所謂的單元(Unit)是指音頻訊號的分析和表示的基本單元,可視之為音訊數據的小塊或小段,通常包含數百至數千毫秒的音訊信號。在語音處理和音訊處理中,將長時間的音訊信號分成小單元有助於進行特徵提取、分析和建模。
而知名模型HuBERT通常使用 "Unit" 來作音頻特徵的輸入,這些特徵將被用於進行語音辨識、語音生成或其他相關任務。"Unit" 會以不同的時間間隔進行劃分,取決於模型的設計和任務的需求。這些單元通常會通過預處理和特徵提取的過程轉換為模型的輸入。
*Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed,”HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, arXiv:2106.07447v1, 2021
使用960小時的LibriSpeech音訊及60,000小時Libri-light音訊檔案作非監督式預訓練,實際上是非監督式訓練之一的自監督式學習(Self-supervised Learning)。
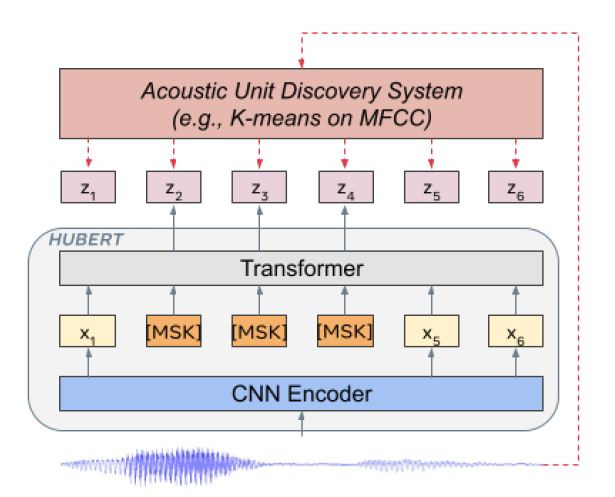
利用K-means分群演算法發現語音單元,為了對用來訓練HuBERT模型的資料-960 小時 LibriSpeech訓練集-產生標籤,對於39個維度MFCC(梅爾頻率倒譜係數,Mel-Frequency CepstralCoefficient)特徵執行100個分類的K-means分群。為了迭代出更好的結果,在Transformer層執行500個分類的k-means分群(非微調),然而整個960小時的訓練資料記憶體無法負荷,隨機提取10%的資料擬合k-means模型。
BERT模型使用部分遮蔽的連續語音特徵來預測結果。僅評估遮蔽區域的預測損失,讓模型學習推斷的未遮蔽的輸入數據,來正確預測遮蔽目標,HuBERT是被迫學習聲學和語言模型的自監督是學習模型。這樣的模型有二個特點:(1) 模型需要建模將未遮蔽的數據轉換為有意義的連續潛在特徵,與經典的聲學模型有關。(2) 為了減少預測誤差,模型需要擷取學習到的資料間的長時間
表現。
Unit是為了音訊處理而需要將訊號切割成一小段的最小單位,根據不同的模型設計及任務需求,會以不同的時間間隔進行劃分。而HuBERT模型全名為Hidden Unit BERT,即基於隱藏單元的BERT語音處理模型。HuBERT主要是利用k-means分群演算法針對MFCC特徵作分類,另一方面將編碼後的語音訊號部分遮蔽,提升預測準確率。

