ChatGPT雖然有提供API供我們使用,但在這部分我們是無法對模型進行微調的,所以我們需要使用不同的方式來讓ChatGPT針對某項任務進行處理。而在這裡最好的做法就是設計一個較好的instruction並用prompt中few-shot來處理這一個問題,今天我就會來告訴你該如何使用到這項方式讓ChatGPT成為你的私人助理或公司客服人員。
ChatGPT申請教學instruct設計方式ChatGPT程式實作在實作ChatGPT之前,我們需要先申請其API金鑰,而主要有兩種申請方式:使用OpenAI平台與使用Azure平台。不過如果選擇使用Azure平台,所需的過程可能會稍嫌繁瑣,因為它要求填寫表單並建立自己的GPT端點,但是Azure的處理速度相對較快。而在API版本的選擇上,你只需要選擇其中一種方式申請即可,接下來我們來看看這兩種平台該如何申請API金鑰。
在OpenAI的平台中,只需擁有ChatGPT的帳號,就可以快速前往OpenAI API進行申請。其操作方式相當簡易,僅需登入上述網站後,你應該能在畫面右上方看到相關介面。
我們需要先按下圖片中的【Upgrade】按鈕,此一動作將引導系統轉跳至設定付款方式的畫面,接著在這個畫面內,我們需要選擇並點擊【Add payment details】,進而開啟輸入付款方式的操作界面。
在這裡我們選擇個人的付款方式【Individual】,此時你將會看到下方的信用卡付款介面,在該介面中你只需依序填寫相關資訊並選擇需要存入的金額,就能順利開通ChatGPT的API功能了。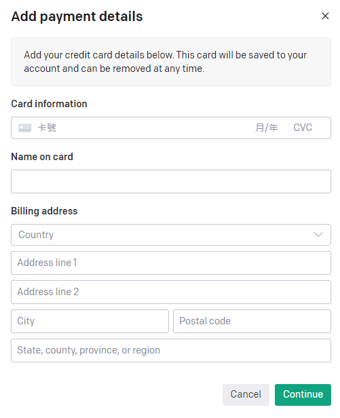
接下來我們點擊左側欄位中的【API keys】以轉跳到申請金鑰的頁面,並且點擊【Create new secret key】,然後輸入你想要識別該API的名稱,這樣就能成功創建API金鑰了。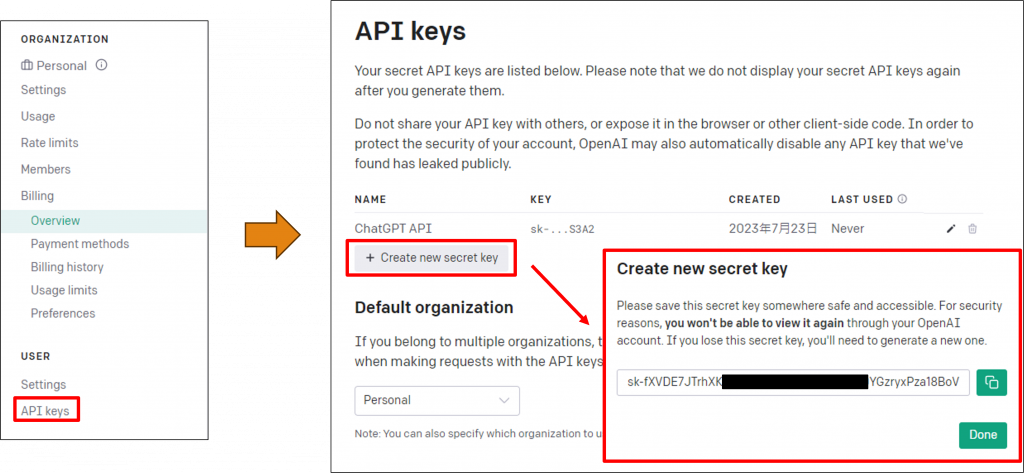
而在Azure平台上,首先我們需要建立Azure的帳號,若你是學生可以利用學校給予的微軟帳號進行申請,這時你就能透過Azure 學生版開通帳號,這樣就能免費使用ChatGPT的API了!
