當大家都依靠 Observability 確保服務品質時,我們能保證他們一定永遠健康強壯嗎?如果連確保系統運作正常的機制也壞掉了,那我們還能知道問題發生了嗎?這也是為什麼大部分負責收集與儲存資料工作的 Observability 工具都會強調他們具備 「可擴展性(Scalability)」與「高可用性(High Availability, HA)」。這兩個特性在微服務架構的設計中佔有關鍵地位,因為它們直接影響服務性能和使用者體驗。
Observability 工具不僅需要監控正在運行的服務,也需要隨著系統變化靈活地擴展,以確保在各種狀況下都能提供穩定的服務。
在微服務架構中,可擴展性常常是透過水平擴展(Horizontal Scaling)來實現,也就是增加機器或實例(Instance)數量。與之相對的是垂直擴展(Vertical Scaling),也就是增加單一硬體的配置(如CPU、記憶體、硬碟等),很容易受限於物理條件。水平擴展的前提是,資料的讀取與寫入機制必須從一開始就設計為可擴展的,否則可能會遇到資料不一致的問題。
為了提高服務的可擴展性,操作資料的微服務架構通常分為寫入(Write)和讀取(Read)兩類型。依照不同應用場景,讀寫效能的需求也會有所不同。最常用的技巧是命令查詢責任區隔(Command Query Responsibility Segregation, CQRS)。通過 CQRS,寫入和讀取負責的服務可以分開,並根據各自的需求進行擴展,可以更精準的將資源應用在實際需求上。
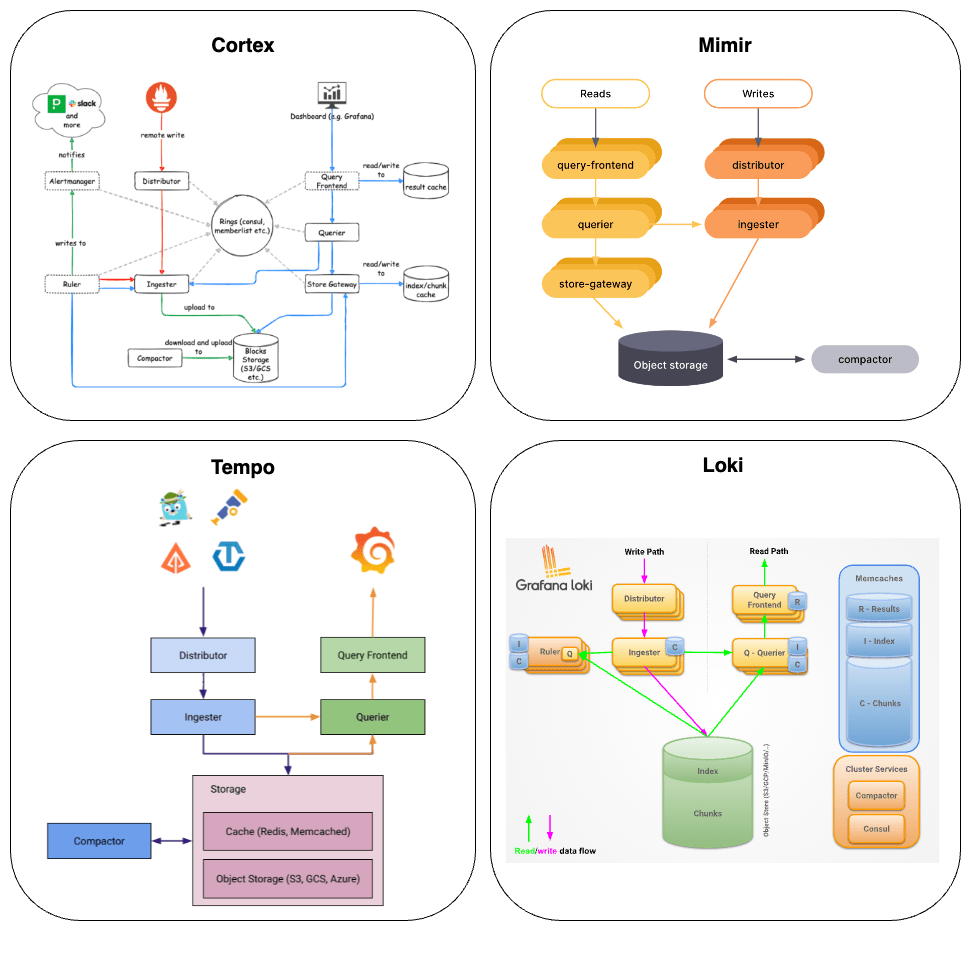
Grafana 旗下的 Loki、Mimir、Tempo 都承襲了 Cortex 的架構設計,將資料流分為寫入(Write)與讀取(Read)兩大類,各由不同的 Component 負責。透過對這些 Component 進行擴展,即可有效提升系統效能。以下為 Cortex、Loki、Mimir 和 Tempo 的架構圖比對:
觀察以上四種服務,可以看到主要讀寫路徑的 Components 名字都一樣:
透過讀寫 Components 的拆分,讓這個架構能夠適應不同使用者需求,Loki、Mimir 和 Tempo 各自提供三種不同的佈署模式:
詳細的 Component 介紹與部署方式差別,可以參考官方文件中各工具的 Components 與 Deployment modes 章節。
