在前幾天的文章中我們有大概提到 SQL 中有提供 4 種 隔離級別 (Isolation Level) 分別是
Read uncommitted
Read committed
Repeatable read
Serializable
今天我們就來深入探討為什麼 SQL 中需要隔離級別,以及他們分別適用在哪些場景
在 SQL 中,當多個交易(transaction)並發地(同時)運行時,可能會產生一些問題
假設你有一個購物網站,使用者可以在網站上購買商品,每當一個使用者購買一個商品時,系統會執行一個交易來減少商品的庫存數量,那這時如果兩個交易同時運行,而且沒有適當的隔離,那麼可能都會讀取到商品 A 的庫存數量為 1。然後,兩個交易都可能會認為庫存充足,並同時減少庫存數量。最終結果可能是商品 A 的庫存數量變成了 -1,雖然應該只會發生在很小的機率上
那我們主要可以將並行交易(Concurrency Transactions)產生的問題分為下面 4 種
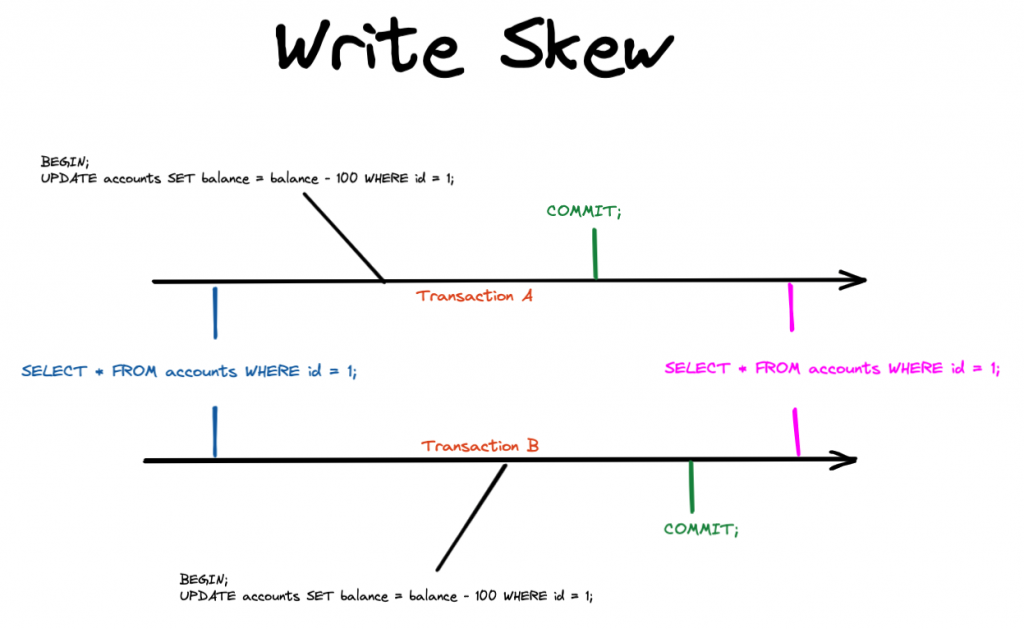
寫偏斜(Write Skew) 發生在兩個交易同時讀取相同的資料並試圖更新它時。這會導致數據的不一致
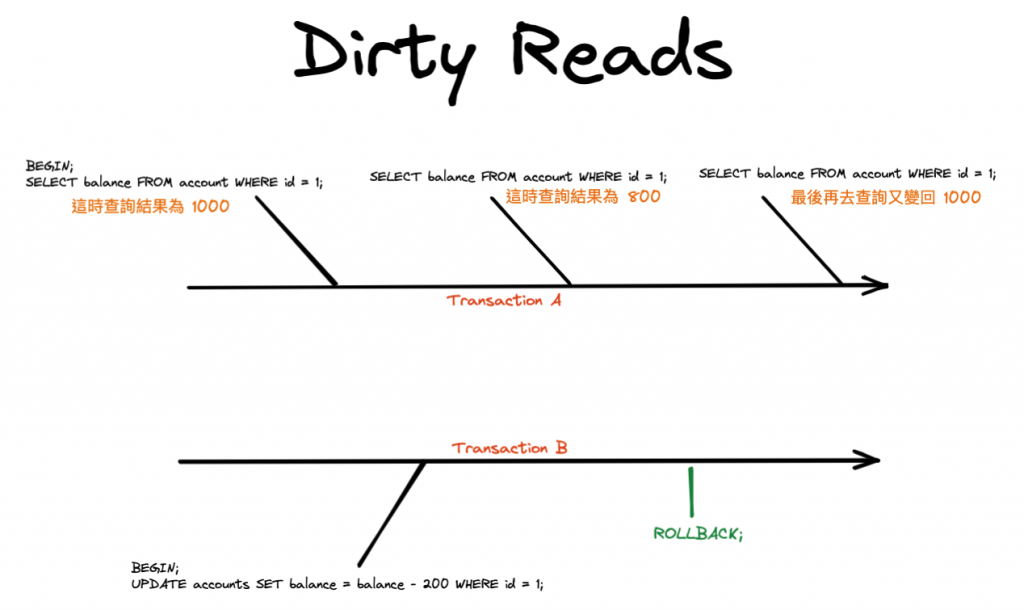
髒讀發生當一個交易讀取到另一個尚未提交的交易所作的更改
