今天來分享對藍隊相關的一些理論知識
文章內容分成兩個獨立的 Topic,只是剛好放在同一篇文章
第一個是 SOC ,第二個是可觀測性
首先我們來介紹一下甚麼是資訊安全領域當中的SOC
在資訊安全領域中,SOC 代表的是 Security Operations Center,即資訊安全監控中心。
SOC 通常是一個組織或團隊,專注於監控、分析、檢測和應對組織內部和外部的資訊安全事件和威脅。
SOC的主要功能和職責包括:
監視:持續監視組織的資訊系統、網路流量、應用程式和端點設備,以檢測異常活動和安全事件。
檢測:使用各種技術和工具,例如入侵偵測系統(IDS)、入侵防禦系統(IPS)、端點保護軟體等,檢測潛在的威脅和攻擊。
回應:當檢測到安全事件時,SOC 負責迅速回應,採取適當的行動來控制和緩解威脅,以最小化損害。
分析:進行安全事件的深入分析,了解攻擊的來源、方法和目標,並提供有關事件的技術評估和建議。
警報和報告:生成警報和報告,將安全事件和行動報告提供給組織的管理層和相關利益相關者。
以上可能是比較標準的流程跟任務
還有一些也可能被包含在SOC的工作
威脅狩獵:主動尋找潛在的威脅行為,以及未被檢測到的攻擊活動,並採取預防措施。
漏洞管理:識別和管理系統和應用程式中的漏洞,確保及時修補,減少攻擊表面。
威脅情報:跟蹤外部威脅情報,瞭解行業和區域的威脅趨勢,以加強組織的防禦能力。
SOC 可以幫助組織有效地識別、應對資訊安全威脅和攻擊,確保組織的資訊資產得到適當的保護。
SOC 的情況因組織的大小、預算、行業和資安需求跟策略而異,並沒有一個固定的模式。一些組織選擇建立自己的SOC,並內部營運,也有許多組織則選擇將 SOC 服務委外給資安廠商。當然也可以走混合模式。
台灣有不少間資安的,這邊就放一下共契評鑑結果給大家參考而已
(提醒:共契是政府單位跟採用共契合約才會有的評鑑,沒被評鑑到或沒列在上面的資安廠商不一定表示沒提供該服務。評鑑的原因跟方式有興趣也可以深入了解看看)
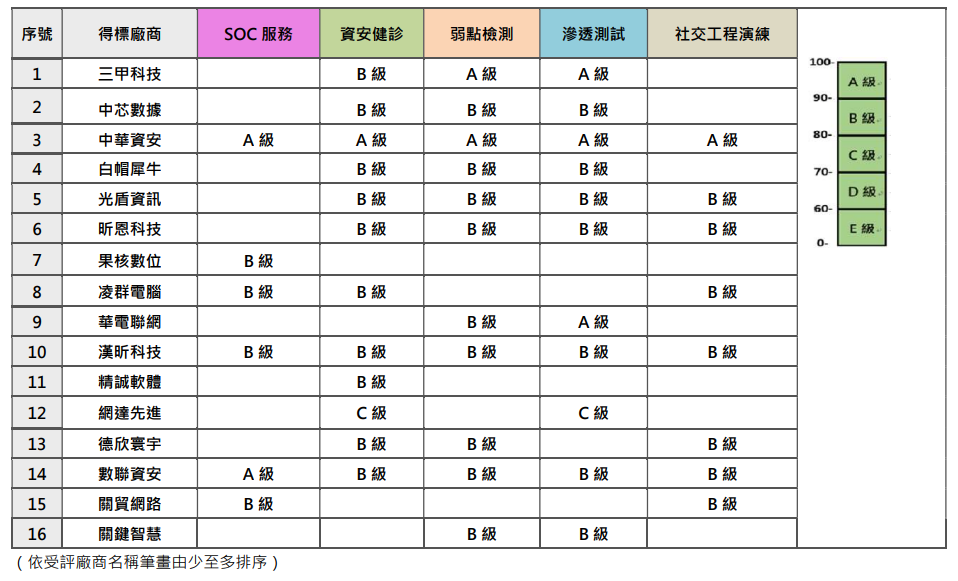
https://download.nics.nat.gov.tw/UploadFile/attachfilespmo/111年共契資安服務廠商評鑑結果v1.0_1120119.pdf
下圖是一個 SOC 的流程圖
SOC 通常進行監控、檢測、分析、回應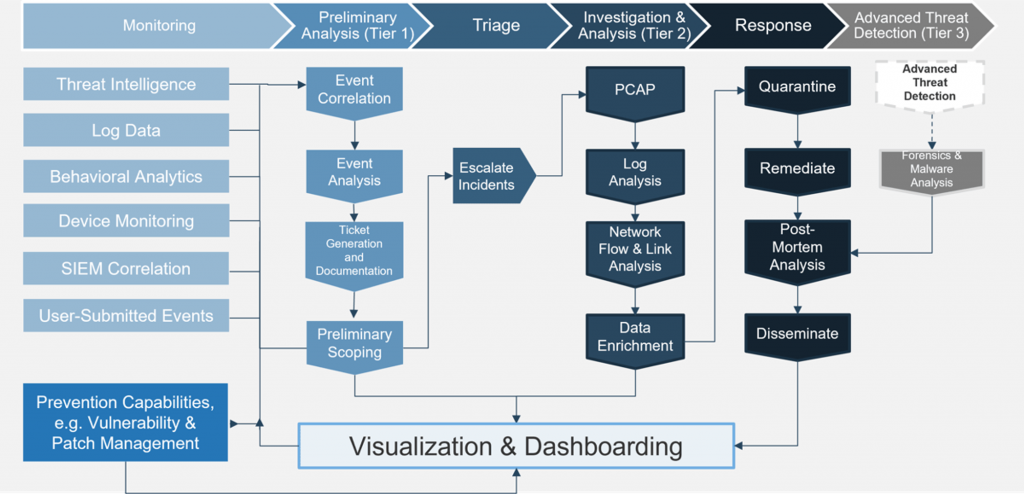
圖片來源: https://www.infotech.com/research/ss/develop-a-security-operations-strategy
從流程圖當中可以看出有分成Tier 1, Tier 2, Tier 3
其實也就類似台灣資安廠商 SOC 中心的L1、L2、L2
L1 通常負責即時監控,進行簡單的初步評估,做事件的過濾判斷
