昨天把模型重新理解了一次,用程式碼來實際修改成適合ConvLSTM模型的樣子,
前天後續衍生的bug也一個個解決掉,最後的程式碼如下。
引入必要的套件,用來操作、預處理還有可視化,和構建 ConvLSTM 模型
import numpy as np
import pandas as pd
import pylab as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
#from keras.layers.convolutional import Conv3D
from tensorflow.keras.layers import ConvLSTM2D, Dense, Flatten
from tensorflow.keras.optimizers import Adam
# 資料表讀進來
df= pd.read_excel('Merged_to_train_ALL.xlsx')
df
顯示 DataFrame狀況
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3183 entries, 0 to 3182
Data columns (total 12 columns):
Column Non-Null Count Dtype
0 日期 3183 non-null object
1 券商代碼 3183 non-null object
2 買進(張) 3183 non-null object
3 賣出(張) 3183 non-null object
4 買賣超(張) 3183 non-null object
5 橫坐標 3183 non-null int64
6 縱坐標 3183 non-null int64
7 開盤價 3183 non-null int64
8 最高價 3183 non-null float64
9 最低價 3183 non-null float64
10 收盤價 3183 non-null float64
11 成交量 3183 non-null float64
dtypes: float64(4), int64(3), object(5)
memory usage: 298.5+ KB
資料前處理,缺失值、資料型態,把籌碼資訊、股價資訊都轉成數值
df = df.ffill() # 使用 ffill 方法來填充缺失值
# 移除數值欄位中的非數值字符ex.逗號,並轉換為浮點數
cols_to_convert = ['買進(張)', '賣出(張)', '買賣超(張)', '開盤價', '最高價', '最低價', '收盤價', '成交量']
for col in cols_to_convert:
df[col] = df[col].astype(str).str.replace(',', '').astype(float)
#查看datatype是否順利轉型,和資料是否還有空值
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3183 entries, 0 to 3182
Data columns (total 12 columns):
Column Non-Null Count Dtype
0 日期 3183 non-null object
1 券商代碼 3183 non-null object
2 買進(張) 3183 non-null float64
3 賣出(張) 3183 non-null float64
4 買賣超(張) 3183 non-null float64
5 橫坐標 3183 non-null int64
6 縱坐標 3183 non-null int64
7 開盤價 3183 non-null float64
8 最高價 3183 non-null float64
9 最低價 3183 non-null float64
10 收盤價 3183 non-null float64
11 成交量 3183 non-null float64
dtypes: float64(8), int64(2), object(2)
memory usage: 298.5+ KB
# 對數值欄位做標準化(0 ~ 1 之間)
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df[cols_to_convert])
scaled_data
array([[1.45076202e-02, 1.19928931e-02, 4.80897704e-01, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[2.05158265e-03, 1.37696180e-02, 4.70772443e-01, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[7.32708089e-04, 3.40538940e-03, 4.77139875e-01, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
...,
[1.81711606e-02, 2.05803968e-02, 4.77453027e-01, ...,
9.00497512e-01, 7.38095238e-01, 1.00000000e+00],
[1.53868699e-02, 1.43618596e-02, 4.79853862e-01, ...,
9.00497512e-01, 7.38095238e-01, 1.00000000e+00],
[1.61195780e-03, 4.44181226e-04, 4.79853862e-01, ...,
