在寫 DeepLabv3 之前,先來回顧一下前面的 deepLab 系列,
當我們使用 DCNN 處理語義分割任務時,會有主要的兩個問題,第一個問題是特徵的分辨率會因連續的下採樣和池化操作而降低,換句話說,影像中的細節資訊會因此而丟失,再來是第二個問題涉及到多尺度的影像問題,不同的物體可能位於影像中的不同位置並且具有不同的尺度,因此模型需要具備處理多尺度資訊的能力,以確保對各種物體進行有效的分割,而為了解決這些問題,在之前的版本 deepLab 和 deepLabv2 中分別引入了空洞捲積和 ASPP,這些新技術的設計使模型能夠更好地處理特徵分辨率的降低和多尺度的問題
接著在 deeplabv3 中,作者重新探討了空洞捲積的使用,並跟進了一些變動
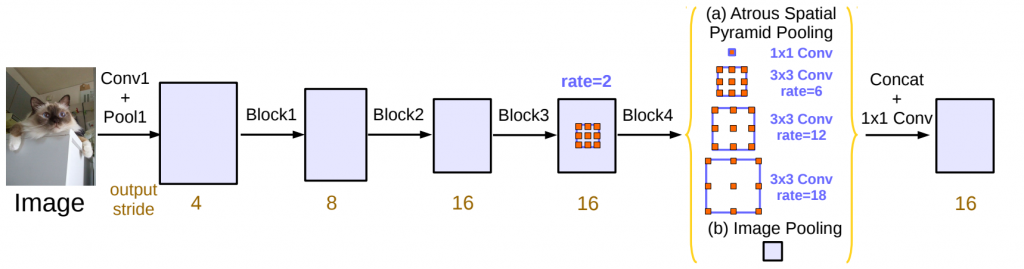
deeplabv3 將空洞捲積應用在聯級模塊中,這是 ResNet 最後的模塊,通過複製和聯級這些模塊,使得模型能夠更好地理解影像中的細節資訊
其次,在 ASPP 中使用了 Batch Normalization 層,來有助於提高模型的訓練穩定性和速度。Batch Normalization 是一種正規化技術,它可以加速模型的收斂過程,並且有助於克服深度神經網絡中的梯度消失問題
最後,deeplabv3 刪去了之前版本中使用的 CRF 層,這是一種用於後處理的技術,用來更好地平滑分割結果。deeplabv3 在不使用 CRF 的情況下實現了出色的性能,這也簡化了模型的架構。
Rethinking Atrous Convolution for Semantic Image Segmentation


 iThome鐵人賽
iThome鐵人賽