上一篇文章介紹了 FlowiseAI,然後成果將其安裝在本機,也使用簡單的實作還要 Call API 的方式從 Python 呼叫。那今天就要來實作使用那些我們在 LangChain 架構中使用過的工具或技術,包含 RAG、Memory、Tools、Agent,那今天的實作先知道在 FlowiseAI 上如何使用這些技術,明天的文章在將這些都整併起來。

結果探討🧐:
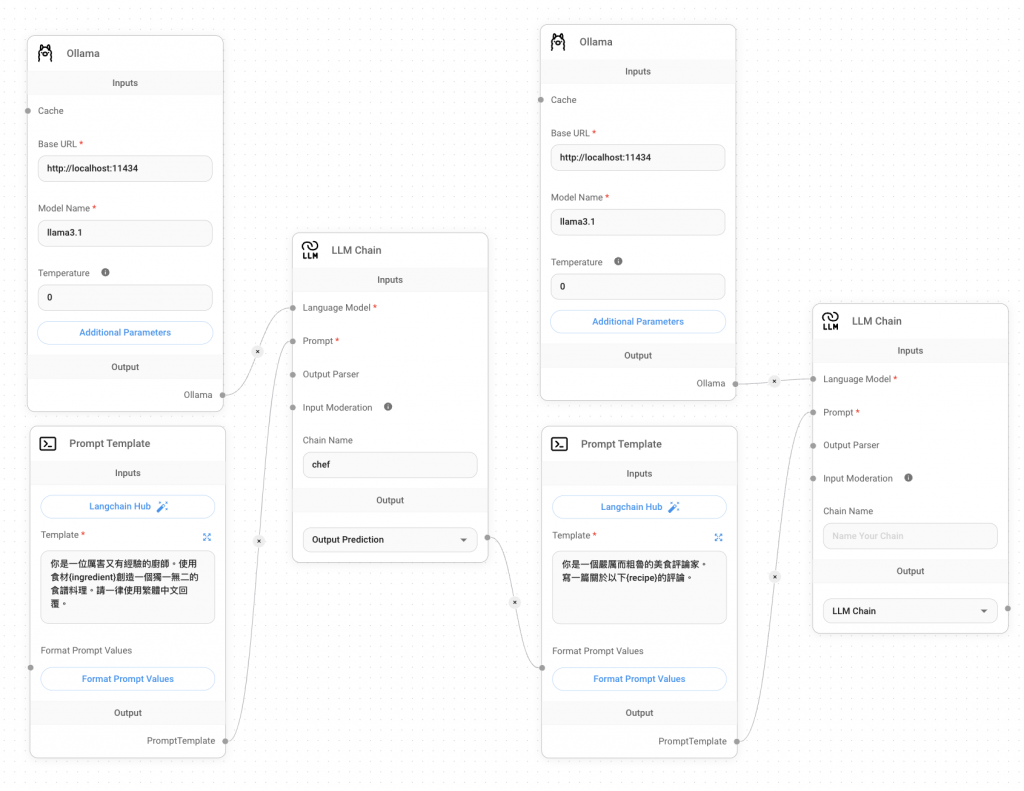
在開始實作前,再來看一個基本的例子。FlowiseAI 可以串接多個 Chain,只要將前一個 Chain 的結果回傳給下一個 Chain 的 Prompt 就可以實現。那這邊用到的 Nodes 都是昨天有用過的,就只有語言模型換成 Ollama~

結果探討🧐:
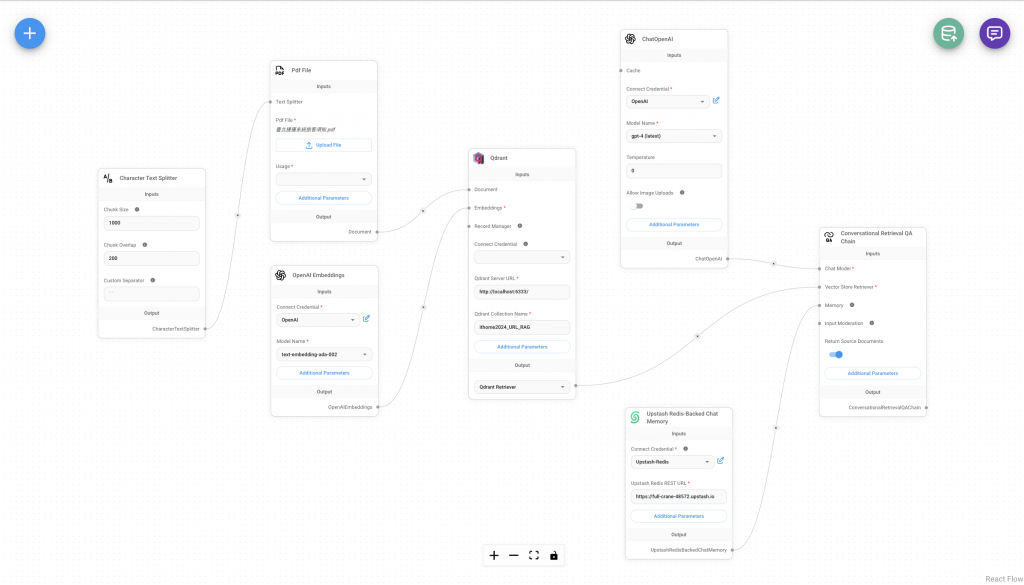
Character Text Splitter:這個就跟在寫 Python 時事一模一樣的設置,只是這個如果有想要拆段的特殊符號,可以自己訂義這個拆段的特殊符號,就會根據我們輸入的符號來拆段落。