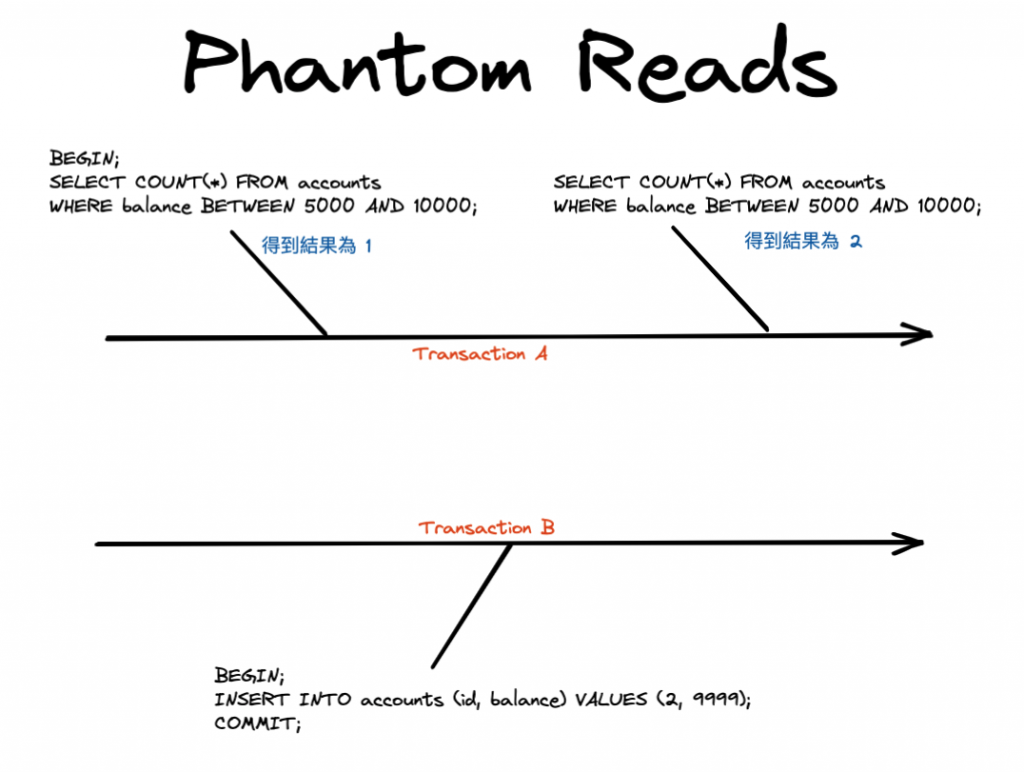
幻讀發生在一個交易在讀取某個範圍的資料(ROW)時,另一個交易插入了一個新的資料(ROW),導致第一個交易再次讀取該範圍時看到了 幻影 行
COMMIT;
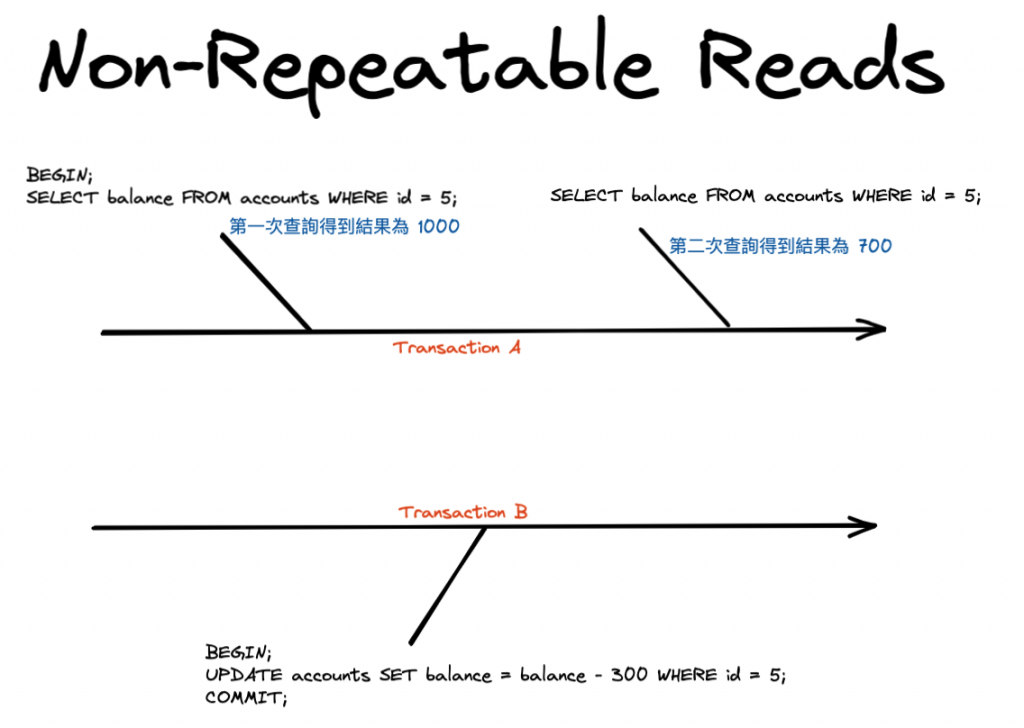
不可重複讀發生在一個交易讀取同一行兩次,但由於另一個交易所作的更改而導致數據不一致
未提交(Uncommitted) 的資料,而不可重複讀讀到的卻是已提交(Commited)的數據
所以看完了上述幾個因為並行交易(Concurrency Transactions)所產生的問題後,所以就輪到了 SQL 隔離級別的登場來解決這些問題
這是最低的隔離級別。在這個級別中,一個事務(Transaction)可以讀取另一個還未提交的事務的數據
在 PostgreSQL 是沒有 Read uncommitted 隔離級別
在 Read uncommitted 還是會發生下列的問題
寫偏斜 (Write Skew)
髒讀 (Dirty Reads)
幻讀 (Phantom Reads)
不可重複讀 (Non-Repeatable Reads)
這個級別保證一個事務只能讀取已經提交的事務的數據,這是許多資料庫系統的默認隔離級別
在 Read committed 還是會發生下列的問題
寫偏斜 (Write Skew)
幻讀 (Phantom Reads)
不可重複讀 (Non-Repeatable Reads)
-- 使用一般的 BEGIN 他預設就是使用 `Read committed` Isolation Level
BEGIN;
-- do something
COMMIT;
在這個級別中,一個事務在整個過程中都可以看到一個一致的數據視圖。即使其他事務已經提交了新的數據,它仍然可以看到數據的舊版本
在 Repeatable read 還是會發生下列的問題
寫偏斜 (Write Skew)
幻讀 (Phantom Reads)
不可重複讀,因為同一個交易中多次讀取同一筆數據會看到相同的結果幻讀
BEGIN;
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- do something
COMMIT;
這是最高的隔離級別。它通過完全封鎖對相同數據的同時訪問來避免所有的並發問題
在這個級別中,可以完全解決上述提到的並行交易(Concurrency Transactions) 帶來的問題,因為他會讓所有交易序列化排程,來確保即使交易是並發執行的,它們也會產生與某種串行執行相同的效果
BEGIN;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- do something
COMMIT;

