
Agent 是 Langchain 中一個很強大的工具,它是由 LLM 和 prompt 所結合的 chain。Agent 負責決定根據給定情況下一步應採取什麼動作。它接收的輸入有下面幾種:
根據這些輸入,Agent 會返回下一個要採取的動作或給使用者的最終回應。這些回應被稱為 AgentAction 或 AgentFinish。
Tools 是 Agent 調用以完成特定任務的 function。在設計這些工具時,有兩個重要的考慮因素:
給 Agent 提供正確的工具:這代表著工具要對應目標任務,有特定的用途和功能。
以最有用的方式描述這些工具:工具的描述應清晰,以便 Agent 能夠更有效地使用它們。
除了基本的工具外,Langchain 還提供了稱為 Toolkits 的內建工具組。像是 Langchain 就內建了維基百科、數學計算等工具。這些工具組提供了多樣的功能,以供開發者快速入門,並使用戶能夠更容易地建立客製化的解決方案。
我們要用內建的 toolkit 來算數學和查維基百科,先安裝要使用這兩個功能所需的套件。使用指令 poetry add wikipedia numexpr
建立一個 python 檔,叫 langchain_agent.py,並且貼上下面的程式碼。
from langchain.agents import load_tools, initialize_agent, tool
from langchain.agents import AgentType
from langchain.chat_models.azure_openai import AzureChatOpenAI
OPENAI_API_KEY = "yourkey"
OPENAI_DEPLOYMENT_NAME = "gpt-35-16k"
MODEL_NAME = "gpt-35-turbo-16k"
OPENAI_DEPLOYMENT_ENDPOINT = "https://japanopenai2023ironman.openai.azure.com/"
OPENAI_API_TYPE = "azure"
OPENAI_API_VERSION = "2023-03-15-preview"
def get_llm_model():
return AzureChatOpenAI(
openai_api_key=OPENAI_API_KEY,
openai_api_base=OPENAI_DEPLOYMENT_ENDPOINT,
openai_api_type=OPENAI_API_TYPE,
openai_api_version=OPENAI_API_VERSION,
deployment_name=OPENAI_DEPLOYMENT_NAME,
model_name=MODEL_NAME,
temperature=0
)
def get_agent_buildin_tool(llm):
tools = load_tools(["llm-math", "wikipedia"], llm=llm)
return initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose=True)
if __name__ == "__main__":
llm = get_llm_model()
agent = get_agent_buildin_tool(llm)
print(agent("請幫我找到告五人的資訊"))
print(agent("請問一百的四分之三是多少"))
我們跑起來後,就會得到兩個問題推理的過程,以及結果。
