繼續上一篇保存文章文字內容,這一篇我稍微做更改,改成保存文章內的照片,其實步驟大同小異,只要找出照片在哪個 html 內,他的屬性是什麼,去做更改就可完成
跟上篇一樣的查詢網址步驟 :
首先我們要下載wechat電腦端(我使用 window 系統)大家可以根據自己電腦系統去下載。下載完後登入自己wechat帳號。
接下來,找一個公眾號內的文章 ( 以鄧超工作室內最新文章為例)
!https://ithelp.ithome.com.tw/upload/images/20240826/20168345xmooI0LoEg.png
再來,點擊瀏覽器icon他會跳到你電腦預設的瀏覽器內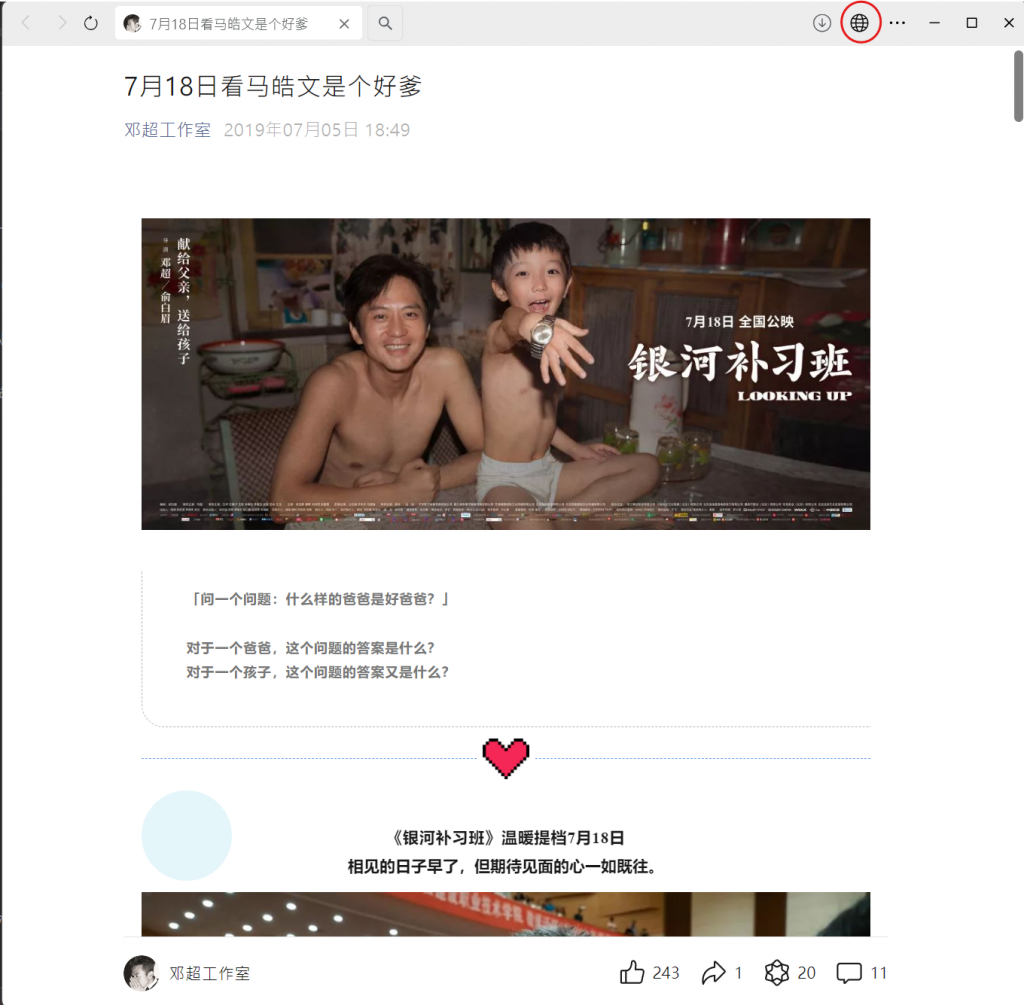
此時你就可以知道這篇文章的網址了 !