9.00497512e-01, 7.38095238e-01, 1.00000000e+00]])
如果我們時間序列用來預測收盤價的話
# 創建時間序列資料
def create_sequences(data, time_steps=1):
X, y = [], []
for i in range(len(data)-time_steps):
X.append(data[i:(i+time_steps)])
y.append(data[i+time_steps, -1]) # 假設預測收盤價
return np.array(X), np.array(y)
time_steps = 3 # 時間步3天
X, y = create_sequences(scaled_data, time_steps)
重塑資料適應 ConvLSTM2D 層的輸入
# 檢查 X 的形狀
print("Original X shape:", X.shape)
# 重塑資料
X = X.reshape((X.shape[0], time_steps, 1, 1 , X.shape[2], 1))
# 再次檢查 X 的形狀
print("Reshaped X shape:", X.shape)
Original X shape: (3173, 10, 8)
Reshaped X shape: (3173, 10, 1, 8, 1) #有10筆資料消失(? 怪怪的
建立 ConvLSTM 模型,ConvLSTM2D 2層、Flatten 1層和 Dense 2層,
最佳化使用 Adam,loss function用MSE(均方誤差)計算。
Model: "sequential" 這個之後文章還有空缺再來解釋,
這有關到tensorflow提供的兩種API方式,這邊用基礎且簡單的sequential api。
model = Sequential([
ConvLSTM2D(filters=64, kernel_size=(1, 2), input_shape=(time_steps, 1, X.shape[3], 1), return_sequences=True),
ConvLSTM2D(filters=32, kernel_size=(1, 2), return_sequences=False),
Flatten(),
Dense(50, activation='relu'),
Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
model.summary()
┃Layer (type) ┃ Output Shape ┃ Param #
┃conv_lstm2d (ConvLSTM2D) ┃ (None, 10, 1, 7, 64) ┃ 33,536
┃conv_lstm2d_1 (ConvLSTM2D) ┃ (None, 1, 6, 32) ┃ 24,704
┃flatten (Flatten) ┃ (None, 192) ┃ 0
┃dense (Dense) ┃ (None, 50) ┃ 9,650
┃dense_1 (Dense) ┃ (None, 1) ┃ 51
#60000多個參數,厲害了,我的天
Total params: 67,941 (265.39 KB)
Trainable params: 67,941 (265.39 KB)
Non-trainable params: 0 (0.00 B)
模型建好後,就給它fit下去,這邊先訓練50個回合就好,驗證集切10%
# 訓練模型,
history = model.fit(X, y, epochs=50, batch_size=32, validation_split=0.1)
Epoch 1/50
90/90 ━━━━━━━━━━━━━━━━━━━━ 4s 18ms/step - loss: 0.0486 - val_loss: 1.0386e-04
Epoch 2/50
90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 15ms/step - loss: 0.0021 - val_loss: 3.0396e-06
...
...
Epoch 50/50
90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 16ms/step - loss: 6.4269e-04 - val_loss: 1.3548e-05
100/100 ━━━━━━━━━━━━━━━━━━━━ 1s 8ms/step
這個花了3、40分鐘以上,好久阿,幸好模型訓練可以做其他事,不會自己掛掉(除非code寫錯)。
訓練好就來預測一下,看看預測結果和實際結果的比較,把結果畫成圖
# 預測
predictions = model.predict(X)
# 可視化
plt.plot(predictions, label='Predicted')
plt.plot(y, label='Actual')
plt.legend()
plt.show()
嗯...有點看不太懂這圖,是訓練結果太慘烈了一點嗎...
實際值也不太可能都是一致的,總感覺是不是股價和籌碼的值被放在同一個軸上顯示了。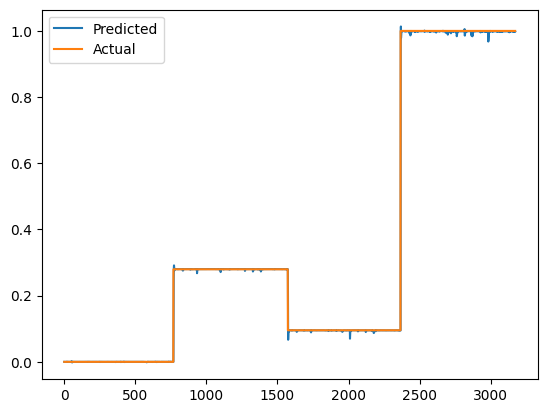
這結果怪怪的,明天來修改一下,可能是資料輸入有點問題,
或是現在的資料維度不適合模型,可能要拆分。
每日記錄:
加權指數收在22409.63點,上漲60.3點,美股上週平盤震盪,台股偷偷爬,但8/1的缺口還沒補上。
等待這個禮拜美股開出神奇的數據,今晚有美國電子商務銷售。


 iThome鐵人賽
iThome鐵人賽