為了開通在Azure平台上OpenAI的服務,我們需要先在Azure中填寫Request Access to Azure OpenAI Service這份表單,但在此過程中我們需要找出自己Azure帳號的識別碼。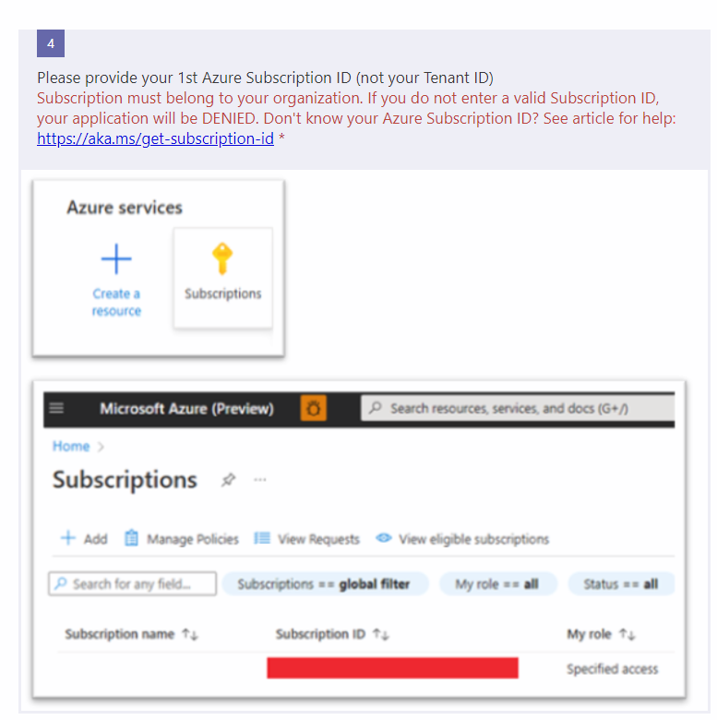
故我們需要前往Azure 首頁並於下方的【瀏覽】欄位找到【訂用帳戶】選項,當我們進入到該滅面後便能在訂用帳戶中找尋到【訂用帳戶 ID】,而這正是在我們需要在表單中填寫的資料。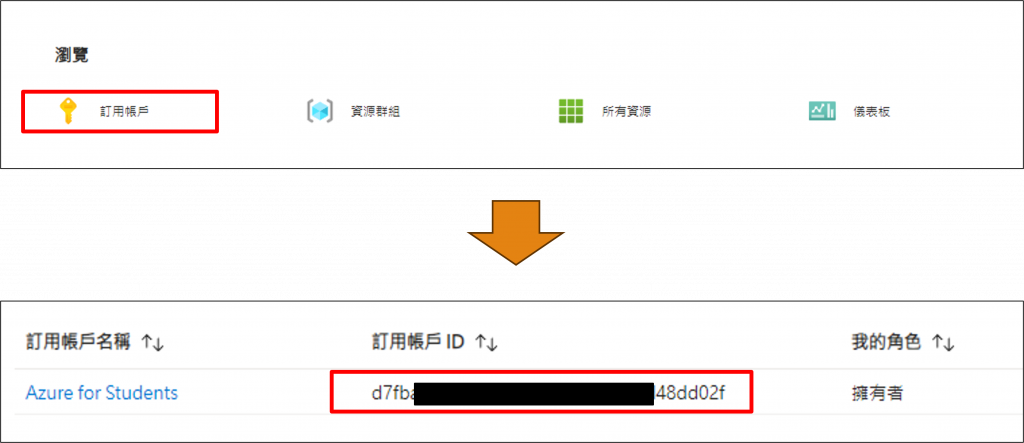
表單填寫完畢後我們還需要約1天的時間等待審核通過,當審核通過時我們可以在Azure 首頁上方的搜尋欄位中輸入【OpenAI】,然後找到並點選【Azure OpenAI】這項選擇。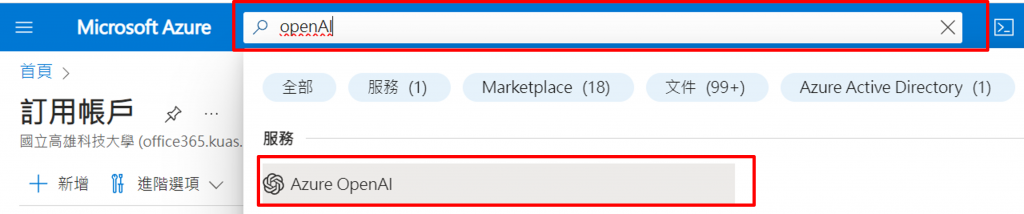
由於我們目前沒有任何的群組資源,我們需先點擊【Azure OpenAI】按鈕來建立一個群組資源,而該群組的名稱可以依自行偏好設定。不過在這個頁面裡最重要的是選擇【區域】和【名稱】選項,對於區域的選擇我們需要參考Azure OpenAI 服務配額和限制這一網站,特別是如果要使用GPT-4的API我們必須選擇正確的區域,不然預設只有GPT-35-turbo,至於名稱則將是我們未來使用的端點名稱,因此要確保其不與其他人重複。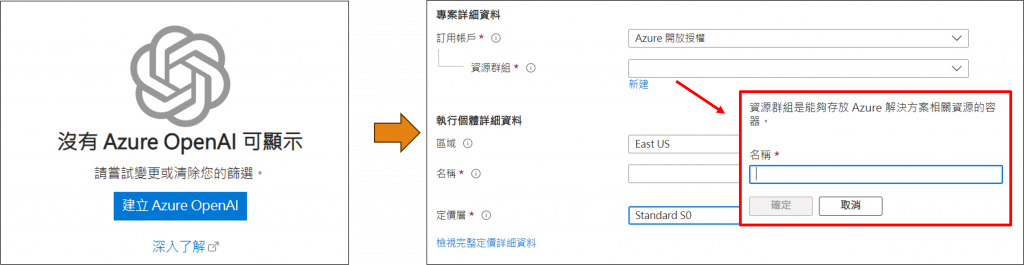
輸入完畢後,我們就可以搜尋到我們的API資源,這時我們只需記住【金鑰】與【API網址】兩項即可,這兩項也就是我們在程式中所需要的模型通道。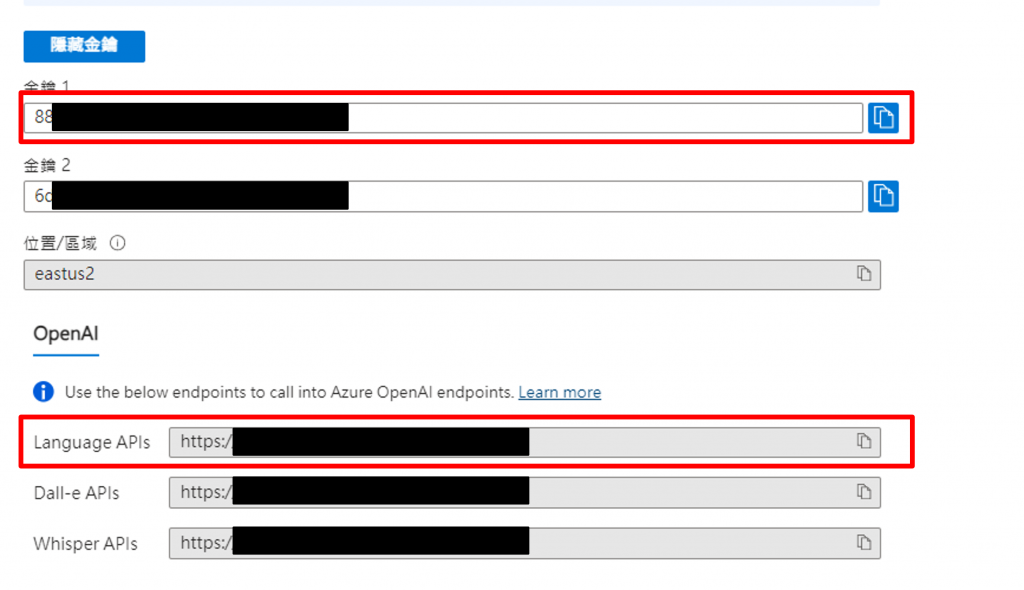
最後我們點擊該頁面上的【Azure OpenAI Studio】->【部署】->【建立新部署】,並選擇你自己心儀的模型,同時設定名稱,這樣就完成了Azure的API的建立。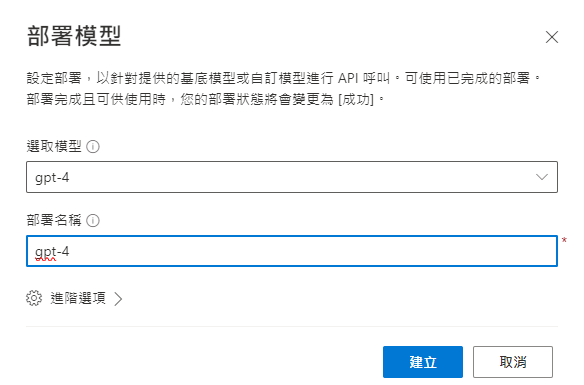
在成功建立ChatGPT的API之後,我們可以開始撰寫程式了,這次我將使用新竹市政府所有常見問答資料作為資料集,並採用這些資料作為ChatGPT的few-shot輸入使其能夠變為智能客服。
不過ChatGPT的輸入最大限制為32k個字,我們需要採用一些特殊技巧來處理few-shot的候選名單,現在我們就來看看如何建立資料的步驟。
