上一篇文章了解 Agent 的用途,也實作了簡單的 Agent。那基於這個簡單的例子,要來把生成式 AI 的另外兩個技術:RAG、Memory 功能與 Agent 做結合,透過簡單的實作來將 LangChain 中比較常被用到的技術結合在一起。
實作之前先來介紹今天要使用的兩個 Agent 工具:
要使用 RAG 的話,那就必須使用到這個工具,只要針對這個工具命名與描述使用時機即可。
# 匯入套件
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_qdrant import QdrantVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import Distance
from langchain.tools.retriever import create_retriever_tool
# 選擇模型
llm = ChatOpenAI(model="gpt-4o", temperature=0)
embeddings = OpenAIEmbeddings()
client = QdrantClient(url="http://localhost:6333")
collections_name = "ithome-Agent"
# 若 collection 存在則刪除 (現在沒有recreate函數)
if client.collection_exists(collection_name=collections_name):
client.delete_collection(collection_name=collections_name)
else:
pass
# 建立一個新的 collections
client.create_collection(
collection_name=collections_name,
vectors_config=
models.VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
# langchain 連線 Qdrant 已存在的 collections
qdrant_vector_store = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name=collections_name,
embedding=embeddings,
)
# 切割內容
loader = WebBaseLoader("https://www.nba.com/news/zaccharie-risacher-hawks-2024-nba-draft")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
split_docs = splitter.split_documents(docs)
# 將資料匯入 Qdrant
qdrant_vector_store.add_documents(documents=split_docs)
retriever = qdrant_vector_store.as_retriever(search_kwargs={"k": 3})
# 建立 tools
retriever_tool = create_retriever_tool(
retriever,
"nba_draft_search",
"Use this tool when searching for information about 2024 NBA draft"
)
程式碼結果探討 🧐:
create_retriever_tool 包裝成一個 Tool,那因為這個網頁是在講 NBA 2024 的選秀,所以名字給他取 nba_draft_search,描述的部分就是輸入有關 2024 NBA 選秀的部分就會去進行檢索。這是另一個很特別的工具,他是專門開發給 Agent 使用的 Tool。這個工具的目標是消弭 AI 系統與來自網絡的實時、事實信息之間的差距,但當然最即時的資訊可能還是有差,但是我必須說真的是很強很強的工具了!
Tavily 跟 Upstash-Redis 一樣有提供免費額度給使用者使用,每個月是 1000 次的 requests,對我來說其實挺夠用的,在測試上也很方便。
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()
程式碼結果探討 🧐:
