
Pyspark的效能調校將會分為四的主題說明
join()、distinct()、groupBy()、orderBy()
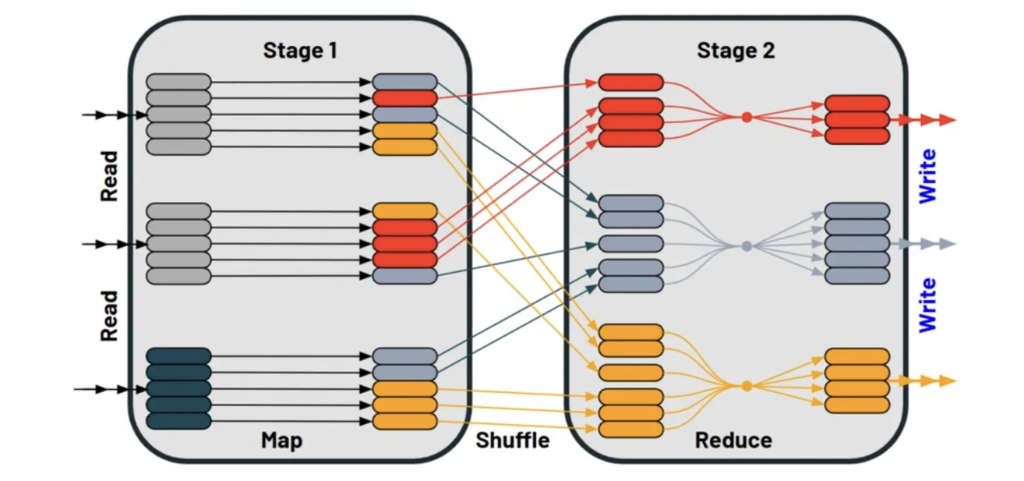
不論我們今天在處理Data的哪個步驟,Data都需要從某的地方被read進來,當data被讀進來的時候,有可能就會需要用到shuffle(洗牌)[也就是打亂資料的順序啦],我們今天來看看groupBy()當做例子吧,假設我們今天需要group by 顏色時,這時候map(mapping operation)就會去辨識那個顏色[stage1]
再來當資料進入stage2時,stage2會將所有的data放進同一個partition(分區)中,這時候就會進行一個reduce的動作,通常我們使用groupBy()時都會搭配count()去做計算,在groupBy這一動時,我們會進行map 去確認資料在哪裡是誰,在count()時,就會去做reduce到同一個partition(分區)中,所以這就是整個shuffle的過程。
那到底效能issue是在哪個部分呢?其實主要的效能問題反而是在map(stage1),當不斷的有寫入及讀取資料(主要是對硬碟)的請求時,其實會一直使用所謂的executor的資源
join() : 使用兩的dataset ,透過common key aggregate 2個dataset,如果match的話就會return一筆結果
distinct() : 根據一個或多個key aggregate多筆資料,並將所有重複項減少為一筆。
groupBy()/count() : 組合根據某個Key aggregate多筆資料, return一筆aggregate的結果(ex:加總sum()/計算總數count())
crossJoin() : 使用兩的dataset ,透過common key aggregate 2個dataset,並為每個可能的組合產生一筆資料(簡單來說是兩個dataset相乘)。非常繁重且昂貴的洗牌操作。
broadcastHashJoin來取代join來避免shuffle (小於10MB的Dataset可以使用)spark.sql.autoBroadcastJoinThreshold(default = 10MB)from pyspark import SparkConf, SparkContext
conf = SparkConf()
conf.set("spark.sql.autoBroadcastJoinThreshold", "20")
sc = SparkContext(conf=conf)
簡單來講就是要避免大規模的shuffle,和減少IO的頻率,或許可以幫助你提高效能!
如果有任何不理解、錯誤或其他方法想分享的話,歡迎留言給我!喜歡的話,也歡迎按讚訂閱!
我是 Vivi,一位在雲端掙扎的資料工程師!我們下一篇文章見!Bye Bye~
【本篇文章將同步更新於個人的 Medium,期待與您的相遇!】

 iThome鐵人賽
iThome鐵人賽