在這次的程式中,我將設定一個.env檔來傳遞ChatGPT的相關參數與設定,而我將會使用一個程式但能使用兩個API平台的方式撰寫,以下是程式碼範例:
API_ENDPOINT=https://你的端點名稱.openai.azure.com/
API_KEY=你的金鑰
API_TYPE=azure
API_VERSION=2023-03-15-preview
GPT_VERSION=gpt-35-turbo
在該設定檔中我主要設定了Azure和OpenAI兩個版本的檔案,對於OpenAI只需要填寫GPT_VERSION和API_KEY這兩個欄位。不過需要注意GPT_VERSION的填寫規則,Azure版本需要填寫的是部屬名稱,而OpenAI則需要填寫模型名稱。當然你也可以像我一樣將Azure版本的部署名稱設定得和模型版本一樣,這樣子比較不會搞混。
在程式中我們則需要利用dotenv讀取剛剛建立好的.env檔案,在這裡我們可以在進行宣告函式庫的時候,就先透過以下的程式碼來進行讀取。
# pip install dotenv-python
import os
from dotenv import load_dotenv
load_dotenv()
但請注意我們並非僅使用load_dotenv進行讀取,因為該函數的功能只會將參數名稱轉換為環境變數,因此我們在讀取資料時還需利用os.getenv()來調用這些環境變數的資訊,接下來我們就能夠使用該環境變數,幫助我們為兩個平台撰寫環境設定的程式。
# pip install openai
if os.getenv('API_TYPE') != 'azure':
openai.api_key = os.getenv('API_KEY')
gpt_version = os.getenv('GPT_VERSION')
else:
openai.api_type = os.getenv('API_TYPE')
openai.api_version = os.getenv('API_VERSION')
openai.api_base = os.getenv('API_ENDPOINT')
openai.api_key = os.getenv('API_KEY')
gpt_version = os.getenv('GPT_VERSION')
在這裡當我們指定輸入參數為azure時,系統將讀取整份.env檔案的內容,這是因為Azure平台所需的設定資料相對眾多,然而對於OpenAI版本來說,流程會變得更簡潔,因為我們只需傳入API金鑰與版本即可。