若選擇使用 Microservices Mode,基本上會搭配 Kubernetes 使用。官方為不同佈署模式也提供了對應的 Helm Chart,只需根據需求選擇和調整,即可快速建立服務。
Helm Chart 一覽:
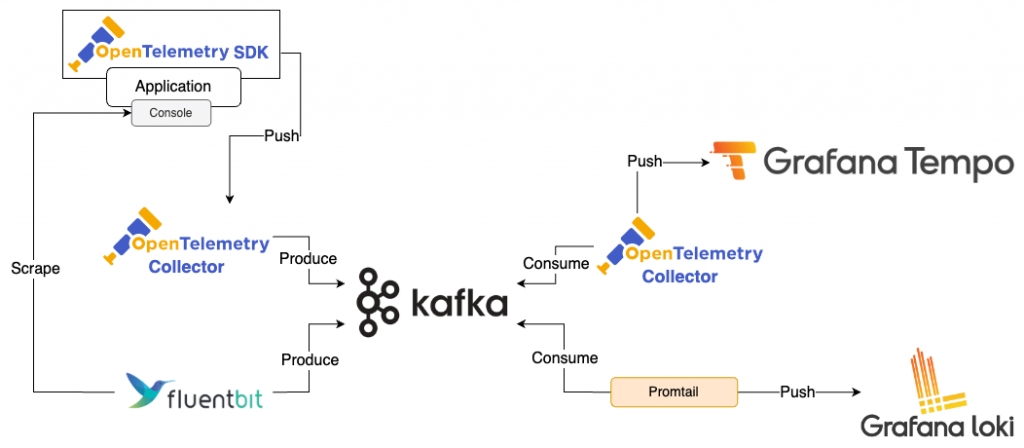
singleBinary 參數選擇 Monolithic Mode 或 Scalable Monolithic Mode。Kafka 能夠提供 Message Queue 服務。在微服務架構下,它可以作為資料的緩衝區。當資料量過大時,Kafka 先行接收資料,再由 Consumer 逐一消耗處理,如此可防止因資料過量而讓服務變得不可用。
以 Traces 或 Logs 收集為例,可以透過 OpenTelemetry Collector 或 Fluent Bit 先將資料寫入 Kafka,再用 OpenTelemetry Collector 和 Promtail 讀取並寫入 Tempo 和 Loki。這種方法可預防 Loki 或 Tempo 的組件因資料過量而導致服務不可用。儘管可能有延遲問題,但 Traces 與 Logs 對於即時性的要求並不高,輕微延遲的延遲相對可以接受,就無需因短暫的大流量進行 Scaling。
Jaeger 原生也有支援 Kafka 模式。在這種模式下,Jaeger Collector 不再直接寫入 Storage Backend,而是先將資料寫入 Kafka,再由 Jaeger Ingester 讀取 Kafka 的資料,最後寫入 Storage Backend。
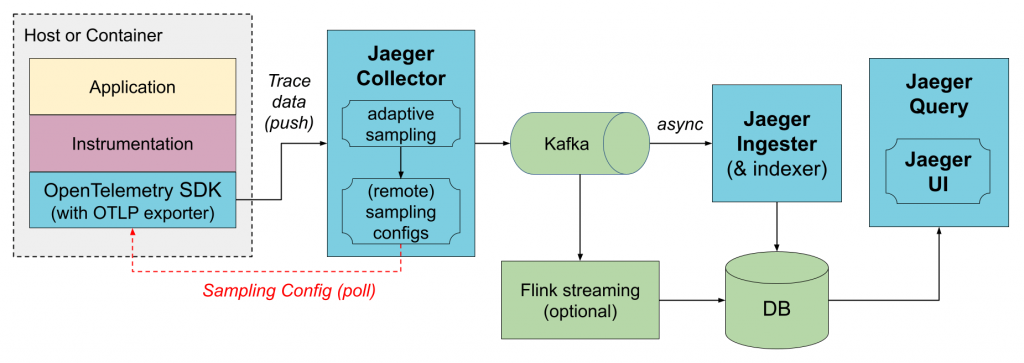
圖片來源:Jaeger
微服務架構中的服務通常被預設為是可能會發生故障的,因此透過架構設計讓服務可以承受部分服務失效,但仍可以正常運行就是高可用性(High Availability, HA)要解決的問題。
達成 HA 的一個簡單方法是選擇本身支援 HA 的工具,或是依照工具文件中的 HA 部署方式。以 Prometheus 為例,可透過多個 Prometheus Server 收集資料,並搭配 Mimir 進行資料儲存,以防單一 Prometheus Server 故障導致資料遺失。
