在人工智慧,我們會利用資料的特徵來訓練模型,使其能夠進行各種任務預測,但是在實際應用中,特徵之間的數值範圍和分佈可能存在巨大的差異,這樣的差異如果不加以處理,可能會對模型的性能產生負面影響。舉例來說,如果有兩個特徵 f1 和 f2,其中 f1 的數值範圍在 1 萬到 5 萬之間,而 f2 的數值範圍只在 1 到 2 間,這樣的數值差異是相當巨大的,尤其是當這些特徵之間相關性很高時,這種差異可能對模型的性能產生負面影響,像是特徵 f1 的變動(1 萬跳到 3.8 萬)可能對預測的影響會大於 f2 的變動(1 到 0.001)
所以在資料前處理中,常常會用到特徵縮放(Feature Scaling)這個步驟,來確保數據中的某些特徵要能處於相似的尺度
是一種將資料轉換為新的尺度,使得所有特徵的值都位於一個固定範圍內,這個過程有助於確保不同特徵之間的數值差異保持在合理範圍內,以確保模型在訓練和預測時能夠更好地表現
以下是一些常見的正規化方法:
將資料縮放到 [0, 1] 之間,保留了數據間的相對順序和距離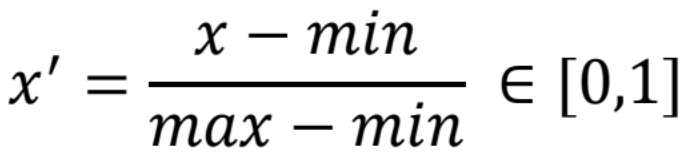
將資料縮放到 [-1, 1] 之間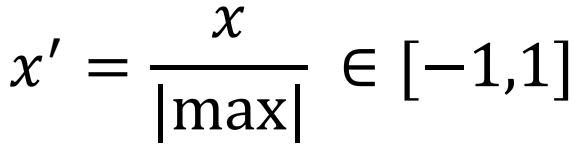
就是 Standardization,將資料轉換為平均值為 0,標準差為 1 的新尺度的方法,使資料轉換成接近標準常態分佈的樣貌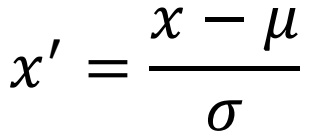
將資料縮放到 [-1, 1] 之間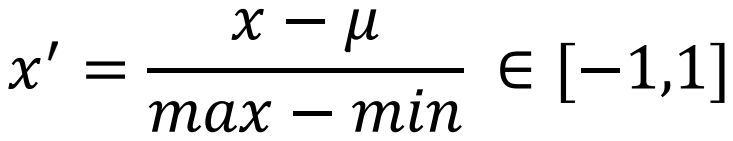
有些模型就算沒有做特徵縮放,也不會對模型造成影響,像是對於決策樹(Decision Tree)等 Tree-based Model,特徵的尺度通常不會影響模型的性能


 iThome鐵人賽
iThome鐵人賽