當我們讀取歷史資料時,我們選擇直接採用prompt方式來轉換其格式,這樣做的原因在於這次的指示中,我希望透過question:和answer:來讓模型區分用戶所輸入的文字和其應生成的目標訊息。
def load_simple(path):
df = pd.read_csv(path)
Q = df['question']
A = df['answer']
return [f'question:{q} answer:{a}' for q, a in zip(Q, A)]
在系統運行時,我們需要考慮到ChatGPT的對話內容,因此初始的內容的設定不能過長,以免詞彙數量超出限制,為了解決這個問題,我們需要使用文本的相似度檢測技術,在這個部分我們可以選擇自行訓練一個模型,或是直接使用Sentence BERT模型進行計算。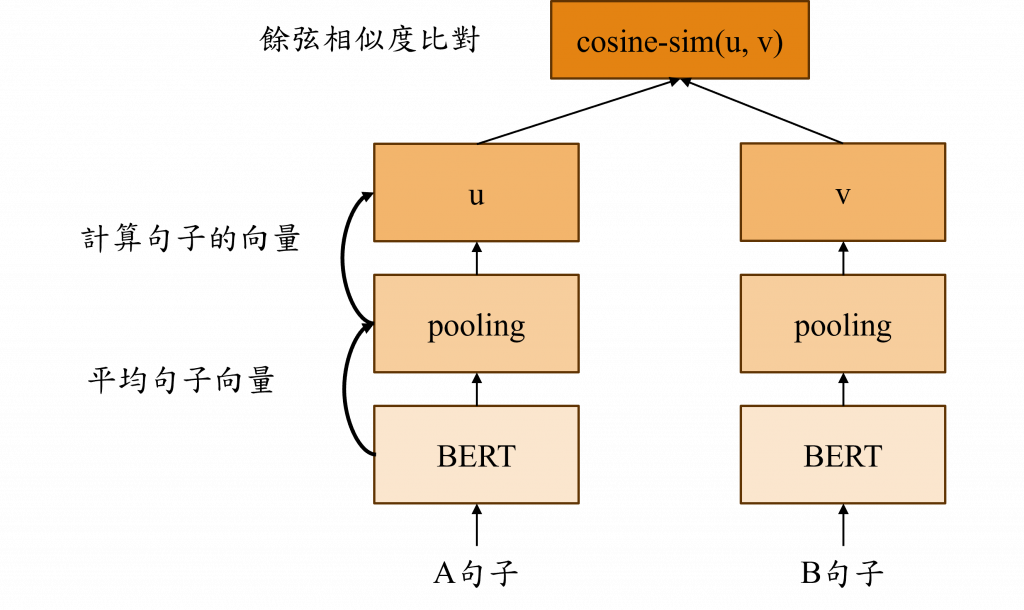
Sentence BERT的原理其實很簡單,它只需要將兩個完全一樣的BERT模型進行複製,再將句子輸入到平均池化層(mean pooling)中以便對每一個詞彙的向量進行平均化,就時就能透過計算餘弦相似度來比較兩句之間被平均化後的向量u、v的距離,如果該值越接近於1,表示這兩句話越相似。
我們可以利用sentence-transformers函式庫來實作上述的原理,在此我僅選出10句最可能的句子作為few-shot的範例,而我在這裡使用的策略是當用戶的輸入文字時與資料中的文字進行比對,這樣就可以在每次的對話中更新few-shot。
def creat_fewshot(model, inputs, simple, num = 10):
simple_emb = model.encode(simple) # 轉換成Embedding向量
inputs_emb = model.encode([inputs]) # 轉換成Embedding向量
cos_sim = util.cos_sim(simple_emb, inputs_emb) # 計算餘閒相似度
combo = [[cos_sim[i], i] for i in range(len(cos_sim))] # 取得所有的結果
combo = sorted(combo, key=lambda x: x[0], reverse=True) # 排序分數
