
Paper link | ICML 2023
這項研究提出了一種簡單但有效的表示學習方法,稱為 RLEG,由基於擴散的嵌入生成器指導。
擴散模型在線生成嵌入,幫助學習有效的視覺-語言表示。
預訓練的生成器在視覺和語言領域之間轉移嵌入,這些生成的嵌入作為對比學習的增強樣本。
視覺-語言模型如 CLIP 在各種任務中表現出色,但訓練這些模型通常需要大量的數據集。生成式擴散模型(如 DALL-E 2)展示了通過從生成分佈中抽樣可以產生多樣且高品質的樣本。
利用這種生成能力,本研究提出了一種新方法,稱為 基於擴散的嵌入生成表示學習(RLEG)。
這種方法使用擴散模型在線生成特徵嵌入,以實現有效的視覺-語言表示。
視覺-語言表示學習通常需要大量數據集,但收集高品質的圖像-文本對非常具有挑戰性。
本研究旨在通過使用生成模型在線創建多樣的訓練樣本來學習穩健的表示。
研究靈感來自於這樣一個假設:現實世界的數據位於高維空間中的低維流形上。

首先,輸入的圖像和文本分別通過編碼器進行編碼,以獲得對齊的輸入嵌入。
接下來,使用基於擴散的嵌入生成器從文本嵌入生成圖像嵌入,並從圖像嵌入生成文本嵌入。
通過多次抽樣生成更多的嵌入,增強了特徵空間中的數據增強效果。
最後,使用統一的對比學習方案對齊輸入嵌入和生成的嵌入。

給定一組圖像-文本對 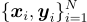 ,其中
,其中 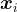 是圖像,
是圖像,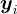 是其對應的文本描述,使用兩個編碼器:一個用於圖像,一個用於文本。
是其對應的文本描述,使用兩個編碼器:一個用於圖像,一個用於文本。
圖像編碼器提取圖像特徵向量 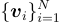 ,文本編碼器提取文本特徵向量
,文本編碼器提取文本特徵向量 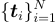 。
。
本研究使用圖像-文本嵌入對 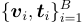 進行 InfoNCE 損失的訓練。
進行 InfoNCE 損失的訓練。
InfoNCE (Information Noise Contrastive Estimation) 損失是一種用於學習表徵的對比損失函數,通常在對比學習中使用,旨在最大化正樣本對之間的相似度,同時最小化負樣本對之間的相似度。
這種損失函數常用於無監督學習和自監督學習的任務,例如圖像和文本的對比學習。
基於擴散的嵌入生成器,如 DALL-E 2 等模型預訓練,用於在圖像和文本領域之間轉換嵌入。
從基於擴散的生成器生成的嵌入作為生成分佈中的增強樣本。
這些樣本可以無限生成,以擴展有限的現實世界訓練數據。
本研究使用了 BERT 類似的 12 層 Transformer 作為文本編碼器,以及 Vision Transformer ViT-B/32 作為視覺編碼器。
擴散先驗模型 DALL-E 2 在 LAION 400M 上預訓練的嵌入生成器用於嵌入生成。
所提出的模型在 YFCC-15M 數據集上進行訓練,這是 CLIP 中使用的 YFCC 100M 的子集。
模型在下游任務上進行評估,包括 ImageNet 的圖像分類和 COCO 及 Flickr30K 的圖像-文本檢索。
表格比較了不同的視覺-語言預訓練方法在視覺和視覺-語言任務上的不同監督和增強策略。

該表格包括在 ImageNet-1K 上的圖像分類和在 COCO 及 Flickr30K 上的圖像-文本檢索。所有模型在相同的骨幹、數據集和訓練設置下進行評估。