在資訊安全運營中心(Security Operations Center,SOC)中,L1、L2和L3通常代表不同層級的安全分析師或威脅應對人員,他們在安全事件的監視、分析和回應方面具有不同的職責和技術水平。
2通常被稱為「一線」或「初級」安全分析師。L1 安全分析師是 SOC 的第一道防線,主要負責監視來自各種安全工具和系統的警報和事件。L1 會快速檢查和分類警報,進行初步評估,做事件的過濾判斷,確定是否需要更進一步的調查。他們可能處理一些常見的安全事件,如惡意軟體警報、帳號駭客嘗試等。如果事件需要進一步的調查和處理,L1 分析師可能會升級事件給 L2 分析師。
通常被稱為「二線」或「高級」安全分析師。L2 安全分析師有較深入的技術知識和經驗,他們可能負責複雜和深入一些的事件調查。這包括分析可能的威脅來源、受影響的資源,以及潛在的影響。L2 分析師可能需要更多的技術工具和技巧,以進行進一步的數據分析和行為追蹤。如果事件需要更深入的分析或升級,L2 分析師可能會將事件升級給 L3 分析師。
通常被稱為「三線」或「專家」安全分析師。L3 安全分析師是最高層次的專家,他們處理最複雜、嚴重的安全事件。他們可能需要進行深入的威脅狩獵、數據分析、緊急應變、惡意程式分析、數位鑑識等。L3 分析師通常有更高級的技術能力,並能夠提供更高層次的建議和解決方案。在某些情況下,L3 分析師可能需要協助法務部門或外部安全專家進行法律調查或法律程序。
所以 L1、L2 和 L3 分析師在 SOC 中扮演著不同層級的角色,共同確保組織能夠監視、檢測和應對各種資訊安全事件和威脅。不過資源有限的公司,所謂的一個人的藍隊,不會有甚麼L1、L2、L3,通常都是一人擔任多角,特別是對於小型企業、傳統產業或新創公司。
對於 SOC 有初步認識之後,就是主題之一的 SOC visibility triad
顧名思義,就是 SOC 所仰賴的三項核心元素,是由權威機構 Gartner 於 2015 年所提出的一個觀點。SOC對於安全事件的可見性,來自於三個主要要素,這些要素相互補充與搭配,以確保對組織的系統和網路活動具有完整的可見度和監控性。
這三個要素被稱為是SOC visibility triad(SOC可視性金三角),
分別是:SIEM、NDR、EDR
不過請不要糾結在 SIEM、NDR、EDR 這三個『名詞』上面,尤其不要只是把它想成產品。
其實三者強調的是對於日誌可見度(Log Visibility)、網路可見度(Network Visibility)和端點可見度(Endpoint Visibility)。
SIEM 是對組織的系統和應用程式生成的日誌事件的監控和分析,以集中管理方式蒐集和分析來自多個來源的日誌數據。我們前面花了好幾篇介紹的 Wazuh 主要的功能之一就是SIEM。透過日誌可見度,SOC 能夠追蹤活動、識別一些威脅,並檢測異常事件生成警報。SIEM 還可以幫助組織有效地管理和保留安全事件和活動的日誌,以便調查和合規性要求。
