我們常在與ChatGPT相關的文章中看到prompt、instruction、RLHF等名詞,而這些技術在ChatGPT中擔任相當重要的角,今天我們就要來探討這些ChatGPT中的名詞與技術,但我們在介紹前我們需要了解instructGPT這一項GPT的前身,今天的學習重點如下:
InstructGPT/ChatGPT的原理Prompt與Instruction的差別RLHF的實際用處與介紹InstructGPT是基於微調GPT-3的語言模型,它的出現是為了改變GPT-3可能會回復一些產生攻擊性或是隱私文章,並且增加GPT-3的效能,讓使用者可以提出問題或提出具體的指令,讓機器能針對這些需求進行特定領域的回覆,至於該技術的核心,便是名為Instruction learning的學習方式,這種方式會在輸入的文字中增加一些指導性信息來提供給模型學習,雖然其概念與GPT-3的Prompt learning相似,但實質上兩者其實存在差別,下面我將為你深度解析這兩者的差異。
在【Day 24】用暴力美學屹立於不敗之地(上) - GPT家族的霸道之路中,我們已討論過GPT-3中的Prompt learning方式,其方式的主要目的在於提升模型的填空能力。例如在昨天的實作過程中,我們在進行問答QA的微調時,會設定輸入格式context:內容、question:問題、answer:答案就是一種Prompt learning的方法。
此目的在於進行文字生成時,當模型生成到answer:這一個詞彙時,能夠繼續根據歷史的紀錄生成下一個文字的結果,以便推理出答案。當然我們也可以在輸入中使用few-shot的方式來讓模型推理的更精確,而這種作法也都屬於Prompt learning的範疇。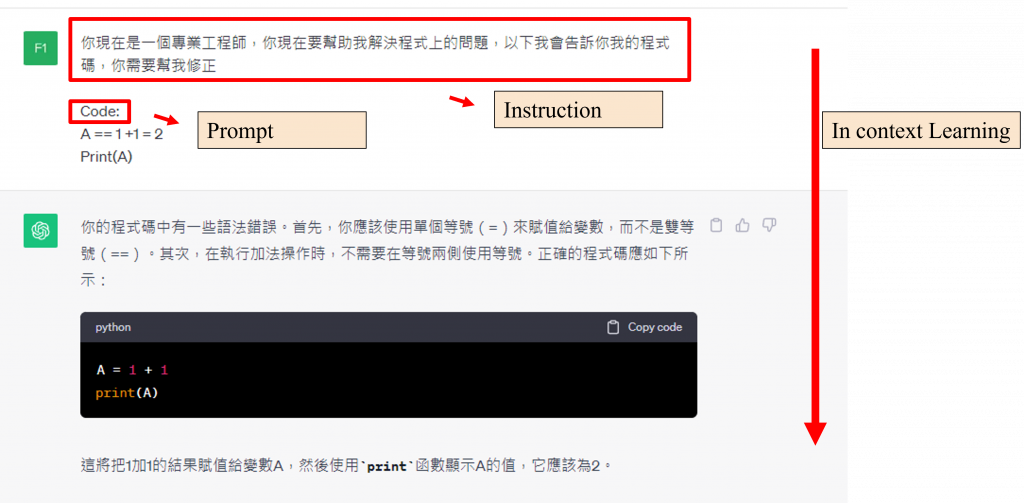
而Instruction learning的目的則在於激發語言模型的理解能力,透過提供更明確的指示,模型就能產生合適的回應,這就是我昨天在微調GPT-J時為何要將 「Read the context and question to find the correct answer」 這段文字加到輸入的原因,因為我期望模型根據這段文字進行適當的推理來得出答案。