# 匯入套件
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.tools.retriever import create_retriever_tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.messages import HumanMessage, AIMessage
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_qdrant import QdrantVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import Distance
from langchain.tools.retriever import create_retriever_tool
# 選擇模型
llm = ChatOpenAI(model="gpt-4o", temperature=0)
embeddings = OpenAIEmbeddings()
client = QdrantClient(url="http://localhost:6333")
collections_name = "ithome-Agent"
# 若 collection 存在則刪除 (現在沒有recreate函數)
if client.collection_exists(collection_name=collections_name):
client.delete_collection(collection_name=collections_name)
else:
pass
# 建立一個新的 collections
client.create_collection(
collection_name=collections_name,
vectors_config=
models.VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
# langchain 連線 Qdrant 已存在的 collections
qdrant_vector_store = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name=collections_name,
embedding=embeddings,
)
# 讀取網頁並切割內容
loader = WebBaseLoader("https://www.nba.com/news/zaccharie-risacher-hawks-2024-nba-draft")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
split_docs = splitter.split_documents(docs)
# 將資料匯入 Qdrant
qdrant_vector_store.add_documents(documents=split_docs)
retriever = qdrant_vector_store.as_retriever(search_kwargs={"k": 3})
# 建立 retriever tools
retriever_tool = create_retriever_tool(
retriever,
"nba_draft_search",
"Use this tool when searching for information about 2024 NBA draft"
)
# 建立 tavily tools
search = TavilySearchResults()
tools = [search, retriever_tool]
# 設定 prompt
prompt = ChatPromptTemplate.from_messages([
("system", "You are the friendly assistant called Lulu"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# 建立 Agent
agent = create_openai_functions_agent(
llm=llm,
prompt=prompt,
tools=tools,
)
# 設定 Agent 的 Chain
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True
)
# 建立函數來執行對話
def proccess_chat(agent_executor, user_input, chat_history):
