今天開始會往影像分割分類任務進行分享~
首先,來介紹一下影像分割的任務!影像分割的核心目標是對一張影像中的每個小區域進行精確標記,來告訴模型這些區域代表的是什麼內容,也就是要讓模型學習如何理解和區分一張影像中的不同部分,這種任務在電腦視覺和影像處理中佔有很重要的部分,因為它可以讓我們對於影像中的物體進行更深入的探討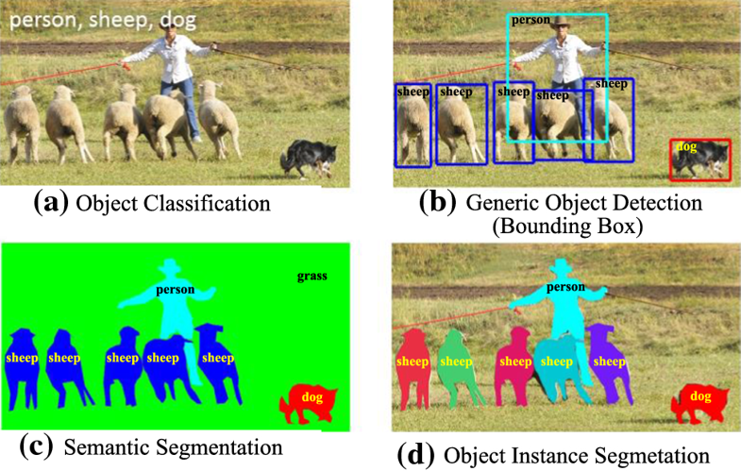
以下是不同的任務:
會去識別影像中的物件
舉例:如果影像中有一隻貓,那模型就能辨識出這裡面有貓
不僅會識別出影像中有哪些物件,還會告訴你它們在影像中的確切位置
舉例:如果影像中有一隻貓,模型會在貓的周圍畫一個框,告訴你貓在影像的哪個位置
影像是由像素(Pixel,畫面的最小單位)組成的,語義分割就是會將這些像素根據它們代表的物體或物體部分進行分組
舉例:如果影像中有一隻貓和一棵樹,模型會將貓和樹的像素分開,告訴你用紅色標註的像素屬於貓,用藍色標註的像素屬於樹
是物件偵測和語義分割的結合體,模型不僅能夠識別不同物體的類別,還能夠區分同類別不同實例之間的差異
具體作法是模型會進行物件偵測,找出影像中的物體,然後,模型會對每個物體進行語義分割,給予它們獨立的編號或標識,也就是告訴你每個像素屬於哪個實例
舉例:如果影像中有三隻貓,模型會將這些貓辨識出來並做區分(不同的貓用不同的顏色標註),告訴你這是三隻不同的貓
結合了語義分割和實例分割,模型會將影像中的所有像素進行語義分割,讓每個像素都一定能屬於某個物體類別,同時將這個物體的不同實例區分開來,簡單來說全景分割就是也會把背景考慮進去,來實現更全面的影像理解,這種方法可以提供有關影像中每個物體及其背景的詳細資訊
Microsoft COCO: Common Objects in Context


 iThome鐵人賽
iThome鐵人賽