當然有了訓練的方式我們還是需要一些方式來優化模型,而RLHF(Reinforcement Learning with Human Feedback)這項技術就是利用人類反饋來提升機器學習模型性能的技術。簡單來說這項技術就是讓我們根據模型輸出結果的來進行評判好壞,如果模型的生成效果不理想,我們可以實施懲罰機制讓模型調整權重,反之則設立一個獎勵機制。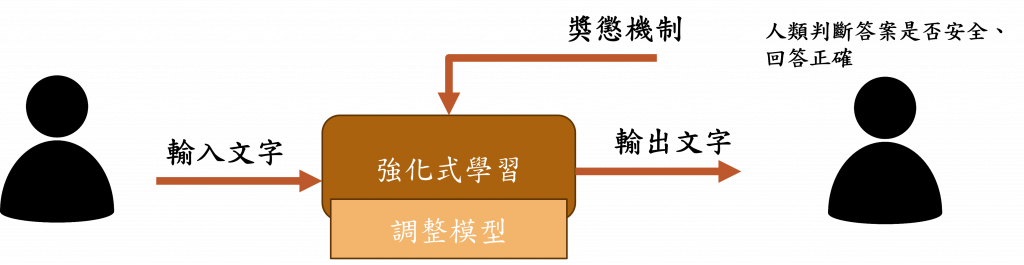
在這個過程中我們還設置了特定的懲罰機制,對於不應該被生成的危險內容進行懲罰,當生成內容為色情、暴力、違法等問題時,我們將會給予模型一個較低的評分,通過這樣的調整讓模型能避免生成這些不被人喜歡的內容。
而這樣運用了Instruction learning、Prompt learning、以及RLHF三種技術的結合來調整GPT-3模型,使得InstructGPT變得更無害且其生成能力更強。
而ChatGPT便是透過這樣的方式訓練而成的模型,在OpenAI的官網中有4個模型是採用InstructGPT方式來微調GPT-3的結果,目前能夠被稱為GPT3.5的版本包括:
code-davinci-002(InstructGPT 模型)text-davinci-002(改進版的code-davinci-002)text-davinci-003(改進版的text-davinci-002)GPT-3.5-turbo(針對聊天版的GPT模型)在這些版本中,GPT-3.5-turbo是我們在ChatGPT網站上所使用的免費版本,並且ChatGPT的生成能力也是我們有目共睹的,然而這種強大的力量並非僅源於訓練的方法。回想GPT家族所採用的訓練方式,就會發現其強大來源於更龐大的模型參數以及更多的訓練資料,儘管有許多文章推測ChatGPT模型的參數量已經達到兆的級別,但官方至今並未公開該模型的實際參數量,但以往常的訓練方式應該八九不離十了。
但如此龐大的模型在訓練或微調時固然需耗費大量時間與金額,因此微軟成為OpenAI的主要贊助商,所以在微軟的產品中,我們時常能看到ChatGPT的蹤影。當然要運用此模型,亦需有強大的硬體支援,因此我們可以推算出OpenAI在營運ChatGPT這個網站上的投入金額。
不過他們營運網站的最大目的很可能是透過我們這些用戶來進行RLHF的訓練,並且「有可能」私下蒐集我們傳入的這些文本資料,雖然這部分並未被證實,但我們在使用時仍需要特別留意,不應該將個人隱私或公司機密資訊散露其中。
