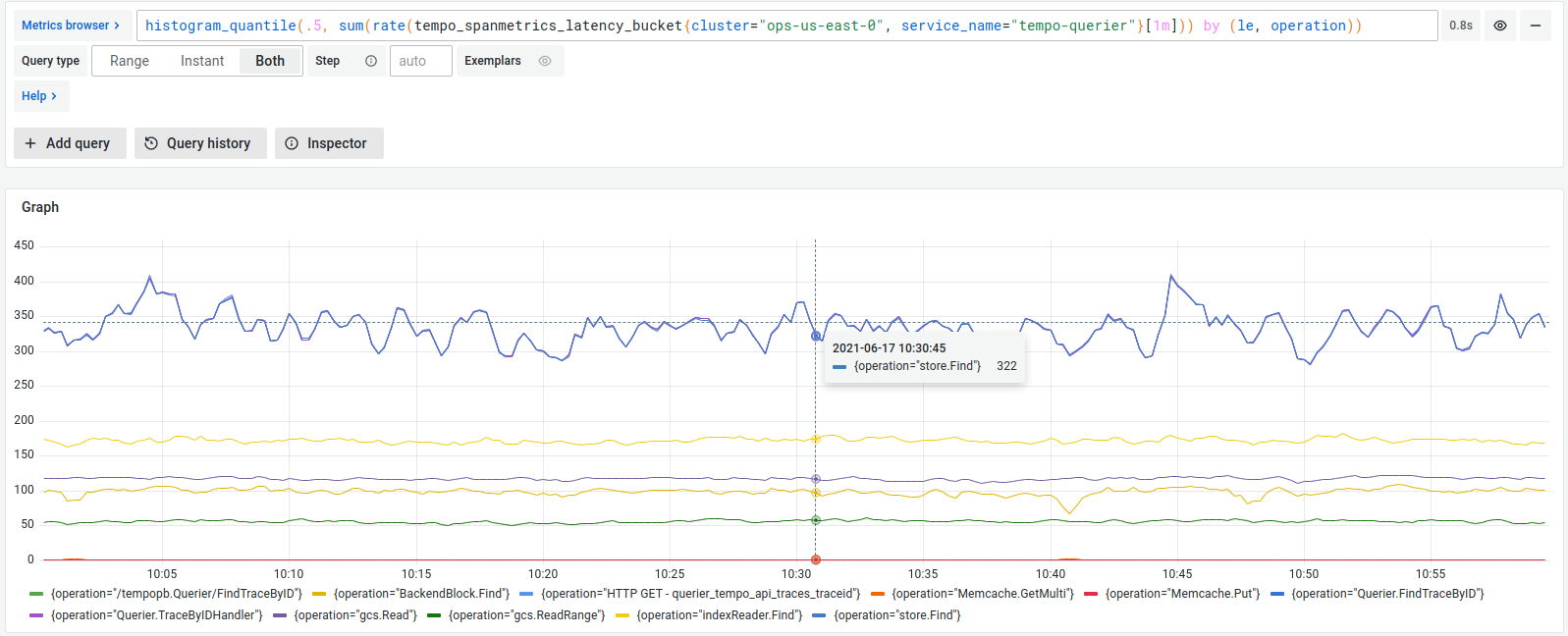
Span Metrics 處理器從接收的跟踪數據生成指標,這些指標包括請求、錯誤和持續時間 (RED) 指標。它主要生成兩種指標:一個計算請求的計數器,和一個跟踪所有請求持續時間分佈的直方圖。此外,這些指標可以通過多種維度(如服務名稱、操作、跨度類型、狀態碼等)進行分類和查詢。
用途:
簡言之,Span Metrics 能讓企業從他們的跟踪流水線快速獲得有用的指標,提供對系統的更全面監控和深入分析。


 iThome鐵人賽
iThome鐵人賽