今天要從 ML 系統設計的角度談談與資料相關的挑戰,延續 Ferris 日本動漫化系列,變成修理 Pipeline 的孩子
🏮 接下來幾天都會以兩至三天為一組的架構來介紹 Rust 可以如何被應用在 MLOps 中。
前幾天會先介紹以系統設計的角度會怎麼看當天的 ML 系統部件,然後隔天再探索 Rust 的可能性!
這部分要討論如何從 ML 系統的角度來處理資料,會談談與資料相關的幾個重要特點。
有兩種常見的資料格式: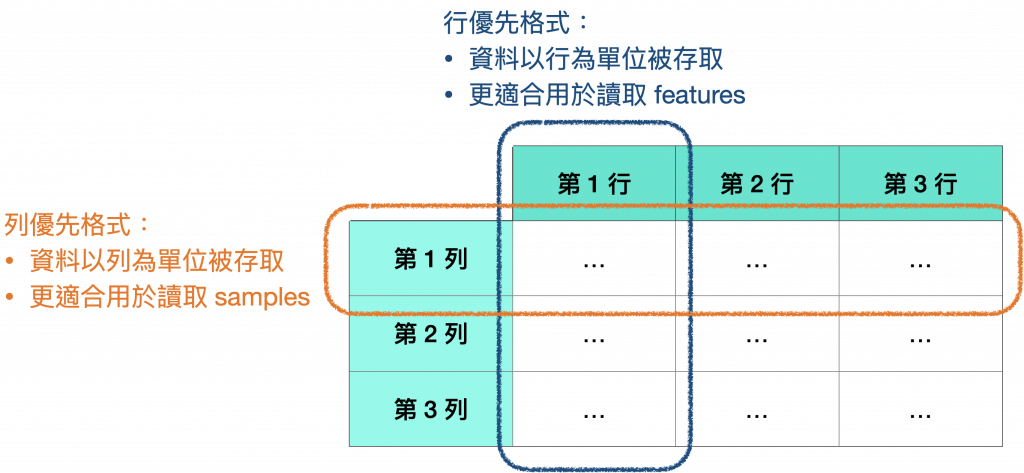
*圖片修改自 Designing Machine Learning Systems Figure 3-4.
處理資料最常使用的 Pandas (以及 Polars) 實際上就是建立在行優先格式基礎上的,因此更適合處理這種格式的資料。
而在 NumPy 則可以指定優先格式,當建立 ndarray 時,若未指定就會使用預設的列優先格式。
延伸閱讀:Distilled AI - Primers • Pandas
資料模型是資料如何在電腦中被儲存和呈現的結構。
有兩種常見的資料模型:關聯模型和 NoSQL 模型。
關聯模型使用表格來儲存資料,而 NoSQL 模型則使用各種不同的儲存格式,例如文件、圖形和鍵值對。
資料儲存引擎(又稱為資料庫)是資料在電腦中如何被儲存和檢索的軟體實作。
資料庫通常針對特定類型的資料和任務進行優化,兩種常見的資料庫任務為:
但隨著資料庫技術的發展,OLTP 和 OLAP 的界限正變得越來越模糊。
許多現代資料庫都支援混合任務,也就是說,它們可以同時有效地處理 OLTP 和 OLAP 查詢。
甚至從 Google 搜尋趨勢可以看出對 2023 年的現在來說,OLAP 與 OLTP 已經是過時的詞了: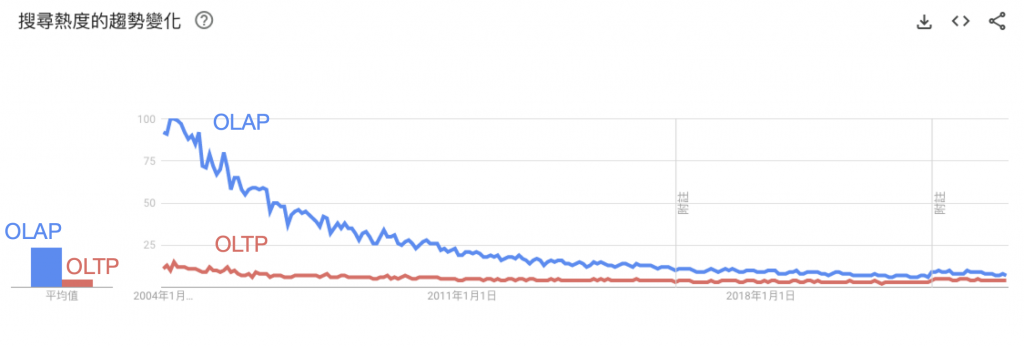
*Google trends
ETL 是將資料從各種來源提取、轉換和加載到目標目的地(例如資料庫或資料倉儲)的過程。
它對於 ML 應用程式非常重要,因為它可以確保資料具有正確的格式和質量,以便 ML 模型可以有效地進行訓練和評估。
ETL 過程分為三個主要階段:提取、轉換和加載。
ETL 是一個複雜的過程,但使用正確的工具和技術可以使其更加高效和可靠。
但隨著網路的普及,導致資料量急劇增長與資料的性質改變,傳統資料倉儲因其結構化和模式固定的特點,已無法滿足企業對資料管理的需求,企業紛紛將目光轉向較為靈活的資料湖泊,
這時候企業的想法大多是:「為什麼不將所有資料儲存在資料湖泊中,這樣我們就不必處理模式的變化?任何需要資料的應用程序都可以從那裡提取原始資料並進行處理。」
