這篇會根據之前所學( requests + BeautifulSoup )去實際操作練習
查詢微信公眾號的文章的網址 :
首先我們要下載wechat電腦端(我使用 window 系統)大家可以根據自己電腦系統去下載。下載完後登入自己wechat帳號。
接下來,找一個公眾號內的文章 ( 以鄧超工作室內最新文章為例)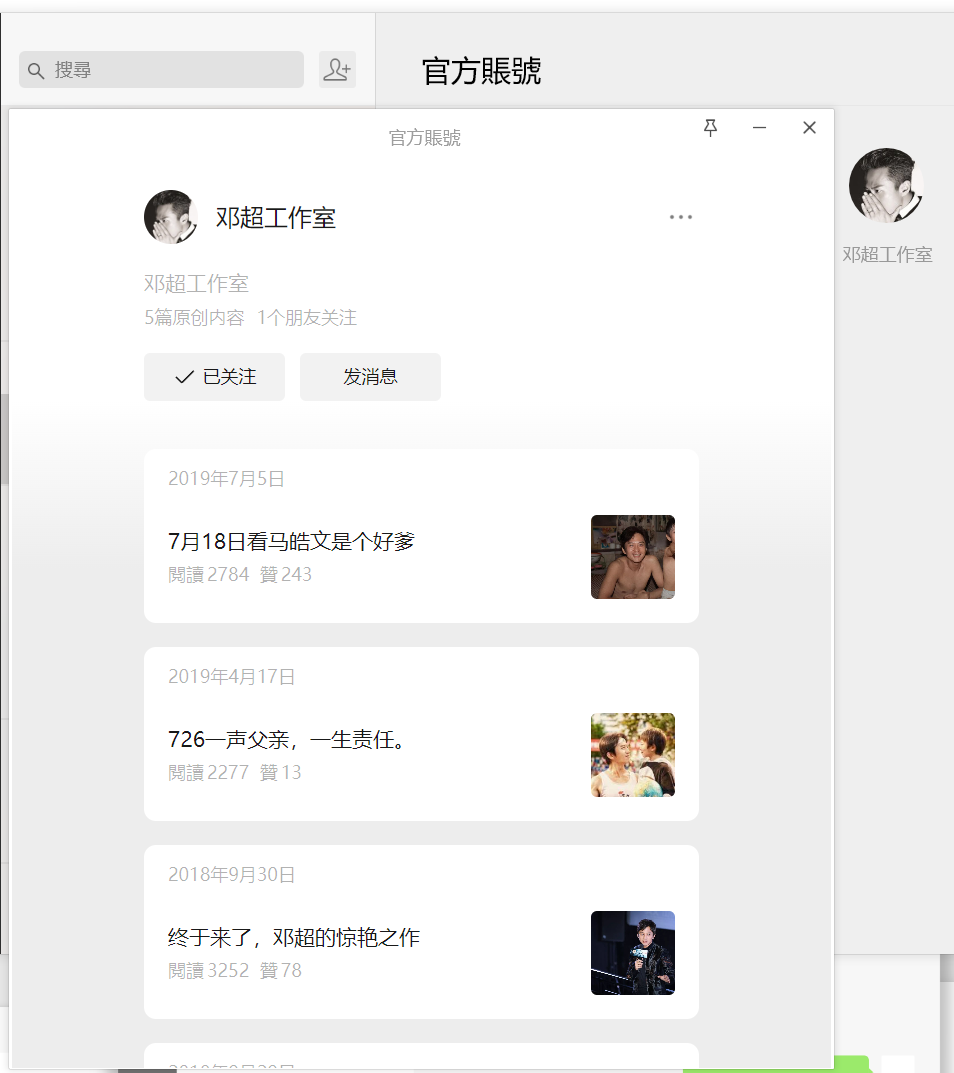
再來,點擊瀏覽器icon他會跳到你電腦預設的瀏覽器內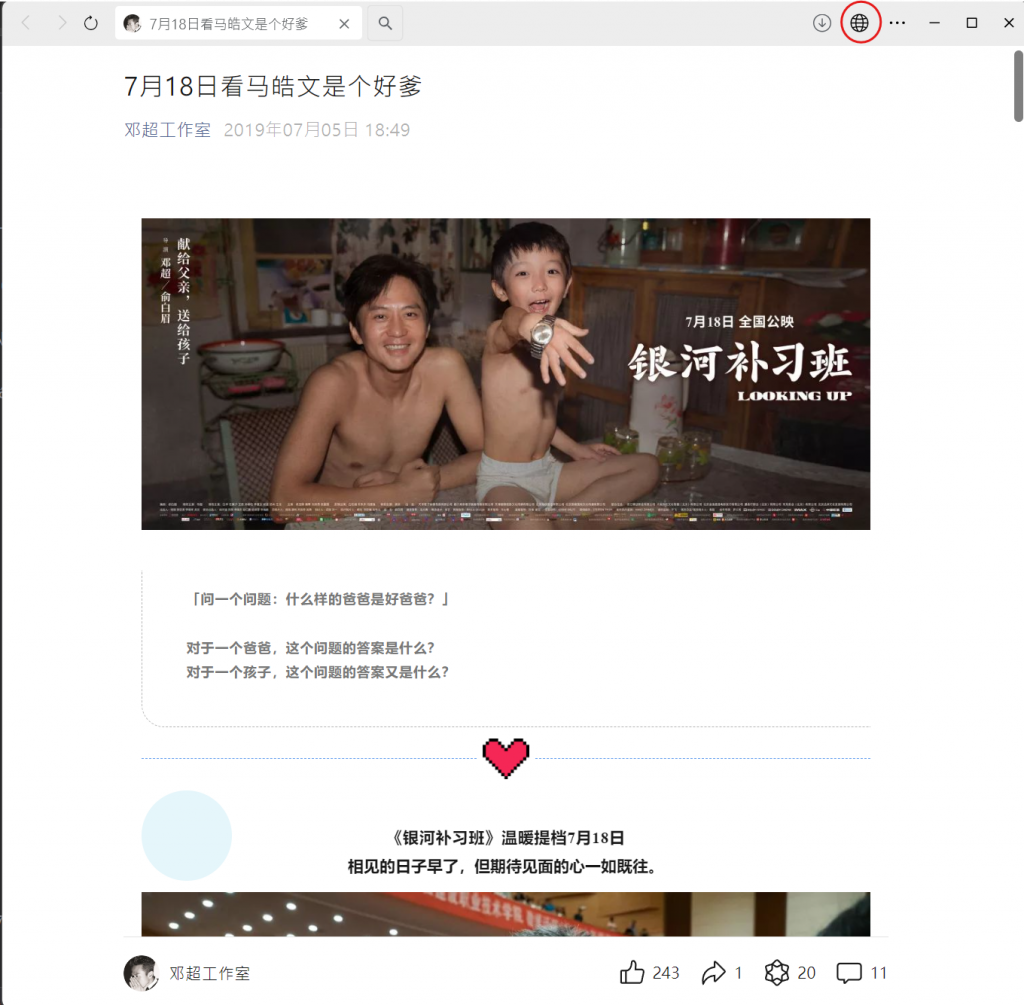
此時你就可以知道這篇文章的網址了 !
import requests # 用於發送 HTTP 請求
import os # 用於創建目錄和處理文件系統
from bs4 import BeautifulSoup # 用於解析 HTML 內容
# 網頁 URL
url = 'https://mp.weixin.qq.com/s/B0URjghrolg7HWVcZNUH5Q'
# 發送請求並獲取頁面內容
response = requests.get(url)
web_content = response.text
# 使用 BeautifulSoup 解析 HTML 內容
soup = BeautifulSoup(web_content, 'html5lib')
# 查找 h1 標籤並提取標題
title_element = soup.find('h1', id='activity-name')
title = title_element.text.strip() # 去除標題文本的前後空白
print(title)
# 查找 div 標籤,並提取所有 p 標籤的文本內容
d = soup.find('div', id='js_content')
if d:
pp = d.find_all('p') # 查找所有 p 標籤
for p in pp:
print(p.text.strip()) # 打印每個 p 標籤的文本內容,去除前後空白
else:
print('Content div not found.')