response = agentExecutor.invoke({
"input": user_input,
"chat_history": chat_history
})
return response['output']
# 開始與 AI 對話
if __name__ == "__main__":
chat_history = []
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
response = proccess_chat(agentExecutor, user_input, chat_history)
chat_history.append(HumanMessage(content=user_input))
chat_history.append(AIMessage(content=response))
print("Assistant : ", response)
可以如我所設定的詢問關於 2024 NBA 選秀的內容,模型有去檢索資料庫,並回傳正確的內容。那如果資料庫內容很豐富的話可以多建立幾個 Tools,讓 AI 自己去判別什麼問題要去檢索那個資料庫。那因為 tavily 這個工具太強了,RAG 先 demo 到這邊~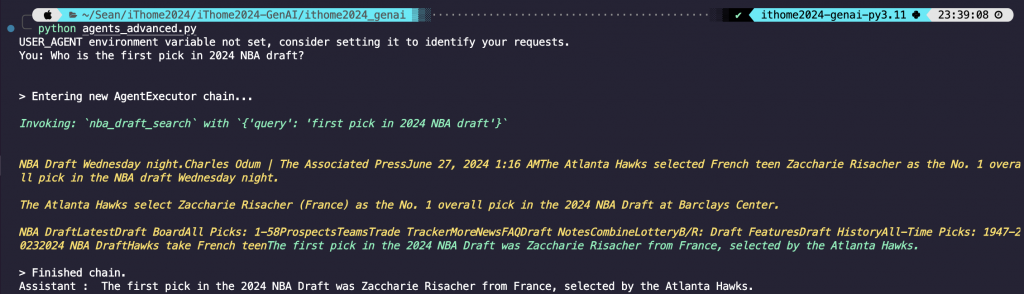
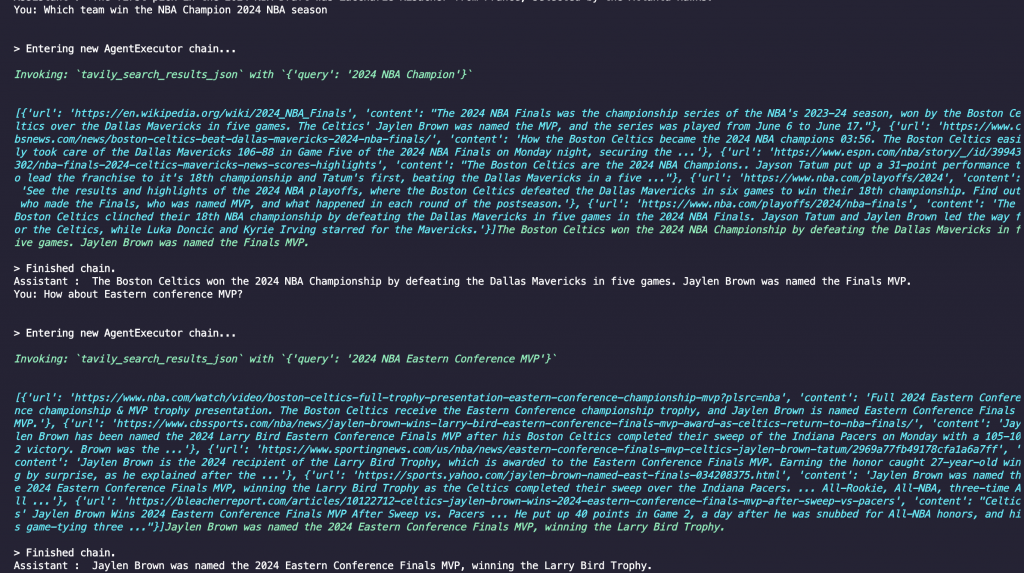

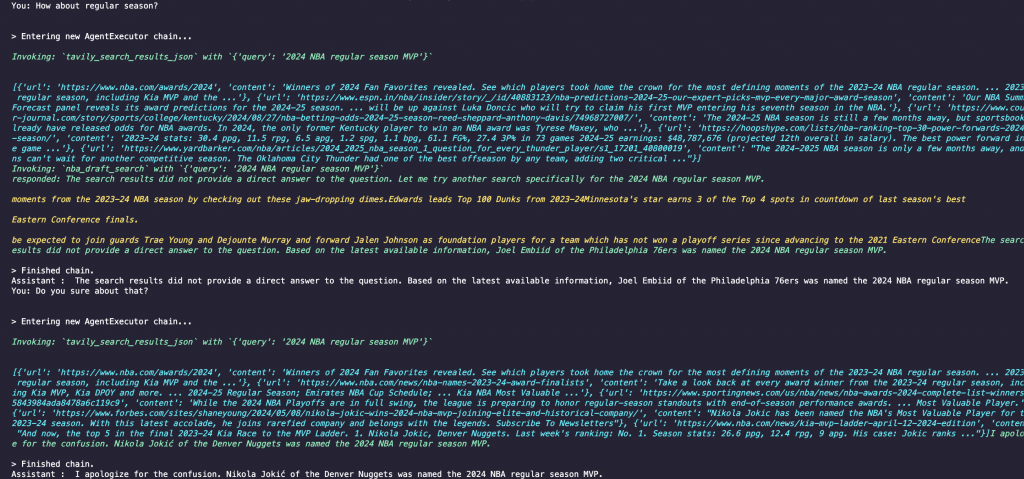
總共有三個部分:
# 匯入套件
from dotenv import load_dotenv
import os
load_dotenv()
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.tools.retriever import create_retriever_tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_openai_functions_agent, AgentExecutor
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_qdrant import QdrantVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.http.models import Distance
from langchain.tools.retriever import create_retriever_tool
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories.upstash_redis import UpstashRedisChatMessageHistory
# 選擇模型
llm = ChatOpenAI(model="gpt-4o", temperature=0)
embeddings = OpenAIEmbeddings()
client = QdrantClient(url="http://localhost:6333")
collections_name = "ithome-Agent"
# 若 collection 存在則刪除 (現在沒有recreate函數)
if client.collection_exists(collection_name=collections_name):
client.delete_collection(collection_name=collections_name)
else:
pass
# 建立一個新的 collections
client.create_collection(
collection_name=collections_name,
vectors_config=
models.VectorParams(
size=1536,
distance=Distance.COSINE,
),
)
# langchain 連線 Qdrant 已存在的 collections
qdrant_vector_store = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name=collections_name,
embedding=embeddings,
)