這種新興的模式在儲存資料之前不需要進行太多處理,所以允許資料快速到達,而將資料先加載到存儲中,然後再進行處理的過程有時又稱為 ELT (提取、加載、轉換)。
然而,隨著資料量的不斷增長,這種想法變得不再那麼有吸引力。
在大量原始資料中找出所需資料的效率過於低下,且隨著企業將應用程序轉移到雲端,基礎設施變得更為標準化,資料結構也回歸標準化,將資料提交到預先定義好的 schema 變得更加可行。
隨著企業權衡儲存結構化資料與儲存非結構化資料的優缺點,供應商正在開發結合了資料湖泊的靈活性與資料倉儲管理優點的混合解決方案。例如,Databricks 和 Snowflake 都提供資料湖庫解決方案。
延伸閱讀:什麼是資料湖庫?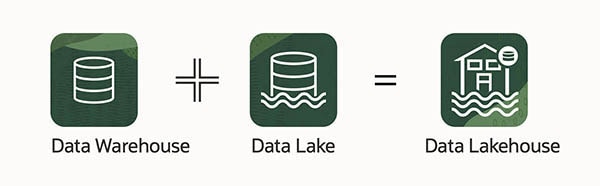
前面的討論都是在單一個流程中所使用的資料格式、資料模型、資料儲存和處理。
但在實際產品環境中,通常不會只有一個流程,而是多個流程。
因此,一個問題就出現了:如何將資料在不共享記憶體的不同流程之間傳遞?
當資料從一個流程傳遞到另一個流程時,我們說資料從一個流程流動到另一個流程,這就形成了資料流。
資料流有三大主要模式:
資料流經資料庫:資料從 A 流程流進資料庫,再由資料庫流進 B 流程。
這種模式需要訪問資料庫,而讀寫資料庫可能會很慢,因此不適合需要低延遲的應用程式。
資料流經服務:當流程 B 需要資料時,使用 REST 和 RPC APIs 向流程 A 發送請求。
將應用程式的不同組件作為獨立的服務進行架構即是所謂的微服務架構。
資料流經即時串流:這種模式使用 Apache Kafka 或 Amazon Kinesis 等即時串流系統。
由於資料通過服務可能會很複雜並且同步 (這意味著一個服務的故障可能會導致所有其他下游服務的故障),因此我們需要一個仲介 (broker) 或實時傳輸來協調服務之間的資料傳輸。
目前有兩種即時串流模式:


將資料放在即時串流中允許我們對串流資料進行計算,這部分可以使用 Apache Flink 等串流技術進行平運算算,Flink 是高度可擴展和完全分佈式的。
串流處理的優勢在於其有狀態計算,讓我們可以只對新資料進行計算,然後將其與舊有資料計算合併。
這部分要討論如何從資料科學的角度來處理資料,也就是如何建立適當的訓練資料集。
在建立訓練集時,有幾種常用的抽樣方法,其優缺點整理如下:
簡單隨機抽樣(simple random sampling):所有樣本在總體中被抽中的機率相等。
分層抽樣(stratified sampling):將總體劃分為不同的組,然後從每個組中抽取樣本。
加權抽樣(weighted sampling):根據每個樣本的權重來抽取樣本。
水塘抽樣(reservoir sampling):一種用於抽取固定大小樣本的演算法,格外地適合用於串流資料 (大部分產品的情況)。
