在訓練AI模型前,我們先了解常用ResNet模型的運作方式
ResNet(Residual Neural Network)是由微軟研究院於2015年提出的深度學習模型。其主要特色包括:
梯度消失(Vanishing Gradient):梯度消失是指在反向傳播過程中,梯度逐漸變小,最終接近於零,導致網絡權重無法有效更新。這通常發生在使用 sigmoid 或 tanh 激活函數的深層網絡中。當梯度變得非常小時,前幾層的權重幾乎不會更新,這使得網絡難以學習到有效的特徵。
在傳統的深層神經網絡中,隨著層數的增加,梯度在反向傳播過程中可能會逐漸變小,最終導致梯度消失。ResNet 通過在每個殘差塊中引入跳躍連接(skip connections),使得輸入可以直接傳遞到後面的層,這樣可以保留更多的原始信息。
y = F(x) + x
由於梯度消失問題得到緩解,ResNet 可以構建非常深的網絡,同時殘差結構使得網絡在訓練過程中更容易收斂,並且能夠更快地達到較好的性能。
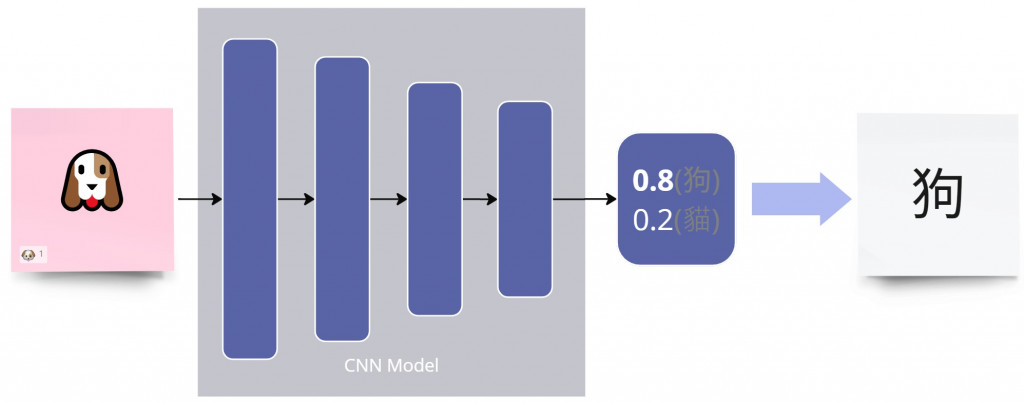
利用 ResNet18 進行貓狗分類是一個經典的圖像分類任務。以下是如何使用 ResNet18 來實現這個任務的步驟:
首先,需要準備貓和狗的圖像資料集。常用的資料集是 Kaggle 的貓狗資料集,包含 25,000 張貓和狗的圖像。這些圖像需要分為訓練集和驗證集。
在進行模型訓練之前,需要對圖像資料進行預處理。這包括:
前幾天有提到的資料增強方法都可以添加在transform裡面進行訓練,看看訓練的提升效果。
使用 PyTorch 構建 ResNet18 模型。可以使用預訓練的 ResNet18 模型,並將最後一層的全連接層調整為兩個輸出節點(對應貓和狗兩個類別)。
為什麼要這樣改?
首先我們先載入Model,直接 print 出來看看他的架構(fc): Linear(in_features=512, out_features=1000, bias=True)
model.fc = nn.Linear(num_ftrs, 2)
import torchvision.models as models
# 加載預訓練的 ResNet18 模型
model = models.resnet18(pretrained=True)
print(model)
'''
Output:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1)...
(layer2)...
(layer3)...
(layer4)...
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
'''
前面是先經過 conv1 而該層是吃3個channel (RGB圖片) 輸出為224*224,所以如果只有 1 channel (灰階) 維度不一樣的話會收到維度錯誤的訊息,這時可以怎麼改?
暴力法
print(model.conv1)
model.conv1 = nn.Conv2d(1, 224, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
但變更layer的同時會失去pretrain的權重
變更之後權重會變成random(應該是高斯分布)
也可以把權重都設為0,說不定也可以為模型帶來更好的訓練。
# 訪問 conv1 層的權重
conv1_weights = model.conv1.weight
# 打印權重
print(conv1_weights)
變更後的權重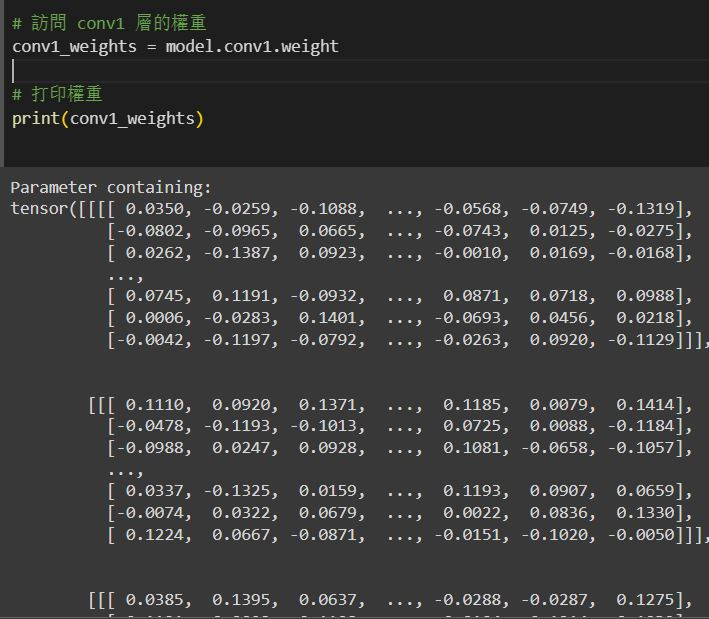
# 加載預訓練的 ResNet18 模型
model = models.resnet18(pretrained=True)
# 輸出 conv1 權重
print("Original conv1 weights:")
print(model.conv1.weight)
# 初始化 conv1 權重 (例如,使用 Xavier 初始化)
nn.init.xavier_uniform_(model.conv1.weight)
print("\nConv1 weights after Xavier initialization:")
print(model.conv1.weight)
# 重設 conv1 權重為 0
model.conv1.weight.data.fill_(0)
print("\nConv1 weights after resetting to zero:")
print(model.conv1.weight)
上面我們改好了模型,現在來丟一些隨機值來測試我們的model是否正常運作?torch.randn可以隨機生成指定維度的資料,也常常被我們拿來測試 model 的設定是否正確。
但為什麼是4個維度?
因為 dataloader都會打包資料,即使今天只有一筆,也會多添加一個batch_size的維度上去。(1, 1, 224, 224)
img = torch.randn(1, 1, 224, 224)
output = model(img)
print(output)
使用驗證集評估模型的性能,計算準確率等指標。
使用訓練好的模型對新圖像進行預測。
ResNet 的靈活性和強大的性能使其成為許多深度學習應用中的首選工具,通過調整和擴展,你可以在各種圖像處理和計算機視覺任務中使用這一模型。


 iThome鐵人賽
iThome鐵人賽