我們昨天把詞袋 ( BoW ) 的概念和實作講完了,今天來聊聊更進階的 Word2Vec。
我們在 Day 18 介紹各種文本表示方式的時候,有提到詞嵌入 ( Word Embedding ) 可以在把文字向量化的同時,捕捉單詞的語意,而 Word2Vec 正是在這樣的概念下產生的一種技術。
Word2Vec 是 Word to Vector 的簡稱,顧名思義就是希望將文字轉換為詞向量 ( Word Vector ) 的表現形式,它使用到了兩種和神經網路相關的訓練方法,一個是 Continuous Bag of Words ( CBOW ),一個是 Skip-Gram,我們會分別介紹。
首先是 CBOW,它的想法是通過上下文的單詞 ( context words ) 來預測中心詞 ( target word ),舉個例子來說:
Tom is very [happy] because he got a perfect score.
相信大家都有寫過填空或克漏字的題目吧,我們要做的事情就是把中括號裡面的 target word 挖掉,然後想辦法讓模型成功預測出這個單詞。
下面這張圖是 CBOW 的訓練方式: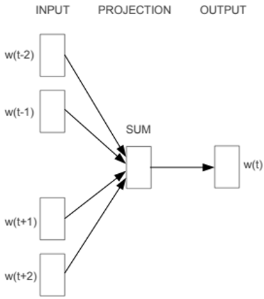
首先,我們假設單詞是按照 One-hot Encoding 來編碼,然後選定中心詞,根據設定的窗口大小 ( Window Size ) 決定在輸入層要放入哪些上下文的單詞。
窗口大小指的是距離中心詞左右幾個單詞,假設我設定 Window Size = 2,那麼輸入層就會放入 is、very、because、he 這四個單詞的編碼,然後進行訓練。
在神經網路最後的輸出層,我們會獲得預測單詞的機率分布,計算 loss 之後再繼續訓練,最後獲得一組詞向量。
而 Skip-Gram 則剛好相反,我們直接來看它的訓練方式: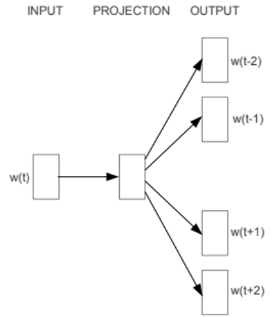
它的想法反而是給定一個中心詞,讓它去推測上下文可能的單詞是哪些。
以上面那個例子來說,就是在輸入層給了 happy 的詞向量,同樣設定 Window Size = 2,然後經過神經網路訓練之後預測出它周圍的四個單詞。
經由以上兩種不同的訓練方式,我們最終可以獲得單詞向量化後的結果,並應用在計算語意相似度、文本分類的任務上。
然而 Word2Vec 也還存在不足的地方,因為它為每個單詞都生成了一個固定長度的向量,所以在所有的情境中,同樣的單詞都只會用這個向量表示。
就好像我們之前提到過的例子:
I ate an apple.
I work at Apple.
一個代表的是水果,一個是科技公司的名字,如果使用相同向量的話就代表他們在向量空間中是同一個點,也就是語意相同,這會導致模型對文本理解產生錯誤的問題。
也因為 Word2Vec 存在這樣的問題,後來又提出了 GloVe 或 FastText 等改善後的模型,直到 2017 年 Google 提出基於 Self-Attention 機制的 Transformer,讓語言模型相關的研究又有了突破性的進展。
參考文章


 iThome鐵人賽
iThome鐵人賽