今天我們開始實際開發,重點是建立Spring boot專案。
以後程式碼的改動都會使用此git
https://github.com/a951753sxd/rental-crawler
首先,我們利用 Spring Initializr 建立了一個 Java Maven 專案。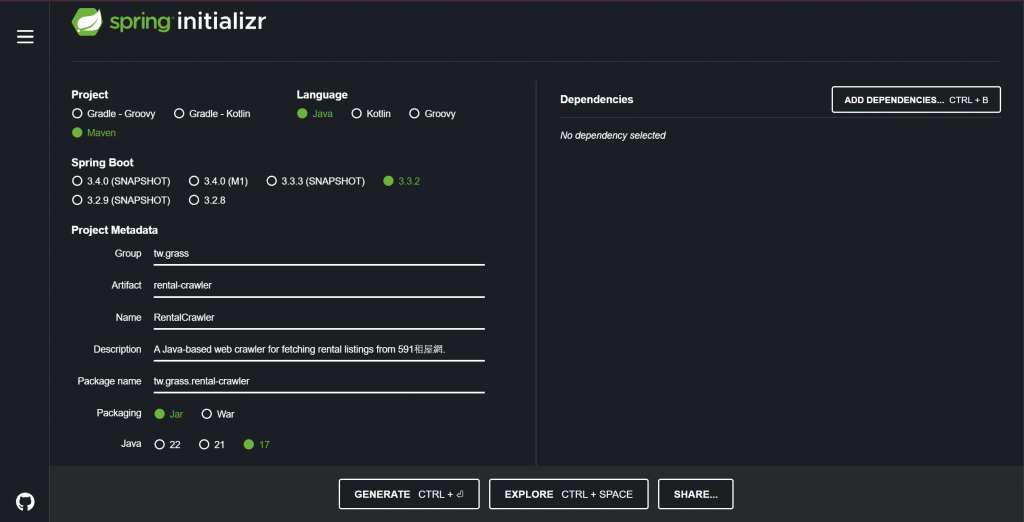
簡要說明一下依賴到哪些工具
定義Log的層級、格式等...
<!-- logback.xml -->
<configuration>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%d][%p][%t][%C{0}:%L]: %msg%n</pattern>
</encoder>
</appender>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>logs/app.log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<Pattern>
<pattern>[%d][%p][%t][%C{0}:%L]: %msg%n</pattern>
</Pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- rollover daily -->
<fileNamePattern>logs/app.%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="console" />
<appender-ref ref="file" />
</root>
</configuration>
接著,我們在專案中建立了一個 RentalCrawlerService 介面。
目前只有一個方法,為抓取資料
package tw.grass.rental_crawler.service;
public interface RentalCrawlerService {
void fetchRentalData();
}
實作類別 RentalCrawlerServiceImpl
切分介面與實作,這樣的設計有助於未來進行擴展和測試。
package tw.grass.rental_crawler.service.impl;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.stereotype.Service;
import tw.grass.rental_crawler.service.RentalCrawlerService;
@Service
public class RentalCrawlerServiceImpl implements RentalCrawlerService {
Logger log = LoggerFactory.getLogger(RentalCrawlerService.class);
