前言
昨天介紹了 RDD,還沒看過的人可以先點這邊看 RDD 的介紹:Day14 - Spark 介紹 (2):RDD
什麼是 Spark SQL?
Spark SQL 是 Spark 中用來處理結構化資料的模組,Spark SQL 將底層的 RDD 抽象為更高級別的 DataFrame/DataSet API,並支持以 SQL 語法查詢。
為什麼要有 Spark SQL?
-
更高層次的抽象
RDD 雖然是 Spark 的基本數據結構,但它對於處理結構化數據來說太複雜了,而這也大大增加了開發與維護的難度;Spark SQL 在 RDD 之上進行更高層次的抽象 (DataFrame/DataSet),使用者可以直接透過 SQL 語法查詢操作,提高了程式開發效率與可維護性。
-
效能優化
RDD 的原生 API 複雜,直接操作 RDD 容易產生冗餘操作,而經由 Spark SQL 送出的 query 都會經過 Catalyst optimizer 進行查詢優化、挑選執行計畫,所以雖然 Spark SQL 是建構在 RDD 之上,因此使用 Spark SQL 通常會比使用 RDD 來得有效率。
-
兼容性
Spark SQL 可以與多種數據源集成,如 Apache Hive、Apache HBase、Json、Parquet 等
DataFrame & DataSet
RDD 是以 Row 為為主的一種數據結構,而 DataFrame 與 DataSet 則都是基於 RDD 所衍生出的抽象表格結構:
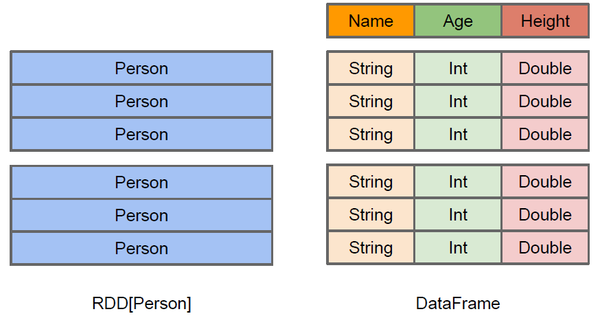
(圖片來源:A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets)
DataFrame 與 DataSet 有著非常相似的概念,都是表格結構,差別只在於型別 (type) 是否固定,而型別是否固定則是受到程式語言本身的性質影響(靜態型別 Static Typing vs 動態型別 Dynamic Typing):
-
DataFrame:型別不固定的分散式關聯式資料表,可於 Python、R 中使用
-
DataSet:基本上就是 型別固定 (type safe) 的 DataFrame,可於 Java、Scala 中使用,
Hive vs. Spark SQL
前幾天有介紹過 Hive,還沒看過的可以看這篇:Day10 - Hive 介紹,簡單來說,Hive 本質上是一個建構在 HDFS 之上的數據倉儲 (Data WareHouse),Hive 與 Spark SQL 一樣支援 SQL 語法,也一樣可以被用來處理大規模的結構化數據,我們不妨來比較一下 Hive 與 Spark SQL 兩者有何不同:
- Hive 是數據倉儲,表示 Hive 同時具有「存儲」與「查詢」兩種功能,而 Spark SQL 一般來說只能被用來查詢。
- Hive 使用 MapReduce 處理查詢,Spark SQL 則是基於 RDD 處理查詢,也因此兩者的處理效率有落差,一般來說 RDD 的處理效率是要優於 MapReduce 的。
Spark with Hive vs. Hive on Spark
事實上,Hive 與 Spark SQL 是可以集成的!有兩種模式,分別是 Spark with Hive 與 Hive on Spark,聽起來是不是很混亂啊😵💫😵💫😵💫
這邊簡單介紹一下:
-
Spark with Hive
本體是 Spark,由 Spark 負責查詢、解析優化、執行,Hive 只提供存儲功能,更準確的說是白嫖了 Hive 的 metaStore,比較容易實現,也是大部分人的選擇。
-
Hive on Spark
本體是 Hive,查詢、解析優化、存儲都維由 Hive 負責,但把 MapReduce 替換成 RDD,實現起來比較麻煩,需要更改 Hive 的配置。
預告
終於介紹完了,明天正式進入 Spark 安裝環節~
參考資料
Spark SQL, DataFrames and Datasets Guide
RDD vs. DataFrame vs. DataSet - Spark 基本介紹- GitBook
总结:Hive,Hive on Spark和SparkSQL区别 - 简书
Spark on Hive 和Hive on Spark的区别与实现- 大数据老司机


 iThome鐵人賽
iThome鐵人賽