@tool 來快速建立自己 agent 所需的 tool,這個太過簡單所以請大家自己去看官方範例。這裡我們用 class base 的 tool 來示範。貼上下面的程式碼,我們做一個五條體產生器的 tool。from langchain.tools import BaseTool
class gojo_satoru(BaseTool):
name = "gojo_satoru_gentool"
description = (
"""這是五條體產生器,請從文本找出下面的 parameter ["protagonist", "enemy", "enemy_skill"],
然後把下方 parameter 取代掉,output 新的文章:
protagonist:enemy太強了
而且enemy還沒有使出全力的樣子
對方就算沒有enemy_skill也會贏
我甚至覺得有點對不起他
我沒能在這場戰鬥讓enemy展現他的全部給我
殺死我的不是時間或疾病
而是比我更強的傢伙,真是太好了"""
)
def _run(self,
protagonist: str = None,
enemy: str = None,
enemy_skill: str = None,
):
if protagonist and enemy and enemy_skill:
print("#############")
return f"""請把 parameter 取代掉,產出下面這文章:
{protagonist}:{enemy}太強了啊啊啊啊啊啊
而且{enemy}還沒有使出全力的樣子
對方就算沒有{enemy_skill}也會贏
我甚至覺得有點對不起他
我沒能在這場戰鬥讓{enemy}展現他的全部給我
殺死我的不是時間或疾病
而是比我更強的傢伙,真是太好了"""
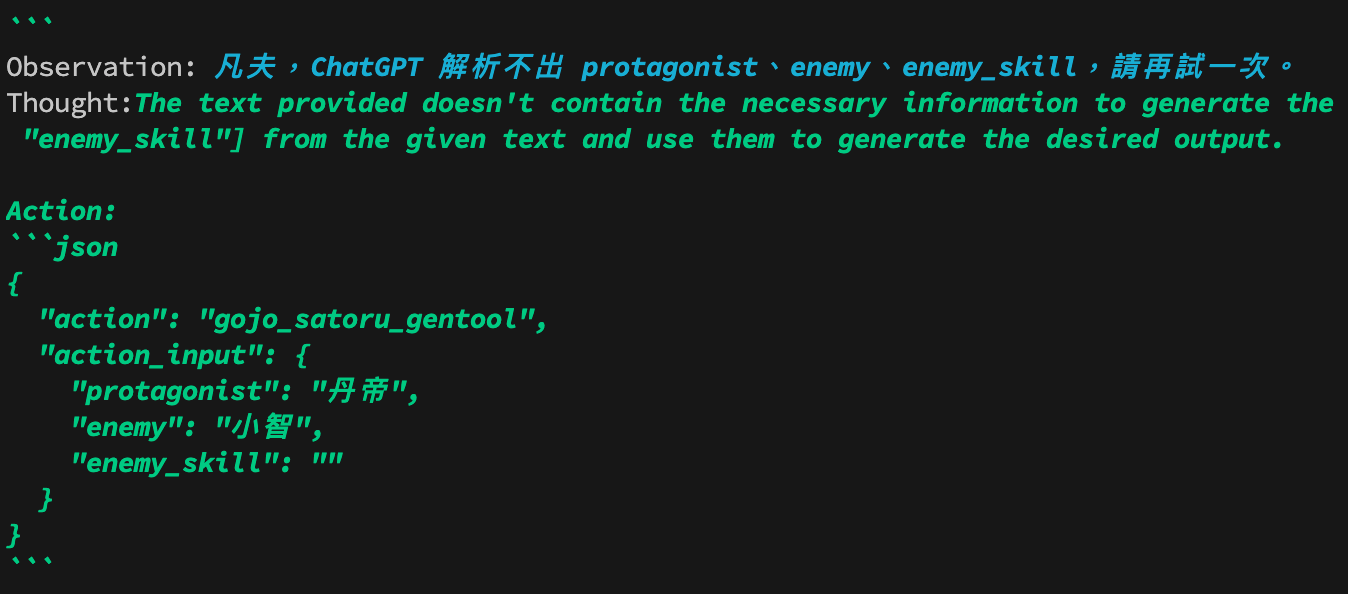
else:
return "凡夫,ChatGPT 解析不出 protagonist、enemy、enemy_skill,請再試一次。"
def get_agent_custom_tool(llm):
tools = [gojo_satoru()]
return initialize_agent(
tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose=True)
if __name__ == "__main__":
llm = get_llm_model()
agent2 = get_agent_custom_tool(llm)
print(agent2("請解析下文,幫我產生五條體:丹帝對戰小智,皮卡丘會鎖血"))
參數正確解析:

參數錯誤解析:
相信剛剛大家有注意到,上面兩個 Agent 的範例,是不同的 agent type。接著我們就來講解什麼是 Agent type。
這種 Agent 使用 ReAct 框架,僅根據工具的描述來決定使用哪一個工具。這個 Agent 要求為每個工具提供一個描述。這是算是最通用的 Agent。
這個 Agent 能夠使用多輸入。舊的 Agent 都是配置為將動作輸入指定為單一字符串,但這個 Agent 可以使用 tool 的多參數架構來創建一個結構化的動作輸入。這對於更複雜的工具使用非常有用,像我們第二個 custom tool 的範例就是如此。
這是為了 OpenAI Function Calling 的功能而設計的 Agent 。
這個 Agent 主要用於對話設定中。它的 prompt 是為了使 Agent 更加有用和健談。它使用 ReAct 框架來決定使用哪個工具,並使用記憶來記住先前的對話互動。