舉例來說,假設我們要處理一個 X 文流,並且想要抽取一定數量的 X 文(k)進行分析或訓練模型。
但我們不知道有多少條 X 文,只知道不可能全都存下來,這代表我們不可能事先知道哪條 X 文該被選擇的機率。
而我們至少想要確保:
這時候就是水塘抽樣派上用場的地方,這個演算法涉及一個水塘 (它可以是一個 array),並包括以下三個步驟:
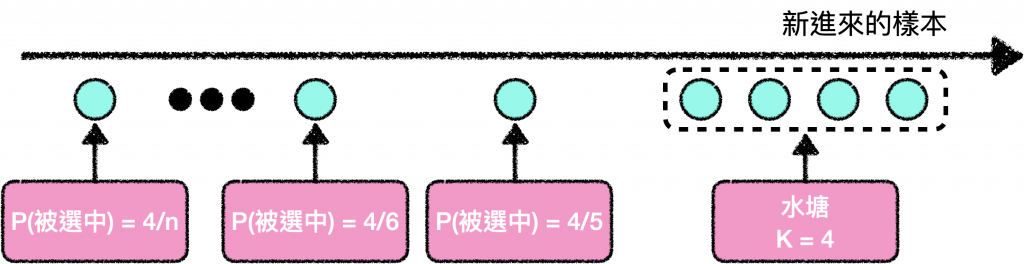
*圖片修改自 Designing Machine Learning Systems Figure 4-2.
也就是說,每個輸入的第 n 個元素都有 k/n 的概率進入水塘 (第五個元素被選中的概率是 4/5),之後的元素被選中的機率會降低。但是,由於之後的元素被踢出水塘的機率也較低,因此每個元素被選中的最終機率是相同的。
重要性抽樣(importance sampling):是最重要的抽樣方法之一,它讓我們可以在只能取得另一個分佈的情況下對某分佈進行抽樣,,簡單來說揪是,如果我們想要以 P(x) 分佈來抽樣 x,但 P(x) 的取得很困難,我們可以改為使用 Q(x) 來抽樣,只需要將抽樣以 P(x)/Q(x) 做權重即可。
總的來說:
在機器學習模型中,我們通常需要帶標籤的數據,這些資料可以使用手工標籤或自然標籤。
其中自然標籤是指模型的預測可以由系統自動評估或部分評估的情況。
例如,如果按照 Google Maps 建議的路線行駛,在行程結束時,Google Maps 就會知道行程實際耗時多長。
在這個例子中,Google Maps 可以使用自然標籤來評估其路線規劃模型的性能。
Google Maps 可以追蹤用戶的實際位置和時間,並將其與預測的路線和時間進行比較,因此可以自動評估其模型,而無需人工標籤。
自然標籤在機器學習中非常有用,因為它們可以幫助我們創建更準確和高效的模型並擴展模型的應用範圍。
以下是自然標籤的一些其他例子:
而關於缺乏標籤時的處理方法可以參考前一個系列文的 [Day 21] 資料標註 (2/2) — 各種標註方法 或使用遷移學習。
類別不平衡是我們常需要面對的問題,它是指在訓練資料中,某些類別的樣本數量比其他類別的樣本數量多得多。
類別不平衡會使模型的學習變得困難,原因如下:
除了在上一個系列文 [Day 10] 模型達到商業指標的挑戰 — Test set performance 的殞落 所提到的挑選正確的評估指標,還有以下幾種處理類別不平衡的常見方法:
在選擇處理類別不平衡的方法時,需要考慮具體的任務和數據集。沒有任何一種方法是萬能的。
好啦,今天就先討論到以系統設計與資料科學的角度會怎麼看待資料。
明天再來談談特徵工程的部分,明天見!

