介紹完監督是學習的演算法,接下來要來介紹非監督式學習演算法中的K-Means演算法。
K-Means演算法是指透過K個集群中心點,不斷更新位置,不斷的重新分群的方式,來劃分不同集群的一種非監督式演算法。其中集群的意思是指由機器將各種屬性相似度都高的樣本聚集在一起,形成一種不需要人為干涉的非監督式學習演算法。
1.隨機將樣本分為K群,例如K為2。
2.隨機選擇2個中心點(a1,b1)。
3.重新計算兩群質心的正確位置(a2,b2)。
4.各自移動a1->a2,以及b1->b2。
5.重新計算所有樣本與a2,b2的距離並重新分配樣本到所屬的群集。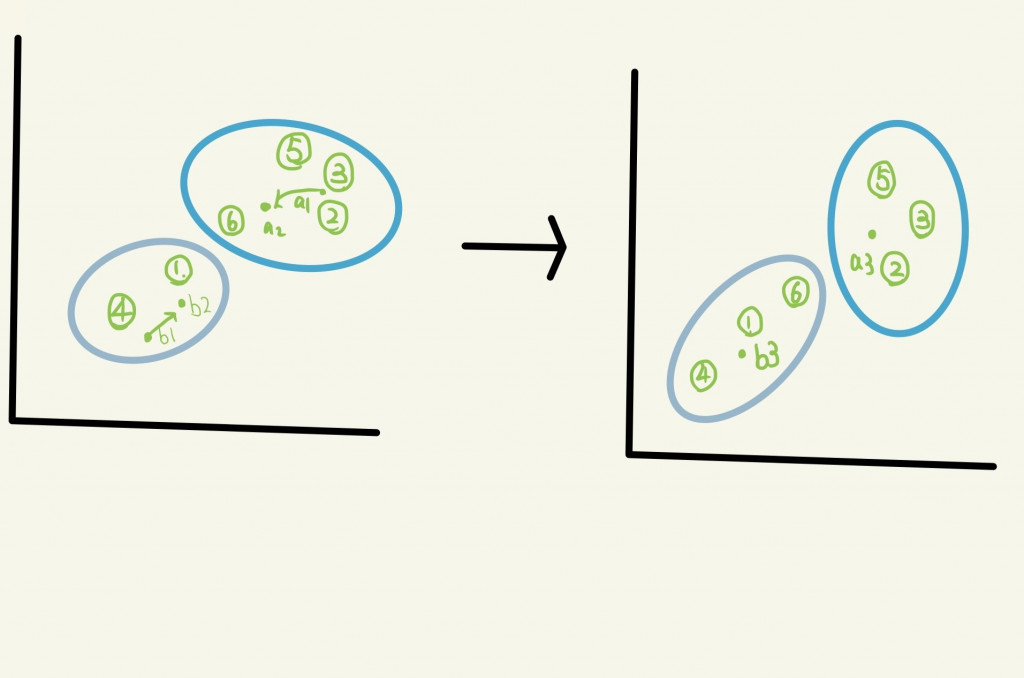
參考資料
人工智慧-概念運用與管理 林東清 著


 iThome鐵人賽
iThome鐵人賽