這篇文章會使用 Python 的 Requests 函式庫,實作一個爬取臺灣銀行營業時間的牌告匯率的網路爬蟲。
原文參考:爬取臺灣銀行牌告匯率
本篇使用的 Python 版本為 3.7.12,所有範例可使用 Google Colab 實作,不用安裝任何軟體 ( 參考:使用 Google Colab )
每間銀行都有各自的牌告匯率,本篇範例採用「臺灣銀行」的牌告匯率網頁。
臺灣銀行牌告匯率網頁:https://rate.bot.com.tw/xrt
在網頁的最下方,有「下載文字檔」和「下載 CSV」兩個按鈕,將滑鼠移動到「下載 CSV」的按鈕上方,按下滑鼠右鍵,選擇「複製連結網址」,就能複製牌告匯率的 CSV 檔案網址。
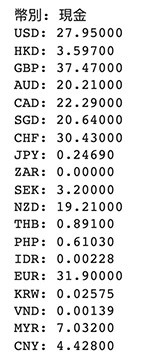
取得 CSV 網址後,使用 Requests 函式庫爬取網址內容,如果只是爬取內容沒做任何處理,會發現出現一大堆亂碼,這是因為沒有使用正確的編碼去讀取 CSV 檔案,這時可以加上「rate.encoding = 'utf-8'」就能處理亂碼問題,亂碼問題處理完成後,讀取檔案為純文字,並用換行與逗號拆分,就能取得幣別和匯率。
import requests
url = 'https://rate.bot.com.tw/xrt/flcsv/0/day' # 牌告匯率 CSV 網址
rate = requests.get(url) # 爬取網址內容
rate.encoding = 'utf-8' # 調整回應訊息編碼為 utf-8,避免編碼不同造成亂碼
rt = rate.text # 以文字模式讀取內容
rts = rt.split('\n') # 使用「換行」將內容拆分成串列
for i in rts: # 讀取串列的每個項目
try: # 使用 try 避開最後一行的空白行
a = i.split(',') # 每個項目用逗號拆分成子串列
print(a[0] + ': ' + a[12]) # 取出第一個 ( 0 ) 和第十三個項目 ( 12 )
except:
break
為什麼選擇臺灣銀行作為爬取的對象呢?因為它的牌告匯率網頁相對其他銀行來說較為單純,又有提供現成的 txt 和 CSV,對於爬蟲來說越簡單的網頁越好爬,所以就選擇臺灣銀行作為爬取的對象了。爬取匯率後,可以更近一步使用 CSV 儲存,或篩選出特定的匯率,藉由 LINE Notify 發送訊息,就更能發揮出將爬蟲功能。
大家好,我是 OXXO,是個即將邁入中年的斜槓青年,我有個超過一千篇教學的 STEAM 教育學習網,有興趣可以參考下方連結呦~ ^_^


 iThome鐵人賽
iThome鐵人賽