NDR 指對組織網路流量的監控和分析。通過網路可見度,SOC 能夠辨識網路中的異常連接、異常行為、異常流量、未授權的活動和潛在的威脅。網路可見度除了以 NDR 為稱的產品和平台以外,包括入侵檢測系統(IDS)、入侵防禦系統(IPS)和流量分析工具等,以捕捉和分析網路數據為目的的都算是。目前也有不少網路安全分析工具都宣稱採用了機器學習的技術來協助檢測。
EDR 是一種面向行為的安全檢測技術,專注在於檢測直接發生在端點上的活動(這邊的端點泛指伺服器、桌上型電腦、筆記型電腦、手機等等)。透過端點可見度,SOC 能夠察覺到可能的威脅行為、異常活動和惡意軟體。包括安裝終端保護工具(NDR)、或是基於主機的入侵偵測系統(HIDS)和防毒軟體等,以保護各種端點設備。
當我們要對組織內的安全進行監控,應該要從一個比較高層次的角度去探討我們需要監控甚麼才可以有較高的覆蓋率。
對 SOC visibility triad 有正確的了解,可以幫助我們確保組織能夠全面性地進行監控、分析和回應各種資訊安全威脅和事件。透過理解和應用 SOC Visibility Triad,我們能夠更有效地捕捉潛在的風險,保護組織的資產和數據。
不過同時也必須了解,要確保組織的資訊安全並不是一個簡單的任務。威脅演化迅速,攻擊手法日新月異,這就需要我們不斷地更新我們的安全防禦方法。在這個情況下,依賴單一的安全產品或技術可能會存在局限性。每個產品或技術都有其自身的優勢和限制,無法涵蓋所有可能的威脅場景。
例如,某個入侵偵測系統(IDS)可能在網路層面做得很好,但可能無法有效地檢測到端點上的異常行為。同樣地,某個日誌管理系統可能能夠記錄大量的事件,但可能缺乏對使用者行為內容達到深入分析。
這就是為什麼從需要從 SOC Visibility Triad 觀點切入思考。透過端點可見度、網路可見度和日誌可見度的綜合應用,我們能夠填補不同安全產品和技術之間的缺口。這種全面性的監控和分析方法,能夠讓我們捕捉到更多的威脅指標,識別異常行為,並更快速地響應威脅。
上面介紹的是針對於資訊安全的 SOC visibility triad,接著我想稍微跳開資安這個主題,來分享可觀測性(Observability)。可觀察性通常比較常被維運、開發、SRE 人員所注意到。
The traditional “Three Pillars of Observability” are usually defined to be Metrics, Logs and Traces
傳統的「可觀測性三大支柱」通常被定義為指標(Metrics)、日誌(Logs)和追蹤(Traces)。這些支柱對於監控和排除複雜的問題時起到很大的幫助,無論是傳統的單體架構還是現代的微服務和分佈式系統都是可以派上用場。
雖然與剛才提的 SOC visibility triad 無關,但有一些異曲同工之妙,兩者目的都是要達到更全面、更完整的監控。Observability 泛指的範圍較廣,並非鎖定在資訊安全事件上,所以可能牽涉的單位也不同,可能是 Infra、IT部門、SRE 或是 DevOps。例如 Infra 單位通常都一定會對 Metrics 進行監控,確認系統的資源使用量。
