嗨囉安安,今天是最後一天,也是一個簡單的小實作。
這次請到了ChatGPT麻麻來手把手教我們如何簡單運用現有套件來執行語音辨識(要我自己從頭開始做大概要一年)。
請大家準備好你們的Anaconda或直接開啟你的Jupyter Notebook!
這次會我們使用到Python的Speech Recognition資料庫。
在終端機執行這段程式碼來下載。(也可以在Jupyter Notebook執行)
再來還要下載可以套用麥克風的相關庫: (這邊我一開始沒裝,有其他音訊處理的庫也可以用已經有的)
可以在終端機或者Jupyter Notebook執行。
再來就是貼上程式碼並執行。
import speech_recognition as sr
import csv
def Voice_To_Text(duration=7):
r = sr.Recognizer()
with sr.Microphone() as source:
print("請開始說話:")
r.adjust_for_ambient_noise(source)
audio = r.listen(source, phrase_time_limit=duration)
try:
Text = r.recognize_google(audio, language="zh-TW")
except sr.UnknownValueError:
Text = "無法翻譯"
except sr.RequestError as e:
Text = "無法翻譯{0}".format(e)
return Text
csv_path = "output.csv"
header = ["Text"]
with open(csv_path, "w", newline="", encoding="utf-8") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(header)
for i in range(3):
Text = Voice_To_Text(10)
csv_writer.writerow([Text])
print(Text)
print("已將語音轉換結果寫入 output.csv 文件")
結果如下: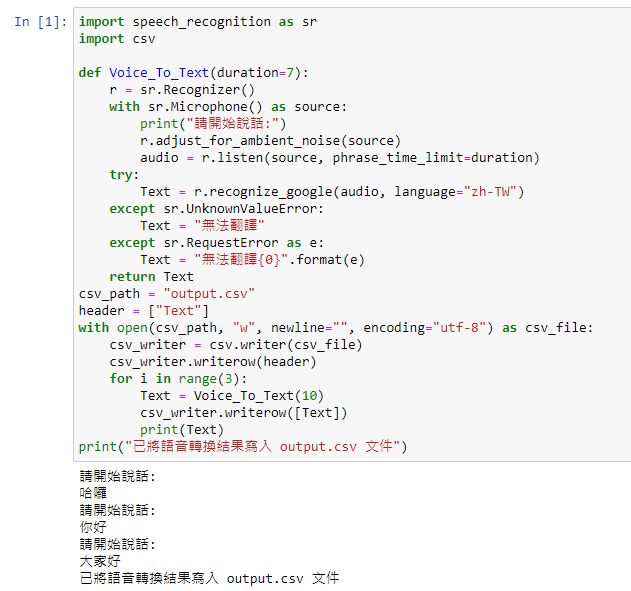
檔案會儲存起來,長這樣: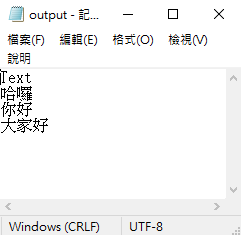
看起來非常簡單對吧! 真的超級簡單的,會卡住的地方只有我沒有裝到相關庫來處理音訊。
快去玩玩看吧!
參考書籍:Hey Siri及Ok Google原理:AI語音辨識專案真應用開發
參考網站:https://vocus.cc/article/64094bedfd897800011bdd74
學習對象:ChatGPT