# 切割內容
loader = WebBaseLoader("https://www.nba.com/news/zaccharie-risacher-hawks-2024-nba-draft")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
split_docs = splitter.split_documents(docs)
# 將資料匯入 Qdrant
qdrant_vector_store.add_documents(documents=split_docs)
retriever = qdrant_vector_store.as_retriever(search_kwargs={"k": 3})
# 建立 tools
retriever_tool = create_retriever_tool(
retriever,
"nba_draft_search",
"Use this tool when searching for information about 2024 NBA draft"
)
search = TavilySearchResults()
tools = [search, retriever_tool]
# 設定 prompt
prompt = ChatPromptTemplate.from_messages([
("system", "You are the friendly assistant called Lulu"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
]
)
# 建立 agent
agent = create_openai_functions_agent(
llm=llm,
prompt=prompt,
tools=tools,
)
# 設定 Agent 的 Chain
agentExecutor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True
)
# 設定儲存對話紀錄至 Upstash-Redis
def get_session_history(session_id: str) -> BaseChatMessageHistory:
return UpstashRedisChatMessageHistory(
url=os.environ['UPSTASH_REDIS_REST_URL'],
token=os.environ['UPSTASH_REDIS_REST_TOKEN'],
session_id=session_id
)
# 將對話紀錄與 Agent Chain 在一起
agent_with_memory = RunnableWithMessageHistory(
agentExecutor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
# 設定對話函數
def proccess_chat(agent_with_memory, user_input, session_id):
response = agent_with_memory.invoke({'input': user_input}, {'configurable': {'session_id': session_id}})
return response['output']
# 開始與 AI 對話
if __name__ == "__main__":
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
response = proccess_chat(agent_with_memory, user_input, "5")
print("Assistant : ", response)
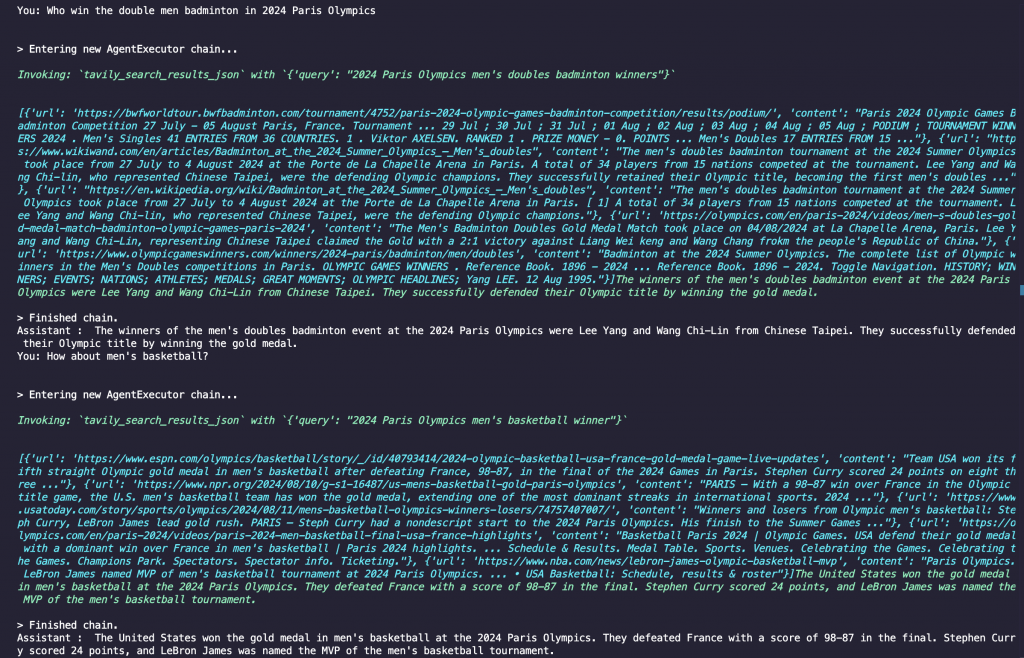
程式碼結果探討 🧐:
RunnableWithMessageHistory 只需要輸入 RunnableAgent 的 Chain 即可,就可以成功儲存對話紀錄,也可以根據任務使用對應的 Tools。今天實作了用 RAG 來當我們的 Tools,也使用了應該是目前最強最方便的工具 - Tavily,可以實現即時資訊的回覆。那也使用了 Memory 的功能,不管是簡單的儲存在環境變數還是 Upstash-Redis,整體感覺其實跟網頁上使用 ChatGPT 非常接近了,真的是很厲害的工具。
這週真的是超爆炸,三個專案趕 8 月底結案,然後還有一個 AI 競賽要交件,下禮拜還要考雲端證照,真的是分身乏術,導致鐵人賽每天都寫不完🥲


 iThome鐵人賽
iThome鐵人賽