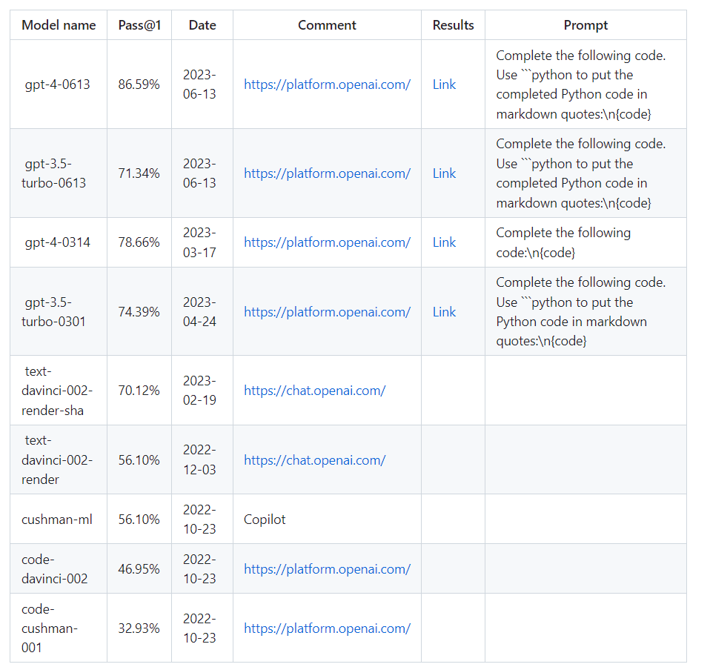
當然對於ChatGPT的能力有多厲害,許多研究已經如火如荼的開始進行測試,在GitHub上,有一個公開倉庫專門用於統計ChatGPT的準確率,這個倉庫是利用HumanEval資料集進行測試的,該測試數據集包含了164個程式問題,並探討不同版本的準確率。其中GPT-4的最新穩定版可以解決86.59%的問題,這個成績甚至能媲美大多數的程式開發人員。而經過大量的期刊與文獻測試大多數的結論都確定了GPT-4是當代最強大的SOTA模型。
然而在網站版本的ChatGPT中,其權重會持續被修正,因此對於網站版本的效能評估相當困難,於是我們在進行此類研究時,通常會參考0317和0613這兩個版本的ChatGPT,因為在公開的ChatGPT API中,我們只能選用這兩個版本。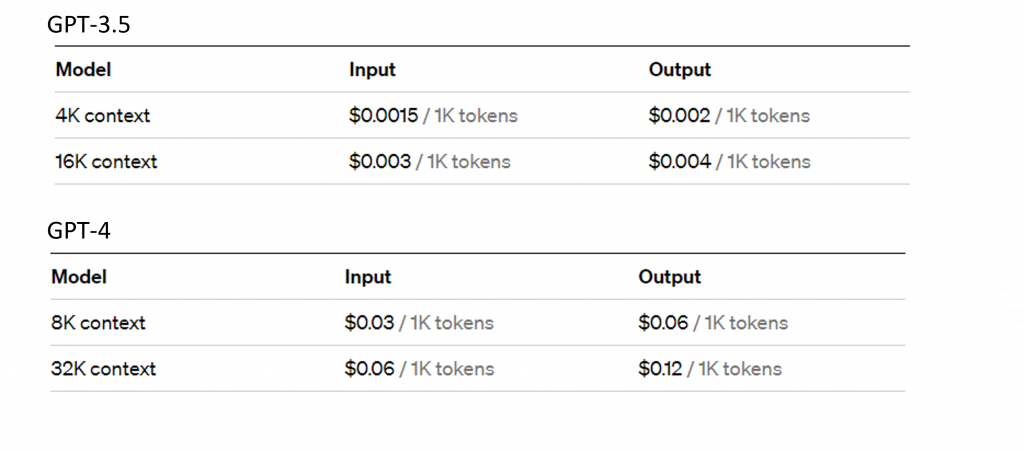
圖片來源:https://openai.com/pricing
事實上市場上已經有許多利用這些API開發完成的程式,例如:ChatPDF、ChatPaper等都是運用此技術開發出來的。而API的花費與ChatGPT的模型運作成本相比,其API的價格相對低廉,模型輸出每1000個詞彙的花費僅為0.002美元這一點非常適合用於企業的營運上。
我們現在可以在Azure平台中使用GPT的各種模型,由於微軟所擁有的設備較OpenAI優良因此回應的速度更快,每分鐘的處理流量也更高。而且對於學生來說,微軟還提供了100美金的免費額度,讓我們能夠體驗到使用GPT模型的便利。
現在你應該對ChatGPT的運作原理有更深的瞭解了,而我們在這類大型語言麼型所需要學習的就是如何透過Instruction learning以及Prompt learning來優化它的文字生成效果,因此我會在明天先教你如何申請ChatGPT的API,並教你如何撰寫一個較佳的Instruction和Prompt並通過程式碼實作讓ChatGPT能成為你的私人小幫手或者幫助企業完成特定的任務。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days