import requests # 用於發送 HTTP 請求
import os # 用於創建目錄和處理文件系統
from bs4 import BeautifulSoup # 用於解析 HTML 內容
# 網頁 URL
url = 'https://mp.weixin.qq.com/s/B0URjghrolg7HWVcZNUH5Q'
# 發送請求並獲取頁面內容
response = requests.get(url)
web_content = response.text
# 使用 BeautifulSoup 解析 HTML 內容,以查找和提取需要的元素
# 解析頁面內容
soup = BeautifulSoup(web_content, 'html5lib')
# 查找 h1 標籤並提取標題
title_element = soup.find('h1', id='activity-name')
if title_element:
title = title_element.get_text(strip=True) # 擷取標題文字並去除前後空白
print(f'標題: {title}')
else:
print('沒有找到標題')
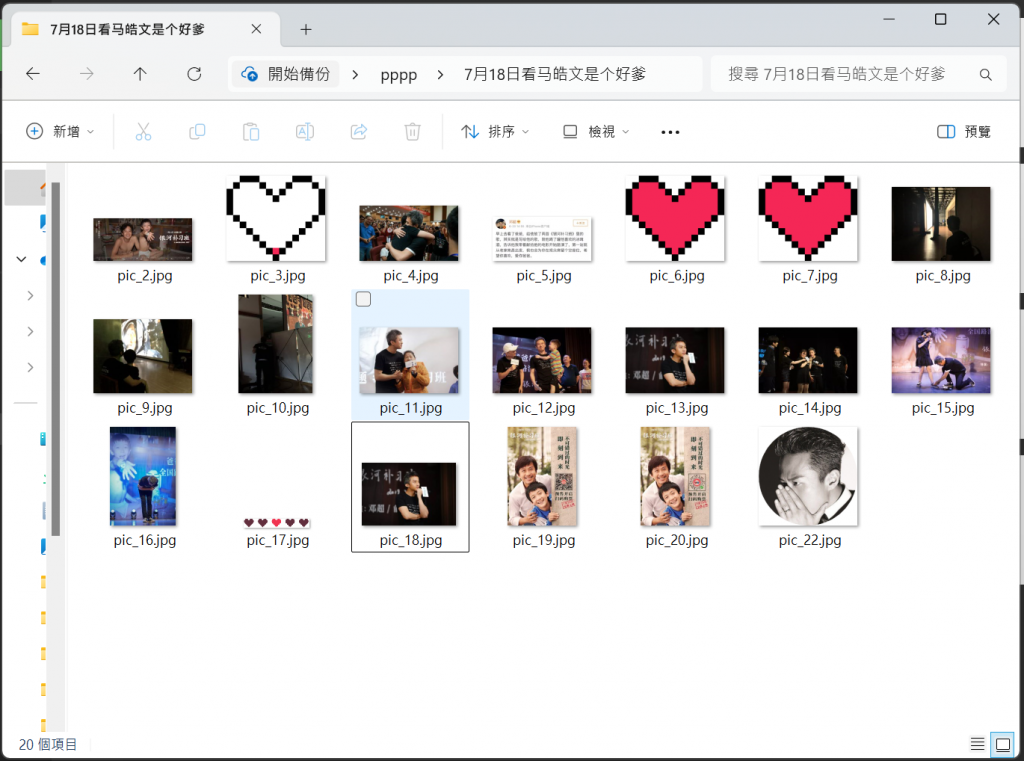
# 創建文件夾,以保存圖片
if not os.path.exists(title):
os.makedirs(title)
# 查找所有 img 標籤
img_elements = soup.find_all('img')
# 下載圖片
for index, img in enumerate(img_elements):
# 提取 data-src 屬性中的 URL,若沒有則嘗試 src 屬性
img_url = img.get('data-src') or img.get('src')
if img_url:
print(f'圖片 {index + 1} URL: {img_url}')
response = requests.get(img_url, stream=True) # 以stream模式下載圖片
if response.status_code == 200:
# 保存圖片到本地文件夾
with open(f'{title}/pic_{index + 1}.jpg', 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f'圖片 {index + 1} 下載完成')
else:
print(f'圖片 {index + 1} 下載失敗,狀態碼: {response.status_code}')
else:
print(f'圖片 {index + 1} 沒有有效的 URL')


 iThome鐵人賽
iThome鐵人賽
{kind=link}