終於進入總結篇,首先回顧過去一個月所涵蓋的主題:
在各篇的 Lab 中,不僅學習了如何操作這些工具,文章也探討了多項概念、開發背景和有趣的小知識。例如,Object Storage 能大幅削減儲存成本;資料收集工具的流程不外乎就是輸入、處理和輸出三個主要步驟;以及 Grafana、Loki、Mimir、Tempo 等工具的設計理念都受到 Prometheus 和 Cortex 的影響等。
| Metrics | Logs | Traces | Profiles | |
|---|---|---|---|---|
| 生成 | eBPF, Prometheus Client, Proemtheus Exporter, StatsD Client | Application | eBPF, OpenTelemetry SDK | eBPF, Pyroscope |
| 收集 | Fluent Bit, Grafana Agent, OpenTelemetry Collector, Prometheus, StatsD, Vector | Fluent Bit, Grafana Agent, OpenTelemetry Collector, Vector | Fluent Bit, Grafana Agent, OpenTelemetry Collector, Vector | Grafana Agent, Pyroscope |
| 儲存 | Cortex, Mimir, Prometheus, Thanos | Loki | Jaeger, Tempo | Pyroscope |
| 使用 | Grafana, Zabbix | Grafana | Grafana, Jaeger | Grafana, Pyroscope |
基本上,資訊的處理過程可以簡化為四個主要步驟:
瞭解了這些工具的特性和概念後,我們就能根據自身需求自由搭配組合。比如,選用了 Grafana 全家餐的 LGTM 也能再加入不同的資料收集器,例如搭配 Fluent Bit 或 Vector 進行日誌收集,或是用 OpenTelemetry Collector 進行 Trace 資料的額外加工。這就像是玩樂高一樣,簡單自由地堆疊出符合需求的 Observability Stack,了解更多工具就能搭配得更加得心應手。
許多人一聽到 CNCF 通常首先會想到 Kubernetes 和相關的 Container 技術。然而,Observability 在 CNCF 中也佔有重要地位。像是 Prometheus 就是緊接在 Kubernetes 之後成為 CNCF 的第二個專案,我們介紹的很多 Observability 工具也同樣是 CNCF 專案,例如:Jaeger、OpenTelemetry、Thanos、Cortex 等。這主要是因為在服務部署完成後,確保其穩定運行並創造價值的重要性,與選用何種部署技術同等重要。
當開源專案被納入 CNCF 旗下,成為 CNCF 專案後,必須要確保專案保持廠商中立。這對於選擇工具時是一個很重要的考量,能夠避免被廠商鎖定落入養套殺的窘境。此外 CNCF 也會提供各種資源讓專案能夠發展的更好,例如專案管理、行銷、資安審計、法律顧問等,詳細提供資源可參考 Services for CNCF Projects。這些規範與資源都能夠讓專案更加健全完善,也讓使用者更加安心,無需擔心專案會因各種原因而中斷維護。
CNCF 將其下屬專案分為三個發展階段,由低至高依序為「Sandbox(沙箱)」、「Incubating(孵化)」和「Graduated(畢業)」。根據專案的成熟度以及社群活躍度等能夠逐步晉升成更成熟的專案,越成熟的專案 CNCF 也會投注更多資源協助管理與發展。因此,在選擇工具時,若剛好是 CNCF 專案也可以參考該工具所屬的類別作為評估依據之一。
在 CNCF 的 Observability Whitepaper 中將過去常用的 Three Pillars of Observability:Metrics、Logs、Traces,建議將這些統稱為 Observability Signals,原因是能提供 Observability 的資訊不僅限於這三種。例如,Profiles 與 Dumps 等也可以作為 Observability Signal,讓未來也可以擴充更多不同的資訊融入 Observability 的架構當中。
Jaeger 的創作者 Yuri Shkuro 在 2022 年發表了一篇題為「TEMPLE: Six Pillars of Observability」 的文章。在這篇文章中,他也擴充了原有的三種 Signals 至六種,簡稱為 TEMPLE:
Traces:分散式追蹤,專注於不同服務間調用的順序與關係。
Events:系統外部變更事件,如服務佈署、設定變更等,其會對系統造成影響。
Metrics:量化的系統狀態或資源指標。
Profiles:程式執行的底層資訊,主要用於性能分析。
Logs:程式執行過程中生成的各類紀錄。
Exceptions:異常發生時的紀錄,其結構與資訊通常比一般日誌更為複雜。
如同名稱一樣,他們是 Pillars 「of」 Observability,他們只是用於搭建 Observability 的資料,擁有資料不代表真正的擁有 Observability,需要實地利用這些資料來提升系統的 Observability。
可以看到大家對於 Observability Signals 都有很多的不同想法,但相同的地方是,都同意不用將範圍侷限在 Metrics、Logs、Traces。只要是對提升 Observability 有幫助,各種不同類型的資料都能夠成為 Observability Signals。
Metrics 和 Logs 在無論在傳統的 Monitoring 領域或 Observability 領域中大多已經有了非常成熟的解決方案,而 Traces 經過十多年的發展,也匯集精華成為了 OpenTelemetry。如今,大家開始把目光投向了 Profiles 與 eBPF。尤其是 eBPF,已經有許多公司開始投入 eBPF 的開發與應用,更有完整的 eBPF 生態系與基金會。在 Observability 領域,eBPF 除了可以應用於 Profiles 之外,也能用於產生 Metrics 和 Traces 等多種 Signals。eBPF 的標誌性專案 Cilium,可以應用於網路的控管和觀測,在今年 10 月 11 日 CNCF 就宣布 Cilium 成為 Graduated Project,也是 CNCF 的第一個 eBPF 類型的畢業專案。
要評估一個領域是否具發展潛力,觀察商業公司的投入情況是最直觀的指標。在過去 Monitoring 一直都有企業持續投入,但自從 Observability 開始大鳴大放後,許多老牌公司也開始把 Observability 關鍵字加入產品中,或轉型稱自己為 Observability 公司,例如:
這些企業的成功明確地證明觀測性具有高度的商業價值。因此,個人在此領域的投資不僅能為自己,也能為其所在組織帶來顯著價值。

雖然有人認為 Observability 不過是 Monitoring 的重新包裝,或者是舊瓶裝新酒。確實,從更高的角度來看,兩者都目的在於確保服務穩定。然而,觀測性更強調資訊背後的 Context,而非僅止於量化數據與告警。透過不同資訊間的交互連結,脈絡變得更加豐富,有助於我們更迅速地找到問題根源,而非僅知道現在發生了問題。
在 TEMPLE: Six Pillars of Observability 一文中有這麼一句:
Pillars are what you build upon, not the end goal.
