
Paper link | Code link | CVPR 2022
這篇論文介紹了一項名為 音頻-視覺問答(AVQA) 的新任務。
他們建立了一個包含 45,867 個問題-答案對的數據集,涵蓋了各種音頻-視覺模態和問題類型。
此外,他們還提出了一個 時空基礎模型,以增強對場景的細緻理解和推理能力。
這項研究專注於 音頻-視覺問答(AVQA) 任務,該任務涉及回答有關視覺物體、聲音及其在影片中關聯的問題。
他們引入了大規模的 MUSIC-AVQA 數據集,該數據集包含超過 45,000 個問題-答案對,涵蓋了 33 種問題模板,涉及各種模態和類型。
他們還開發了幾個基準模型,並提出了一個 時空基礎音頻-視覺網絡 來處理 AVQA 任務。
這項研究介紹了一個新任務,稱為 音頻-視覺問答(AVQA),該任務專注於回答有關視覺物體、聲音及其關聯的問題。
下圖展示了一個音頻-視覺問答的示例案例,該案例需要結合聽覺和視覺模態進行多模態場景理解和時空推理。

為了探索音頻和視覺模態的場景理解和時空推理,他們建立了一個大規模的數據集,MUSIC-AVQA,專注於問答任務。
認識到高品質數據集對於AVQA研究的重要性,他們從YouTube上手動收集了音樂表演影片,選擇了22種樂器,如吉他、大提琴和木琴。
他們設計了9種類型的音頻-視覺問題,涵蓋三種場景:音頻、視覺和音頻-視覺。
下表比較了MUSIC-AVQA數據集與其他影片問答數據集的差異。

這張圖提供了 MUSIC-AVQA 數據集的統計數據。

對於輸入影片,視覺和音頻序列都被劃分為 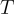 個不重疊的 1 秒段
個不重疊的 1 秒段 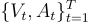 。
。
問題 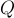 被分詞為
被分詞為 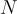 個單詞
個單詞 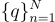 。
。
接著使用三種編碼器:VGGish 用於音頻,ResNet-18 用於視覺,LSTM 用於問題。

他們將特定的視覺位置與輸入的聲音關聯起來,以進行空間基準化,並使用問題查詢在關鍵時間戳上突出音頻和視覺特徵,以進行時間基準化。
最後,多模態融合將音頻、視覺和問題信息整合在一起,以預測答案。
為了在 MUSIC-AVQA 資料集上驗證他們的方法,他們將其與最近的音頻問答方法進行比較。
他們使用答案預測準確率作為指標,並評估模型在各種問題類型上的性能。
答案詞彙包括 42 個選項(22 種物體、12 種計數選擇、6 種位置類型以及是/否)。

空間-時間基準結果如下圖所示:發聲區域和關鍵時間戳在空間和時間上被高亮顯示(a-e),展示了他們的方法在建模跨模態的空間-時間關聯方面的有效性,從而提高場景理解和推理能力。
子圖(f)顯示了一個失敗案例,其中多個聲音和靜音物體的複雜場景妨礙了準確的物體-聲音關聯,導致錯誤的答案。