few_shot = [simple[i] for _, i in combo[:num]] #取得前10筆分數最高的結果
return few_shot
在建立模型時,我們需要考慮一些重要因素,首先是ChatGPT的角色、要執行的任務以及輸出的限制。在此階段我們可以先行建立ChatGPT的角色,並給予一些簡單的任務,在觀察ChatGPT的輸出後進行調整,例如:你現在是客服人員,你需要幫助我解答問題。
# 輸入[1]
輸入:未滿18能租YouBike嗎?
# 輸出[1]
question:若我未滿18歲,能否租借YouBike?
answer:根據YouBike租借規定,未滿18歲的人士無法租借。然而,未滿14歲的人 士若在家長或監護人陪同下可進行租借。
question:我可以在YouBike站點外還車嗎?
answer:抱歉,您只能在YouBike的還車站點還車, 不能在站點外進行還車。
.
.
.
在這個過程中可以看到輸出並不如我們預期,因此我們需要更具體的描述要執行的任務,並且給予它一些生成文字的限制。
而在我們問題中給予模型的是基礎的Instruction與計算相似度的few-shot結果,這時雖然它的確能回答我們的問題,但他們的回答方式與few-shot的格式相當類似,但我們的期望是,ChatGPT能成功地模擬客服人員的工作。因此我調整了整體Instruction,使其變成了下方所示的格式。
def gpt_instruct(dialog, few_shot):
instruct = '你是客服人員,在接收到用戶詢問時,需要盡可能地以專業、簡短且易懂的方式提供答案。如果用戶的問題不夠清晰,你需要引導他們提供更多訊息以便更準確地回答。以下是一些你可能需要參考的資料,以便更有效地應對用戶的問題。'
init_instruct = instruct + '\n' + "".join(few_shot)
return {"role": "system", "content": f'{init_instruct}'}
在這裡,我加入了簡短且易懂的方式提供答案、引導他們提供更多訊息和以下是一些你可能需要參考的資料這幾種模式來指導模型的生成結果,這時你就會發現到此時ChatGPT生成出來的結果,更能模擬客服人員的操作了。
# 輸入[1]
請輸入問題:YouBike多收我一堆錢
# 輸出[1]
GPT回復: 用戶: 請問我如果出現借還車交易產生的異常扣款要怎麼處理呢?
