今天要來談未來,所以是超級未來感擬人化 Ferris,越畫越放飛自我了哈哈哈
正如在這個系列文前半段提到的,Rust 是一門安全、高效的程式語言,這兩個特點是其在資料科學和 AI 領域的兩大優勢,然而最令人擔心的就是沒有圍繞著資料相關的社群。
但實際上這兩年 Databrics 的 Data and AI Summit 也開始出現了 Rust 的蹤影,例如去年就邀請到 Polars 的作者親自講解 Polars: Blazingly Fast DataFrames in Rust and Python。
我想這代表 Rust 在資料科學和 AI 領域的應用逐漸普及,而隨著應用逐漸普及,我們可以期待未來有更多優秀的資料科學和 AI 應用開發在 Rust 的幫助下誕生。
而今年由 lakeFS 共同創辦人暨技術長 Oz Katz 所演講的 Delta-rs, Apache Arrow, Polars, WASM: Is Rust the Future of Analytics? 則講述了為什麼 Rust 和相關的新技術(如 WebAssembly)將在未來幾年在資料生態系統中發揮重要作用,今天就一起來聽聽他怎麼說吧。
lakeFS 是 資料的 Git,可以使用和 Git 類似的方式對資料湖泊進行可擴展且與格式無關的版本控制。
然後吉祥物很可愛!
我相信大家對下圖中的各個縮圖並不陌生,甚至大部分的孩子可以說是專精。
這是當今最普遍會看到的資料基礎設施與工具: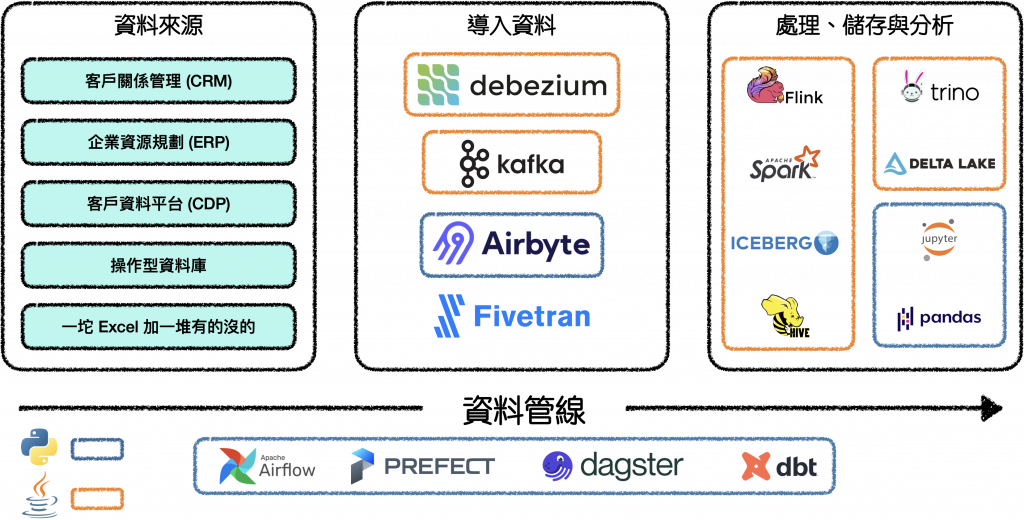
*圖片修改自 Delta-rs, Apache Arrow, Polars, WASM: Is Rust the Future of Analytics?
我們可以發現這麼多的工具卻僅與兩種語言有關:
也就是說,要在現代成為一個好的資料工程師,精通這兩種語言 (加上 SQL) 是無可避免的。
噢對,可能或許還需要會用一點 Excel:
然而,過往使這些語言紅極一時的優點,如今已成了枷鎖,舉例來說:
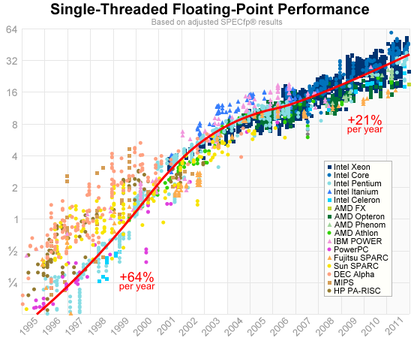
CLASSPATH 跟一堆 JAR 😛Rust 作為相對較新的語言,截長補短之下,也解決了上述的一些侷限性
另外,Rust 也具有很高的 互操作性,例如 FFI to C,或是 pyo3.rs 讓我們可以用 Rust 建構邏輯,但同時享有 Python 平易近人的 API。
在這個系列文已經多次重複提起 WebAssembly ("WASM"),而講者也對 WASM 的出現格外興奮,因為它讓人想起當年 JAVA "一次編寫,到處執行 (WORA)" 的願景:
雖然 Java 說可以在車上執行,但想像一下自駕車在千鈞一髮之際還在垃圾回收 😉
回到 Rust,它能編譯成 WebAssembly,而我們在前面的專案也做過,只需要建立一個小型且易於發佈的程式,就能在幾乎任何環境中運行。
想像一下,同一套商業邏輯能在操作型資料庫、分析引擎與使用者的瀏覽器執行有多讚?
如果資料分析能夠利用上述的優勢並採用 Rust 工具呢?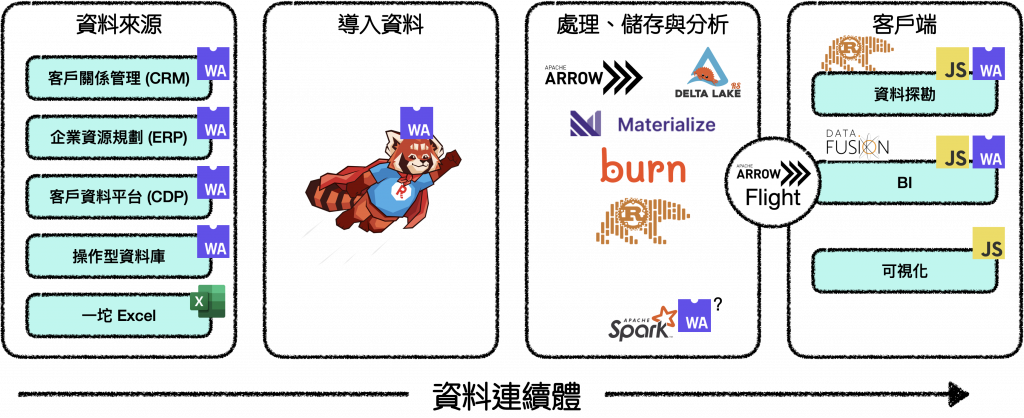
*圖片修改自 Delta-rs, Apache Arrow, Polars, WASM: Is Rust the Future of Analytics?
其中的各個縮圖分別為 (Polars 跟 DataFusion 應該是不用說再說明了):
如果我們從資料來源就利用 WASM 來讓它們 "乾淨" 一點,所有的環節都能在掌控之下,而在另一端,繁重的工作將從基於 JVM 的資料框架轉移到基於 Rust 的框架,我們可以充分的利用手邊的硬體,並且我們的 Rust 程式碼將在邊緣端 (直接在瀏覽器中) 重新用於報告或互動性的工作,是不是很棒?
也就是說,Rust 在資料科學領域的應用整體來說還是很值得期待的,不只是在速度上的提升,還有可能從根本上解決一些常見的痛點。
今天就談到這啦,最後一次,明天見!!!!


