今天要來分享的是一個在語義分割領域中,很典型的分割模型

U-Net
是一個深度學習的網路架構,專門為處理醫學影像分割任務而設計的,不同於一般的卷積神經網路(CNN),它不會有全連接層的部分,這個特點使得它更適合處理不同尺寸的影像
而 U-Net 這個名字源於它獨特的網路結構,會有下上採樣的對稱架構,讓它看起來就像字母 "U" 一樣,因此就取名為 U-Net
模型結構
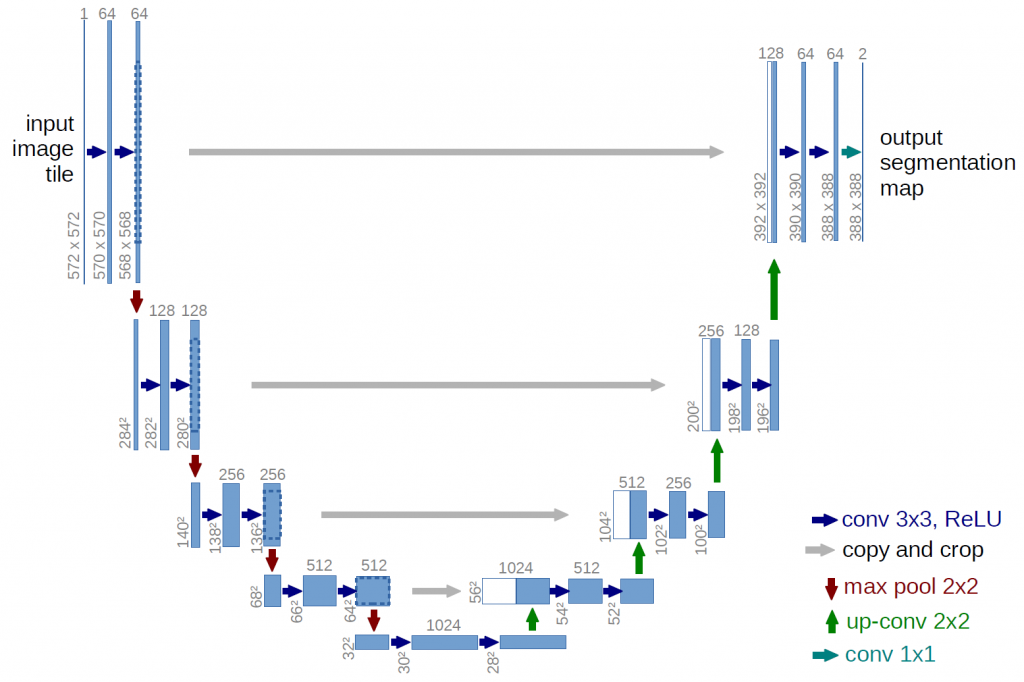
U-Net 模型可以分為三個主要部分:
- 編碼器(Encoder):編碼器負責通過卷積和最大池化等操作對輸入影像進行降維處理(Downsampling),以提取影像中的重要特徵。我們可以把這一過程想像成在影像上移動一個小視窗,然後記錄下視窗中的特徵
- 解碼器(Decoder):解碼器則通過反卷積做上採樣(Upsample)來把特徵資訊重新組合成一張與原始影像大小相同的新影像,其中,反卷積會逐步還原原始輸入影像中的高頻資訊(影像細節)和低頻資訊(影像輪廓),最後生成的影像就會是像素級的分割結果
- 跳躍連接(Skip Connection):跳躍連接是在編碼器和解碼器之間的連接,它有助於保留在編碼器階段可能遺失的資訊,通過拼接,使得解碼器在上採樣的時候,能夠保留更多在編碼器時的特徵圖中的高分辨率細節資訊,提高分割的精確度。這對於語義分割任務非常重要,因為編碼器的卷積會保留重要的細節資訊
優點
U-Net 有兩個主要的優點,
- 豐富的特徵提取:U-Net 能夠捕捉影像中微小細節,這對於需要高度詳細性的任務來說,會很有幫助,例如細胞分割
- 影像擴展性:U-Net 模型可以擴展到不同大小和類型的影像,這使得它非常靈活,可以用於各種場景
參考
U-net: Convolutional networks for biomedical image segmentation


 iThome鐵人賽
iThome鐵人賽