@Override
public void fetchRentalData() {
log.info("Starting to fetch rental data...");
try {
//這邊使用591的條件other=newPost:新上架、sort=posttime_desc:排序為新到舊
String urlString = "https://rent.591.com.tw/list?other=newPost&sort=posttime_desc";
// 提取連結中的HTML資訊
Document doc = Jsoup.connect(urlString).get();
// 在這裡解析HTML並提取所需數據
parseHTML(doc);
log.info("Successfully fetched rental data");
} catch (Exception e) {
log.error("Error while fetching rental data", e);
}
}
//TODO: 處理資料邏輯代寫
private void parseHTML(Document doc) {
}
}
那服務完成後,目前沒有程式進入點
目前為啟動程式一次,就去爬取資料一次
Autowired我們的Service後 執行fetchRentalData
package tw.grass.rental_crawler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
import tw.grass.rental_crawler.service.RentalCrawlerService;
@Component
public class StartupRunner implements ApplicationRunner {
@Autowired
RentalCrawlerService rentalCrawlerService;
@Override
public void run(ApplicationArguments args) throws Exception {
rentalCrawlerService.fetchRentalData();
}
}
目前的專案長這樣,還是建議直接拉git看,會比較清楚。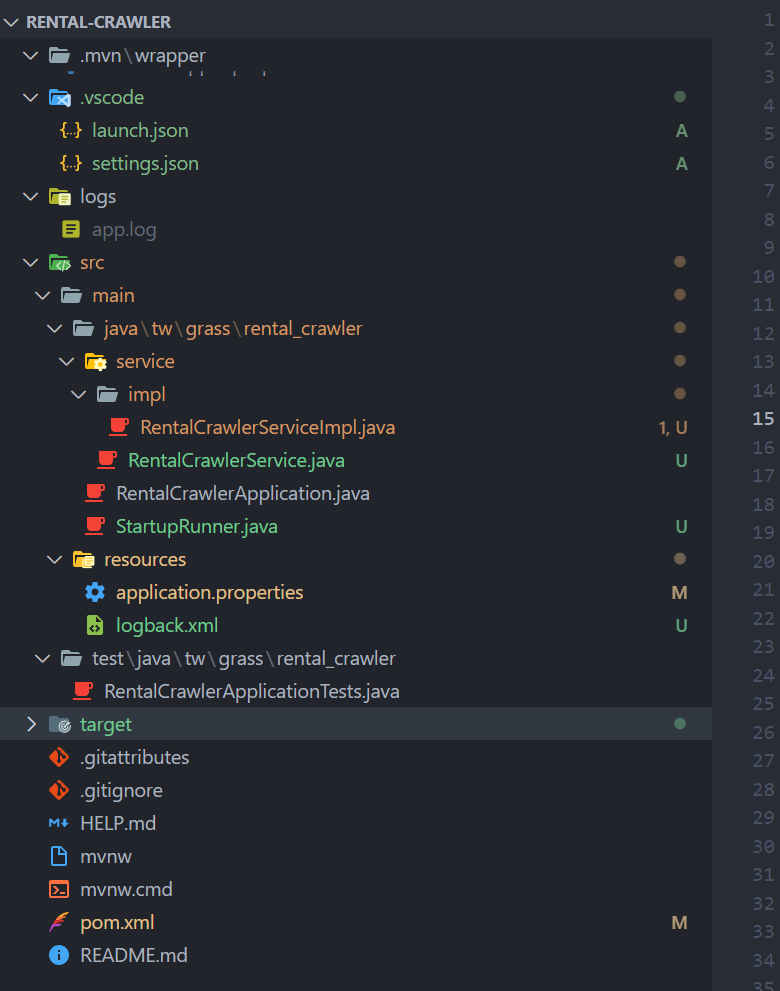
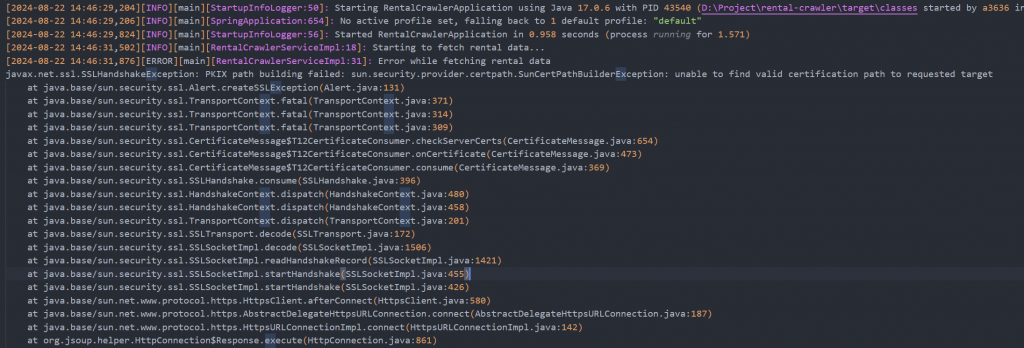
這個錯誤是由於 SSL 握手失敗引起的,具體來說是因為 Java 無法建立與目標網站的安全連接。
總之就是Java不信任591這個網站。
今天我們完成了專案架構的搭建,並開始編寫爬蟲邏輯。同時,透過 Logback 的設置,我們能夠有效地追蹤爬蟲執行過程中的各種訊息。
明天我們將處理 SSL 憑證驗證問題,這在抓取一些需要安全連接的網站時非常關鍵。隨著專案逐步推進,我們也會進一步優化爬蟲邏輯和資料提取方法。


 iThome鐵人賽
iThome鐵人賽