# 保存到文件
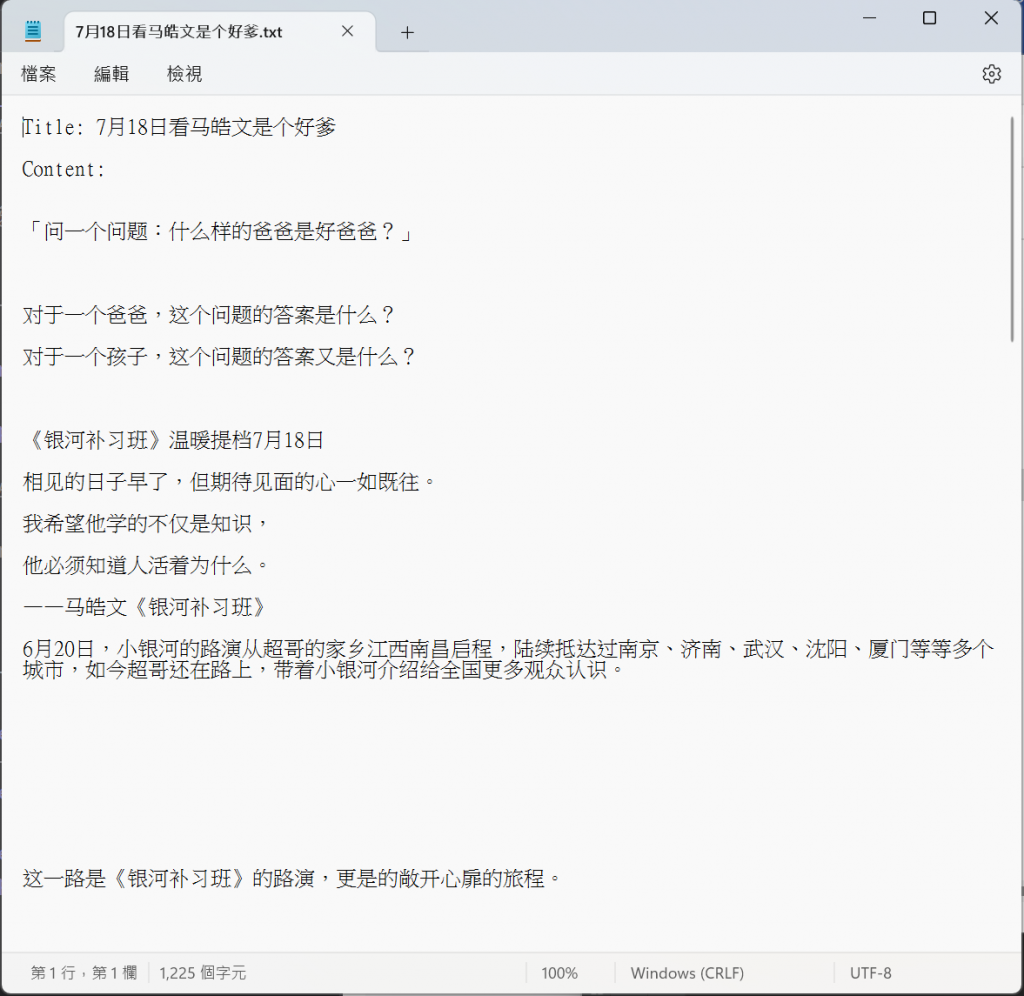
filename = f'{title}.txt' # 使用標題作為文件名
with open(filename, 'w', encoding='utf-8') as file:
file.write(f'Title: {title}\n\n') # 寫入標題
file.write('Content:\n')
for p in pp:
file.write(f'{p.text.strip()}\n\n') # 寫入每個 p 標籤的文本內容
print(f'Content saved to {filename}')


 iThome鐵人賽
iThome鐵人賽