這些支柱(資料、工具)並不是我們的終極目標,它們只是 Observability 的基礎。我們實際的目標是利用 Observability 來解決問題。收集多少或多大的資料,只能證明我們設計了漂亮的資料流程。真正重要的是,Observability 使我們能更快速地進行問題處理,降低問題解決的平均時間(MTTR),甚至能預先警示即將發生的問題,使其在真正出現前就得到優化或解決。
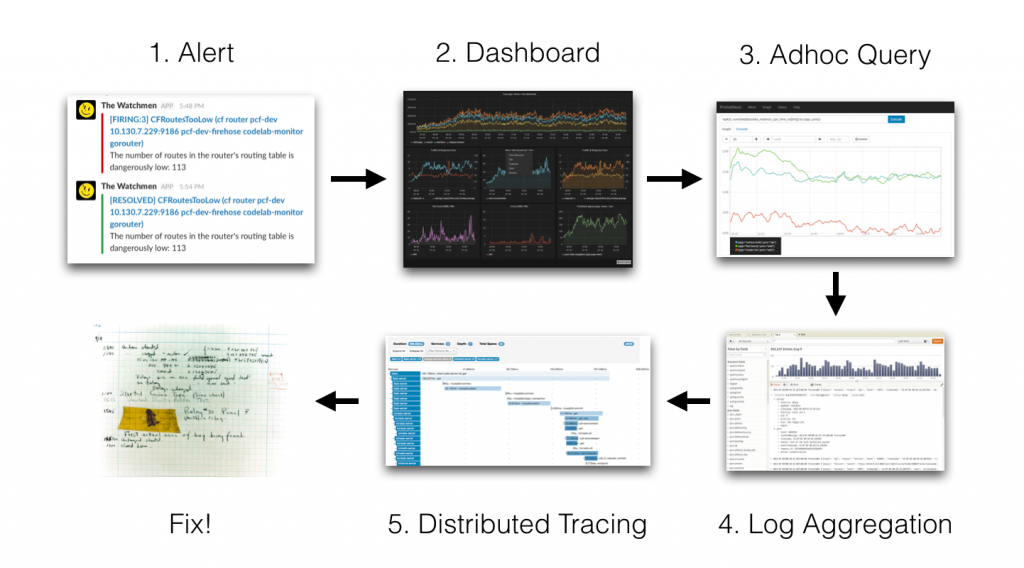
透過 Observability 加快問題處理的流程。圖片來源:Loki: Prometheus-inspired, open source logging for cloud natives
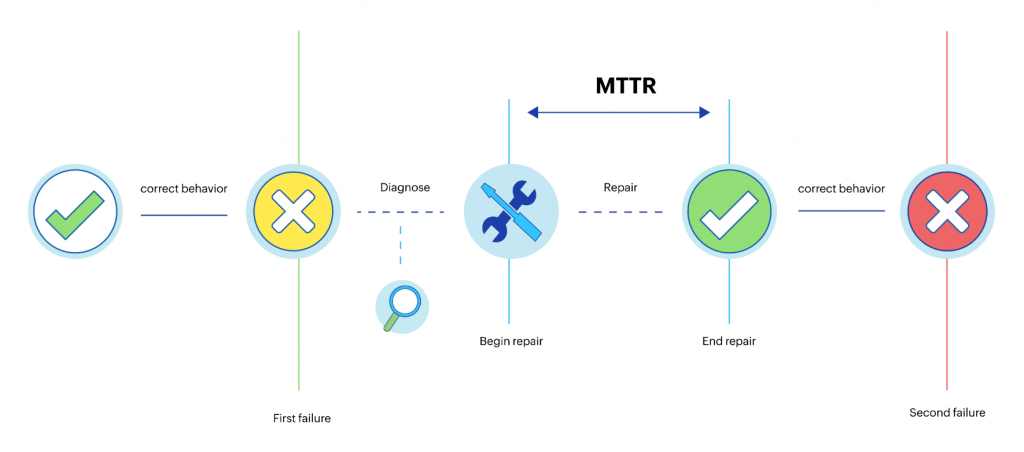
MTTR,Mean Time to Repair。圖片來源:ManageEngine
感謝各位的閱讀,希望這一個月的文章能夠讓大家對於 Observability 有更多的了解。除了技術層面,也希望裡面的一些歷史背景和小知識能夠讓大家有所收穫。若對於文章內容有任何疑問或是建議,歡迎隨時聯絡指教,謝謝。

