當我們打開 OpenAI 官方網站,找到對於 ChatGPT 的介紹,可以得知它是從 GPT3.5 模型微調而來,經過某些監督式的訓練以及強化學習的方式,讓它更適合處理和人類對話相關的任務,無論是聊天、問答或是創作,它都有辦法生成出一段回應。
然而像 ChatGPT 這樣的模型也存在著侷限性,正因為它被訓練出來的目標是對使用者生成流暢、有意義的文字,在提供資訊的部分反而沒有辦法保證內容的正確性,因此在一些情況下,它可能會生成一些似是而非的內容。
比方說我對 ChatGPT (4o-mini) 問了這麼一個問題:
中華民國憲法第 166 條的正確條文是什麼?
這是它的回答:
中華民國憲法第 166 條的正確條文如下:
第 166 條:法院之組織及職掌,由法律定之。
看起來有模有樣的,但其實正確的條文是:
第 166 條:國家應獎勵科學之發明與創造,並保護有關歷史、文化、藝術之古蹟、古物。
像遇到這樣的幻覺 (Hallucination) 現象,我反而還要花時間上網驗證這些內容的正確性,也讓 ChatGPT 的可信度大幅降低。
PS : 不過我對 4o 測試了幾個問題,雖然沒有到每個字都一樣,但內容基本正確了
而這一兩年包括 ChatGPT、Gemini、Claude 等 LLM 也不斷的在進化,讓模型回答的越來越好。
不過我今天想要聊的是如何在不進行微調的情況下,使用這些模型來生成更準確和更有針對性的內容,而且大家都可以做做看的方式,也就是我在 Day 24 提到的檢索增強生成技術。
檢索增強生成 ( Retrieval-Augmented Generation, RAG ) 是一種結合了資訊檢索和生成模型的技術,它的概念就是通過檢索的方式找出正確的資訊,再將這些資訊提供給 LLM 生成回應。
這種方法就好像我們在寫題目的時候不知道該怎麼回答,就會想辦法去找到正確資料來參考一樣,而這也是我之前想要介紹資訊檢索 ( IR ) 的原因之一。
由於 LLM 本身可能對一些比較專業或最新的知識沒那麼熟悉,就像我剛剛提的例子,而 RAG 的優勢就在於它可以解決 LLM 在這方面的困擾,同時兼顧敘述的流暢性和內容的正確性,也因此直到現在都是一個蠻不錯的解決方案。
說了那麼多,接著就來看看 RAG 的架構吧!
在 2020 年的論文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中介紹了 RAG 的兩個區塊,檢索器(Retriever)和生成器(Generator)。
其中,Retriever 負責把使用者的問題編碼成向量,然後在文檔中進行檢索,找出最相關的內容,接著,這些資料會再傳入 Generator,讓模型基於這些資料來生成合適的回應。
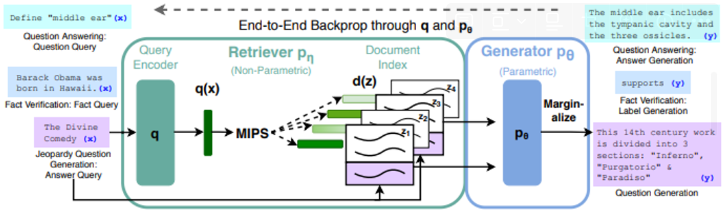
不過在使用 RAG 的同時,也需要注意一些隱藏的問題:
通過 RAG 技術,我們可以用相較於微調代價更小的方式,來讓模型生出更正確的內容,這對於即時性資料或特定領域知識的問答任務來說非常好用,而現在許多研究的確也有朝著「檢索+生成」的趨勢前進,比方說 Perplexity 或最近討論比較多的 SearchGPT。
那麼今天就先到這邊啦,明天來介紹如何用 Langchain 的工具實作 RAG 吧!
推薦文章


 iThome鐵人賽
iThome鐵人賽