今天想查郵遞區號,發現中華郵政有提供一個全國地址和郵遞區號的檔案。
打開來看,發現有非常多重複的字,於是我想能不能試著壓縮看看。
不過我沒有相關壓縮經驗,目前的想法是轉成json格式,刪除大量重複,看看最後能壓到多小
台灣郵遞區號.csv(2,915,093 byte)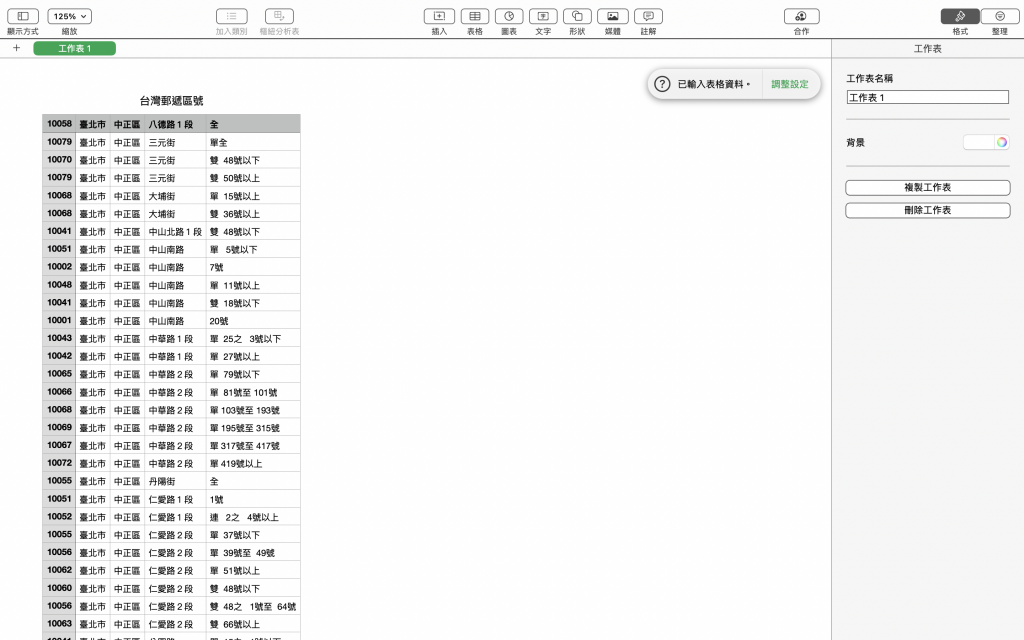
首先寫一個檢查檔案大小的程式碼,短短三行,接下來會時常用到
import os
file_size = os.path.getsize('台灣郵遞區號.json')
print(f"{'{:,}'.format(file_size)} byte")
接著將csv轉成json,以下是程式碼:
import csv
import json
with open('台灣郵遞區號.csv', newline='', encoding = "UTF-8", errors='ignore') as csvfile:
lst = [i for i in csv.reader(csvfile)]
data = {}
for i in lst:
if i[1] not in data:
data[i[1]] = {}
if i[2] not in data[i[1]]:
data[i[1]][i[2]] = {}
if i[3] not in data[i[1]][i[2]]:
data[i[1]][i[2]][i[3]] = []
data[i[1]][i[2]][i[3]].append([i[4],i[0]])
with open ('台灣郵遞區號.json', 'w' ) as file:
json.dump(data, file)
檔案大小為: 2,995,659 byte
嚇了一跳,沒想到檔案居然還變大了,於是我打開檔案來看,發現長這樣(部分顯示)
{"\u81fa\u5317\u5e02": {"\u4e2d\u6b63\u5340": {"\u516b\u5fb7\u8def\uff11\u6bb5": [["\u5168", "10058"]], "\u4e09\u5143\u8857": [["\u55ae\u5168", "10079"], ["\u96d948\u865f\u4ee5\u4e0b", "10070"], ["\u96d950\u865f\u4ee5\u4e0a", "10079"]], "\u5927\u57d4\u8857": [["\u55ae15\u865f\u4ee5\u4e0a", "10068"], ["\u96d936\u865f\u4ee5\u4e0a", "10068"]], "\u4e2d\u5c71\u5317\u8def\uff11\u6bb5": [["\u96d948\u865f\u4ee5\u4e0b",
去查了一下發現是Unicode轉義字元,然後如果只想要ascii字元,可以這樣改
with open ('台灣郵遞區號.json', 'w' , encoding = "UTF-8") as file:
json.dump(data, file, ensure_ascii=False)
檔案大小為:2,131,766 byte
此時打開檔案就會變成這樣(部分顯示)
{"臺北市": {"中正區": {"八德路1段": [["全", "10058"]], "三元街": [["單全", "10079"], ["雙48號以下", "10070"], ["雙50號以上", "10079"]], "大埔街": [["單15號以上", "10068"], ["雙36號以上", "10068"]], "中山北路1段": [["雙48號以下", "10041"]], "中山南路": [["單5號以下", "10051"], ["7號", "10002"], ["單11號以上", "10048"], ["雙18號以下", "10041"], ["20號", "10001"]], "中華路1段": [["單25之3號以下", "10043"], ["單27號以上", "10042"]], "中華路2段": [["單79號以下",
我不希望有多餘的空格,所以再增加一些參數
with open ('台灣郵遞區號.json', 'w' , encoding = "UTF-8") as file:
json.dump(data, file, ensure_ascii=False, separators=(",", ":"))
檔案大小為:1,964,780 byte
此時打開檔案就會變成這樣(部分顯示)
{"臺北市":{"中正區":{"八德路1段":[["全","10058"]],"三元街":[["單全","10079"],["雙48號以下","10070"],["雙50號以上","10079"]],"大埔街":[["單15號以上","10068"],["雙36號以上","10068"]],"中山北路1段":[["雙48號以下","10041"]],"中山南路":[["單5號以下","10051"],["7號","10002"],["單11號以上","10048"],["雙18號以下","10041"],["20號","10001"]],"中華路1段":[["單25之3號以下","10043"],["單27號以上","10042"]],"中華路2段":[["單79號以下","10065"],["單81號至
這個時候我想看看能不能把郵遞區號改成數字
data = {}
for i in lst:
if i[1] not in data:
data[i[1]] = {}
if i[2] not in data[i[1]]:
data[i[1]][i[2]] = {}
if i[3] not in data[i[1]][i[2]]:
data[i[1]][i[2]][i[3]] = []
data[i[1]][i[2]][i[3]].append([i[4],int(i[0])]) # 郵遞區號轉成數字
檔案大小為:1,841,714 byte
此時打開檔案就會變成這樣(部分顯示)
{"臺北市":{"中正區":{"八德路1段":[["全",10058]],"三元街":[["單全",10079],["雙48號以下",10070],["雙50號以上",10079]],"大埔街":[["單15號以上",10068],["雙36號以上",10068]],"中山北路1段":[["雙48號以下",10041]],"中山南路":[["單5號以下",10051],["7號",10002],["單11號以上",10048],["雙18號以下",10041],["20號",10001]],"中華路1段":[["單25之3號以下",10043],["單27號以上",10042]],"中華路2段":[["單79號以下",10065],["單81號至101號",10066],["單103號至193號",10068],["單195號至315
從2,915,093 byte → 1,841,714 byte
下一章,我們來嘗試自己創格式吧!
 rex1206
rex1206

 iThome鐵人賽
iThome鐵人賽