前情提要: 昨天已經大致上把Dataset的部分講完了,舉了一個以聲音為主的範例,如何從txt裡面load對應的音檔,最後讓size保持一致。
今天開始介紹pytorch lightning,以下廢話可以忽略 ~~
廢話: 這是我上班後一年才開始接觸的,起初剛進公司還很菜,基本上都是跑人家寫好的git,但始終遇到一個問題,需要新增功能去修改code時,會發現很難改的動,甚至不知道人家整個處理流程,到最後只能以失敗告終(相信這個占多數),直到做到speech enhancement 這個專案,我下定決心花額外時間學習lightning這個框架,並從Dataset到model重新自己寫過,然後找到屬於自己的程式架構。
我自己會選擇這一框架有幾個主要原因:
安裝十分簡單,透過以下指令。
pip install lightning
在官網(https://lightning.ai/docs/pytorch/stable/starter/introduction.html )會看到一個影片,就是將pytroch的code改成lightning的格式,我們也來嘗試看看。
這裡我們借用一下人家git的dataset,https://github.com/teavanist/MNIST-JPG ,這裡之所以不直接用from torchvision.datasets import MNIST 下載檔案,是因為正常在訓練自己的東西,不會有這個可以用,再來就是如何透過我們前兩天學的來處理這個資料集。
這裡常用的幾種方式:
import os
import glob
def prepare(root_dir):
datasets = ['train', 'test']
for dataset in datasets:
paths = glob.glob(os.path.join(f'{root_dir}/{dataset}', '**/*.jpg'), recursive = True)
with open(f'{dataset}.txt', 'w') as f_i:
for path in paths:
label = path.split('/')[-2] # 路徑倒數第二個對應到的剛好是 label
f_i.write(f'{path}|{label}\n')
if __name__ == "__main__":
prepare('/ws/dataset/MNIST')
test.txt 會長得像下面這樣,可以用 head -n 5 test.txt 來觀看
/ws/dataset/MNIST/test/3/8624.jpg|3
/ws/dataset/MNIST/test/3/4904.jpg|3
/ws/dataset/MNIST/test/3/5150.jpg|3
/ws/dataset/MNIST/test/3/7329.jpg|3
/ws/dataset/MNIST/test/3/9073.jpg|3
/ws/dataset/MNIST/test/3/4755.jpg|3
/ws/dataset/MNIST/test/3/9022.jpg|3
然後我們用以下指令將 test.txt 前三筆另外寫成一個檔案 unit_test.txt,主要用於測試下面的 CustomDataset
head -n 3 test.txt > unit_test.txt
接下來我們一樣補上 Dataset 的部分,跟前面的一樣分別會有 init, len, getitem。
init:
len:
getitem:
from PIL import Image
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import torch
class CustomDataset(Dataset):
def __init__(self, txt_path):
self.data = []
self.get_data(txt_path)
self.transform = transforms.Compose([
transforms.Resize((28, 28)), # 確保圖片大小一致
transforms.ToTensor(), # 轉換為PyTorch張量
transforms.Normalize((0.5, ), (0.5, )) # 標準化
])
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
path, label = data.split('|')
image = Image.open(path).convert('L') # MNIST是灰度圖,轉換為'L'模式
image = self.transform(image)
label = int(label)
return image, torch.tensor(label)
def get_data(self, txt_path):
with open(txt_path, 'r') as f_i:
lines = f_i.readlines()
self.data = [line.strip() for line in lines]
if __name__ == "__main__":
unit_test = CustomDataset('unit_test.txt')
for idx, (image, label) in enumerate(unit_test):
print(f'image: {image.size()}, label: {label}')

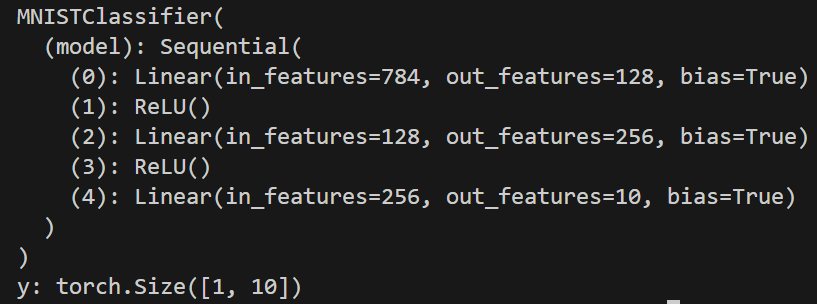
模型架構這裡採用簡單 MLP,也就是多個 linear 所組成,維度從剛開始的輸入 28 * 28 = 768,透過多個 linear 轉成將維度從 768 -> 128 -> 256 -> 10,當中的 hidden_dim 參考就好。
import torch.nn as nn
import torch
class MNISTClassifier(nn.Module):
def __init__(
self,
img_size = [28, 28],
hidden_dim = [128, 256],
num_classes = 10,
):
super(MNISTClassifier, self).__init__()
# 寫在一起
self.model = nn.Sequential(
nn.Linear(img_size[0] * img_size[1], hidden_dim[0]),
nn.ReLU(),
nn.Linear(hidden_dim[0], hidden_dim[1]),
nn.ReLU(),
nn.Linear(hidden_dim[1], num_classes)
)
# 一個個寫
# self.layer_1 = nn.Linear(img_size[0] * img_size[1], hidden_dim[0])
# self.layer_2 = nn.Linear(hidden_dim[0], hidden_dim[1])
# self.layer_3 = nn.Linear(hidden_dim[1], num_classes)
def forward(self, x):
'''
x: [B, C, W, H]
B: batch size
C: channel
W: Width
H: Hight
'''
batch_size = x.size(0)
x = x.view(batch_size, -1) # [B, C, W, H] -> [B, C * H * W]
x = self.model(x)
return x
if __name__ == "__main__":
model = MNISTClassifier()
print(model)
x = torch.rand(1, 1, 28, 28)
y = model(x)
print(f'y: {y.size()}')
今天有點忙所以就先到這裡囉~~
明天會到重點train_step, configure_optimizers 如何寫。


 iThome鐵人賽
iThome鐵人賽