指標是定量的測量數據,可以提供有關系統健康和資源情況。通常是隨著時間捕捉數值的紀錄,例如 CPU使用率、記憶體使用率、硬碟空間、I/O數據、錯誤率等。指標可用於追蹤趨勢、設定警報以及識別異常。通常指標監控會搭配可視化工具,有精美的儀表板和圖表,有助於視覺化數據了解趨勢和變化。
日誌是應用程式、服務和系統生成的事件和活動的記錄。它們紀錄有關系統和服務行為不同方面的詳細資訊,包括使用者操作、錯誤、警告和其他重要事件。日誌對於故障排除、診斷問題、識別根本原因和理解導致問題等至關重要。適當的日誌管理,除了紀錄跟儲存日誌之外,也包含如何蒐集和彙整,如何對日誌內容進行搜尋、索引和分析。
追蹤提供了特定連接或請求在分佈式系統的不同組件跟服務間傳遞時的詳細資訊。它們有助於了解整個請求的過程,也可以視覺化流程操作,顯示各種服務、資料庫和其他資源之間的交互作用。追蹤對於診斷性能瓶頸、找出延遲問題和優化系統交互非常有用。
這三大支柱共同作用,提供了系統行為的全面視角:
在現代軟體工程實踐中,這些支柱是實踐可觀測性策略的核心,通過結合指標、日誌和追蹤,開發和運維團隊可以快速識別、診斷和解決複雜系統中的問題。
對於 Metrics 與 Logs 的描述,我認為是不太需要再多說甚麼,上面簡介已經滿白話了,而且我相信不少人都建置或是使用過的經驗。從技術或工具方面,例如許多人會使用 Prometheus 或是 Zabbix 進行 Metrics 監控,還會使用 Grafana 或 Promdash 來視覺化。對於 Log 的分析,目前比較流行的像是 ELK。
這篇文章會特別提 Observability,其實是我想特別推廣一下關於 Traces。Traces 可能在一些組織是沒那麼成熟的技術,可能甚至沒有引入。
對於 Traces 想更深入了解實際技術,可以找找看 APM。其實今天文章本來是想多介紹 APM,然後順便架設一個範例的。但我覺得好累ㄛ,而且文章感覺也夠長了。
APM(Application Performance Monitoring or Application Performance Management)
APM 是對軟體應用程式的性能和可用性的監控和管理,透過APM去檢測及診斷複雜的應用程式性能問題,以維持預期的 SLA。使用 APM 的監控其實就是達到上面所謂的 Traces 的監控。APM透過埋入Agent或是程式碼的技術,可以達到深入至程式碼層級的追蹤(監控),包括程序內部執行過程、服務之間調用情況。
所以 APM 監控可以協助組織:
APM 相關的產品其實非常多,包含像是 Elastic APM、Apache Skywalking、Pinpoint、Jaeger、Dynatrace、Zipkin …
有機會可以去研究看看,網路上跟過去鐵人賽也都有人分享了一些跟APM相關的優質文章
今天內容就到這邊囉
希望大家看完對於監控/安全監控都能有夠好的一些理解,或是有幫助