除了架構本身就支援 HA 外,還是要確保服務真的是可用的,所以也需要一視同仁,用照顧其他服務的方式一樣照顧我們的 Observability 工具,蒐集它們的 Metrics 和 Logs,再搭配告警通知,確保使用者都能夠正常使用 Observability 工具。大多數工具都有內建監控機制或提供指標,例如 Fluent Bit 的 Monitoring 和 OpenTelemetry Collector 的 Telemetry 資訊。除此之外,Loki、Tempo 和 Mimir 不僅提供指標,官方文件中也有各種 Dashboard 或是 Runbook 等,這些都有助於確保服務的可用性。
範例程式碼:28-scalability
啟動所有服務
docker-compose up -d
檢視服務
loki/supersecret
admin/admin
使用 k6 發送 Request
k6 run --vus 1 --duration 300s k6-script.js
使用 Explore 檢視 Loki 資料
關閉所有服務
docker-compose down
啟動所有服務
docker-compose -f docker-compose.jaeger.yaml up -d
檢視服務
因 Kafka 需要一些時間初始化,確認 Kafka 已啟動後,再繼續下一步
docker-compose ps
Jaeger UI: http://localhost:16686
關閉所有服務
docker-compose -f docker-compose.jaeger.yaml down
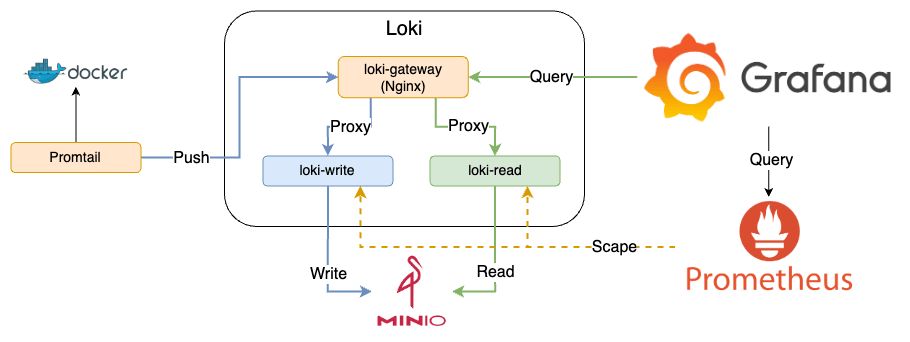
藍色線為 Write,綠色線為 Read
logging=promtail 的 Container 的 Log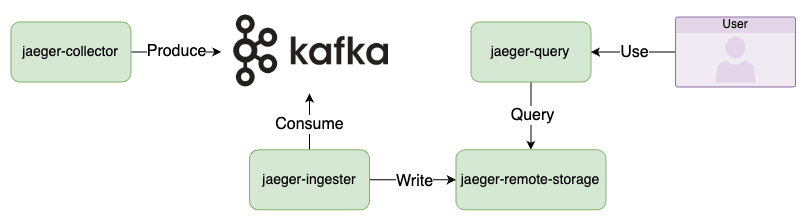
如果導入一切順利 Observability 工具無疑是確保其他服務運作無虞的關鍵。然而,若這些 Observability 工具自身無法提供穩定的服務,它們將反而成為監控機制的單點故障(single point of failure)。這種情況顯然是我們不願見到的,因此,這些工具不僅需要高度的可用性,也必須具有良好的可擴充性。
就如同「吃自己的狗糧」(eating your own dog food),Observability 不僅要能確保其他服務的品質,更應用同的工具與機制對 Observability 工具自身給予更高的服品質標準。透過這樣的全方位守護,我們才能真正確保服務都被良好的監控與管理著。