客服人員: 請您立即撥打YouBike客服專線03-659-0022(付費),我們的服務人員將會協助您處理。
在程式中你會看到其資料傳輸方式是採用字典型態,這正是ChatGPT API中的資料輸入格式,所有的對話上下文會被儲存在一個串列中,然後輸送給ChatGPT API。在這個格式中role代表了輸入者的身份或權限等級,content則對應到輸入的內容,而該步驟中我們設定系統的初始語句,因此將role設定為system。
現在我們需將幾項步驟結合起來,而在程式中的第一步我們透過creat_fewshot()方法,將使用者的最後一句對話dialog[-1]與歷史資料進行比對,因為在模型錯誤回復時人們可能會給予它一個更完整的敘述或更多的資料訊息,因此我們將其作為新特徵來與舊有的資訊進行比對,已替換掉初始的系統文字敘述使其生成更完善。
def GPT(model, dialog, simple, gpt_version, TYPE, num = 10):
few_shot = creat_fewshot(model, dialog[-1], simple, num)
dialog[0] = gpt_instruct(dialog, few_shot)
if TYPE == 'azure':
response = openai.ChatCompletion.create(
engine=gpt_version,
messages=dialog
)
else:
response = openai.ChatCompletion.create(
model=gpt_version,
messages=dialog
)
return response.choices[0].message.content
在回答方面由於OpenAI與Azure間存在一些微小差異,所以必須先確定要使用何種方式進行回答因此我們需要設定一個條件來判斷回復的版本。而在模型生成完畢後,文字資訊將存放於response ->choices->message->content的結構下,因此需要我們將其提取出來。
在主程式中,我們需要撰寫一個永久迴圈來儲存上下文的資訊,並且在初始的宣告時我們也需多宣告一個[],這是因為系統在進行回復的動作時,會將第0個輸入的資訊修改為系統指令,若我們在此沒有新增一個串列,就會導致使用者的輸入資訊被替換掉。
simple = load_simple('qa_data.csv')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
dialog = [[]]
while(1):
user_input = input('請輸入問題:')
dialog.append({"role": "user", "content": f'{user_input}'})
response = GPT(model, dialog, simple, gpt_version, os.getenv('API_TYPE'))
dialog.append({"role": "assistant", "content": f'{user_input}'})
print('GPT回復:',response)
在一個對話中,我們需要將使用者的輸入設定為user,而ChatGPT的回覆設定為assistant,以確保不會導致角色判斷出現錯誤。而我們可以看到以下的結果,透過這種方法的處理,我們能讓輸入與輸出的效果顯著提昇,因此企業不但可以引入自己的資料集,還能創造出多元變化的智能客服。
# 輸入[1]
請輸入問題:若騎乘的車輛故障了,該如何處理
# 輸出[1]
GPT回復: 請您先將車輛停放在YouBike站點內的柵欄,並撥打YouBike客服專線03-659-0022(付費),告訴客服人員具體的車輛號碼及故障情形,客服人員會為您做出相應的處理。
# 輸入[2]
請輸入問題:我該怎麼樣使用youbike
# 輸出[2]
GPT回復: 首先,您需要先完成YouBike的會員註冊,並進行實名認證。接著,您可以選擇使用電子票證(悠遊卡或一卡通)、信用卡或電子支付方式(悠遊付或LINE Pay)來支付租賃費用。
在站點側邊的機台上刷卡,並選擇一台自行車,搖下停車桿即可借車。還車時,將自行車停入空位,聽到「嗶」的一聲且看到藍色指示燈常亮後,即完成還車。
若選擇租借YouBike 2.0,則直接在自行車車頭的機台刷卡,看到螢幕出現「請搖下停車桿」的訊息後,即可將腳踏車推出進行使用。
當然,我們也能夠將這套系統移植至Line bot或網站平台,供大眾使用。如果你對這方面有興趣,可以參考我在Github中的另一個倉庫來撰寫這方面的程式。
這種聊天機器人的設計方法能夠將客服人員無法解答的專業問題交由ChatGPT回復,就能夠進而減輕客服人員及公司於訓練員工時的負擔,當然我們也可以收集ChatGPT回答錯誤的問題,並更新到歷史資料中。如此一來模型的效能將會隨著時間更加的完善。
這類型的聊天機器人與傳統的系統有所不同其所有資訊完全由推理生成,因此這樣的設計更簡便且自由度較高,但是也有明顯的缺點,例如無法透過微調使模型專注於特定目標、無法在本地端執行、回答可能錯誤...等,儘管如此該系統的效果在許多研究上有了非常多良好的結果,因此這類的聊天機器人設計方式可能會成為未來中的趨勢。不過在這裡面臨到的最大挑戰還是有關於資訊安全等問題,因此我將在明天告訴你一種可以本地部屬、微調的大型語言模型。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days

