本篇回顧一下Transformer架構。Transformer模型包含了注意力(attention)及自注意力(self-attention)且不斷發展技術,可以偵測一個序列中用特別的方式相互影響和相互依賴的資料元素。Transformer 模型已取代數年前最熱門的深度學習模型,卷積和遞歸神經網路(CNN 和 RNN)。下圖為Transformer結構,左半邊為encoder,右半邊為decoder。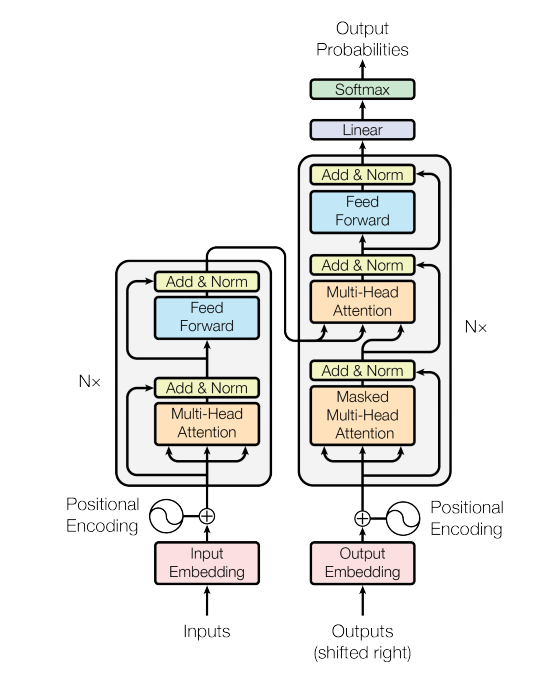
注意力是人類在學習或是認知事件時重要的機制,面對爆炸信息時,人類會忽略一些資訊,而專注在需要關注的資訊。當使用神經網路來處理大量的資訊時,也借用注意力機制,以提高神經網路效率。在目前的神經網路模型中,可以將最大池化層(max pooling)、及閥層(gating)機制來逼近注意力機制。
而自注意力是自行決定哪些資訊不予理會,哪些資訊留下。自注意力常用於處理序列資料。在這種技術中,Transformer模型不只可以處理序列中的單詞,還能自動抓取序列中各單詞間的關聯。
Transformer模型是發展行之有年的深度學習模型,已取代CNN及RNN。細看其結構,前半部為encoder,後半部為decoder,且使用自注意力機制,使訓練效率大大提高。過去訓練CNN及RNN需要的大量數據,在訓練Transformer時大幅減少,這使得機器翻譯的發展快速躍進。