這個 Agent 使用一個叫做 Intermediate Answer 的 tool。這個 tool 能夠查找問題的事實性答案。這個 Agent 是來自於 self-ask with search 的論文,其中提供了 Google 搜索 API 作為工具。
這個 Agent 是使用 ReAct 框架與文檔存儲(docstore)。我們必須提供兩個 tool:一個 Search tool 和一個 Lookup tool(注意,必須精確地以這些名稱命名)。Search tool 用於搜索文檔,而 Lookup tool 則用於在最近找到的文檔中查找詞語。這個 Agent 相當於原始的 ReAct 論文,特別是 Wikipedia 的例子。
以上就是 LangChain 提供的各種 Agent 的全面解析。每種 Agent 都有其獨特的用途和應用場景,使用者可以根據需求來選擇合適的 Agent。
這次的題目訂得很巨大,力求完整和詳細,三十篇文章的額度真的不太夠用。這次在一開始先教大家產品等級的 Python 虛擬環境管理,還舉了一個例子說明為什麼 Poetry 在 LLM 應用開發上扮演了重要的角色。
再來我們講了 Hugging Face。我補充了去年鐵人賽很多我沒有談到的東西,並且還整合了 FastAPI 的應用,讓大家可以不被綁住地使用 embedding 。
然後向量資料庫是我花最多心力寫的地方。這一塊是 LLM 應用開發的核心中的核心,可是市面上很少人在談向量資料庫這一塊。因此,我介紹了多種向量資料庫的使用和特性,並且分享了我實務上的眉角。
最後就是 LangChain 的部份。其實我之前討厭 LangChain,裡面許多功能雖然包得好好的,但是有些地方要做細粒度調整時卻因為都包了起來,難以做調整。相信很多朋友在看過 LangChain 的功能之後,也會覺得自己用原生的 SDK 都可以做起來。但是 Langchain 真的可以更快速開發,也讓我愛上它。
此外,有三個部份預計要談但是沒有寫到的,讀者可以留意一下,自行找資料學習。
第一個是 Function Calling,原生的 Function Calling 和 Langchain 版本的做法不太一樣,是值得留意的地方。不過在 Langchain 有 agent 可以使用,操作上也不太難,或許很多人就不會考慮去用 function calling 了。
第二個是 Azure Machine Learning 的 Prompt flow,這是一個圖形化介面讓你做 LLM 應用的強大工具。本來也是希望花個兩三篇談這一塊的,但是真的時間不太夠。
第三個是 Stream,原生的 Function Calling 和 Langchain 版本的做法不太一樣,是值得留意的地方。還有前後端在處理 Stream 時要注意的地方,也都沒有時間講到。
至少,我相信這 30 天的教學內容,已經是相關完整的 LLM 應用開發了,而且談了很多市面上很少人在談的內容,即使中間經歷了我的二寶誕生,也沒有斷更。希望這系列能對讀者們在開發 LLM 應用程式有所助益。
KoKo 你好,
非常感謝你寫這個系列,從Day1到Day30都操作過一次,收穫良多,對於LangChain的使用上有了更熟悉的理解,希望未來能夠再從大大這邊學到更多AI相關知識。
非常感謝,
祝,一切順心。
感謝您的教學!
有點不理解,OPENAI_DEPLOYMENT_ENDPOINT這個設定,既然已經有設定OPENAI_API_KEY為何還需要"https://japanopenai2023ironman.openai.azure.com/" 轉發? 謝謝!
自問自答,應該是使用azure openai的關係

 iThome鐵人賽
iThome鐵人賽