
Paper link | Note link | Code link | AAAI 2024
他們提出了「圖神經提示」(Graph Neural Prompting, GNP),這是一種新穎的即插即用方法,用於幫助預訓練的大型語言模型(LLMs)從知識圖譜(KGs)中學習有益的知識。
為了減少大型語言模型的局限性,現有的工作使用基於實體的知識來增強預訓練的LLMs。
例如,檢索增強生成(retrieval-augmented generation)仍然是一個未解決的問題,尤其是在知識圖譜(KGs)方面。
在這篇論文中,他們提出了圖神經提示(Graph Neural Prompting, GNP),這是一種即插即用的方法,旨在幫助預訓練的LLMs從知識圖譜中獲取有益的知識。
知識圖譜(KGs)儲存了大量的事實,並作為一種系統化的知識呈現方式。
現有的方法通過設計定制的模型架構,將KGs與語言模型結合起來,以同時處理文本數據和KGs。
然而,由於語言模型的參數規模,聯合訓練模型變得具有挑戰性。
一種直接結合KGs和語言模型優勢的方法是將KG三元組輸入到LLMs中。
然而,這種方法可能會引入大量噪音,因為KGs可能包含各種無關的上下文。
那麼,我們能否從KGs中學習有益的知識,並將其整合到預訓練的LLMs中呢?
他們提出了一種方法,通過檢索並編碼相關的基於實體的知識,來生成一個圖神經提示(Graph Neural Prompt)。
該提示是一個嵌入向量,可以用來向LLMs提供指導和指令。
給定一個問題 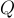 ,一組答案選項
,一組答案選項 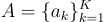 ,以及一個可選的上下文
,以及一個可選的上下文 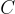 。真實標籤
。真實標籤 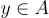 是正確答案。
是正確答案。
我們需要設計一個模型 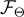 來選擇最佳選項以回答問題。此外,這篇論文使用知識圖譜
來選擇最佳選項以回答問題。此外,這篇論文使用知識圖譜 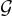 來提供外部知識並幫助模型回答問題。
來提供外部知識並幫助模型回答問題。

步驟如下:
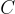 、問題
、問題 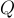 和答案選項
和答案選項 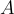 的連接內容標記為輸入文本序列
的連接內容標記為輸入文本序列 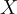 。
。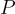 ,並將其附加到輸入標記
,並將其附加到輸入標記 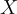 上。將其作為LLM模型的輸入,以生成預測
上。將其作為LLM模型的輸入,以生成預測 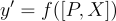 。
。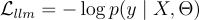 。
。下表顯示了在常識推理和生物醫學推理任務上的整體實驗結果。

下圖顯示了在LLM Frozen和LLM Tuned設定下的結果比較。