Document Loader:這邊如果選檔案的話就要上傳檔案,網址的話就要輸入網址。這邊 PDF 檔可以選擇要使用一頁當作 Retriever 就好,還是一整份的 PDF 內容。額外的參數中可以設定 Metadata,透過這個來傳遞一些重要的資訊。OpenAI Embeddings:這個 OpenAI 就是最中規中矩也最好理解的部分,就是填入 OpenAI 的 API,然後選擇模型即可。Qdrant Vector Store:Qdrant Vector Store 需要傳入 Documents 和 Embeddings 兩個物件,以利將文件中內容匯入向量資料庫。網址就選擇本地 Docker 網址即可,如果要使用 Qdrant 雲端記得輸入 API Keys。那其中有一些超參數可以設置,譬如說向量模型轉出的維度有可能不一樣~ChatOpenAI:ChatOpenAI 這個部分就不多贅述了,從寫程式到 FlowiseAI 都是這個模型和參數配置。Upstash-Redis Backed Chat Memory:這邊 Memory 的功能我一樣使用 Upstash-Redis 來存放對話紀錄。那一樣 API 存放在 Credentials,網址貼上,這樣對話紀錄就會自動儲存在 Upstash-Redis 了。Conversational Retrieval QA Chain:前面所設定好的部分,最終都會傳到這個 Nodes,包括 LLM、Retrieval 的結果、Memory 的參數。那可能會有人感覺上為什麼不用寫 Prompt,因為這個 Chain 的函式有預設一組給 RAG 的 Prompt,若想修改就進入 Additional Parameters 就可以了~要上傳資料到資料庫要點擊右上角綠色的資料庫 icon 來上傳喔~
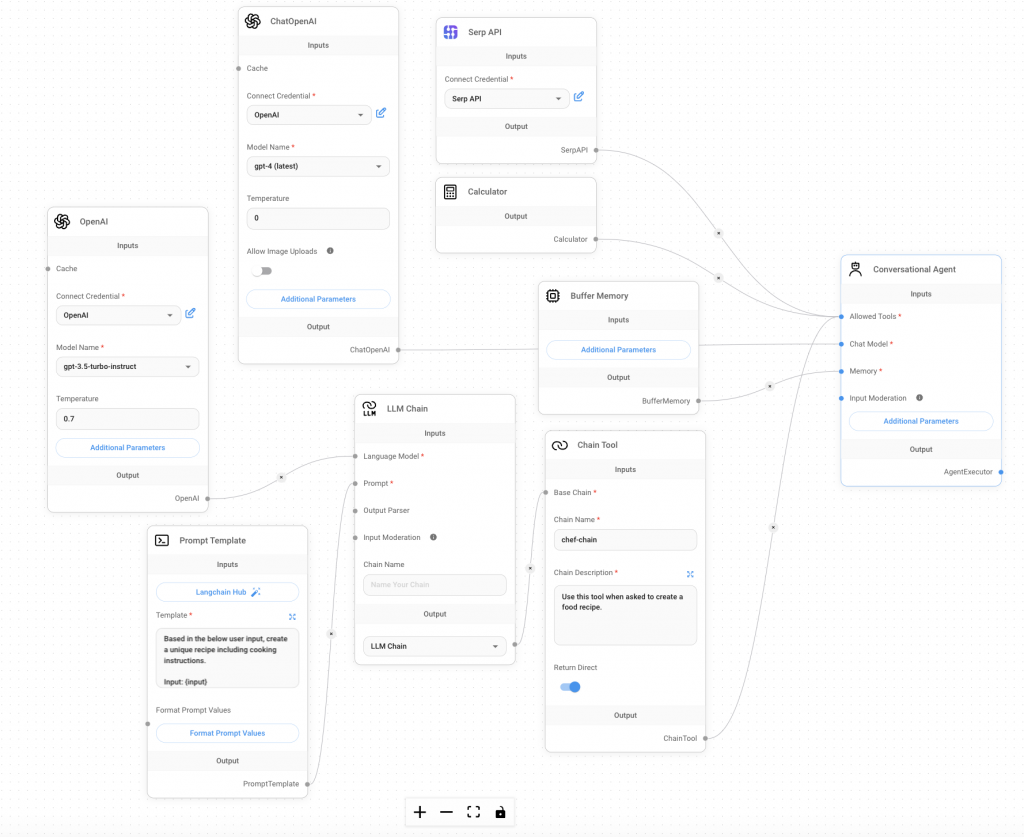
開始實作之前,先來準備一個工具,那就是 SerpAPI。他的功能跟我們前面實作 Agent 的 Tavily AI 有點類似,但這個工具有結合 Google 搜尋引擎。那 SerpAPI 一樣有免費使用的額度,一個月是 100 次的搜尋,註冊後即可開始使用~
結果探討🧐 (前面提過的 Nodes 就不重複說明了):
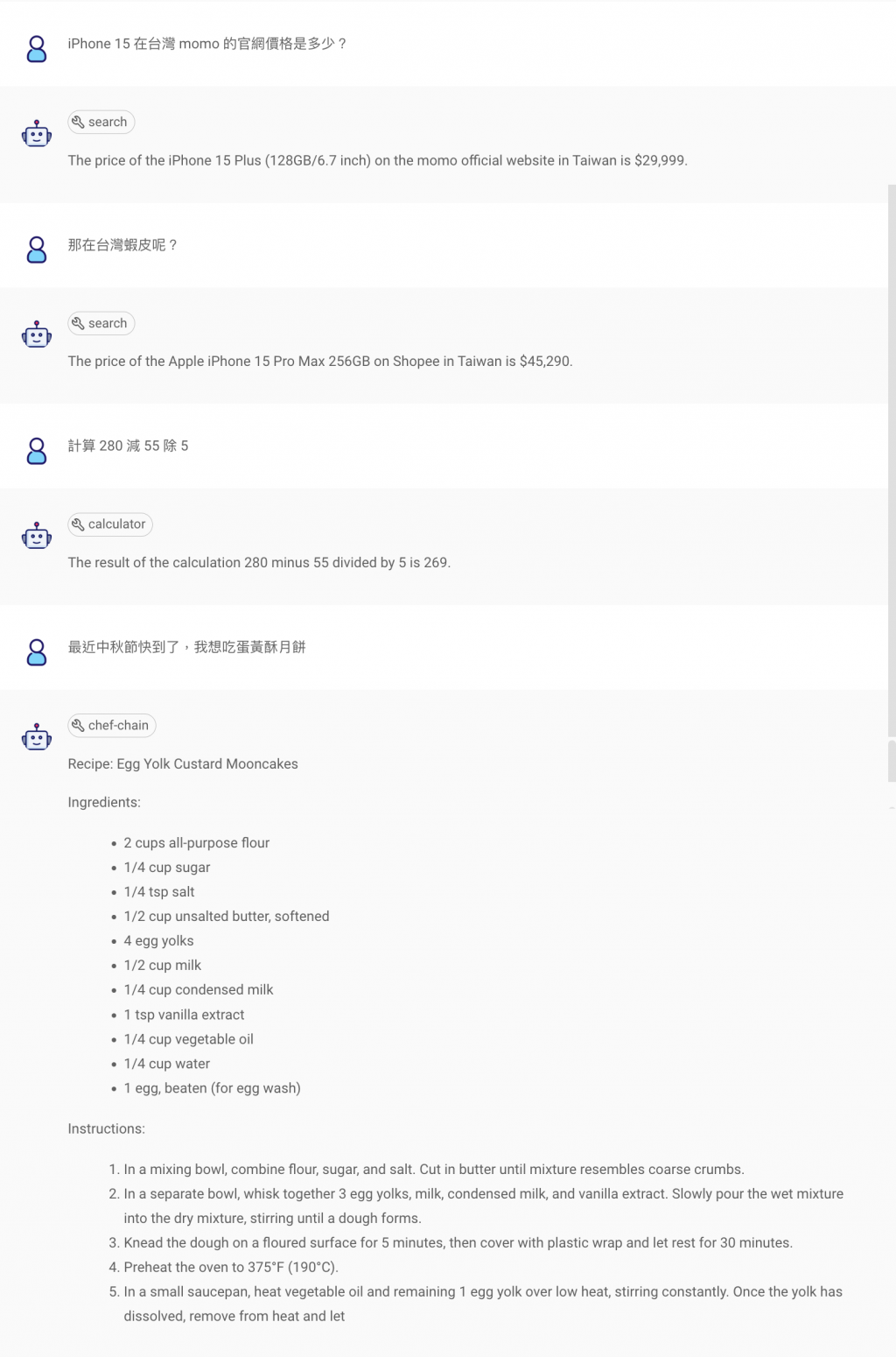
SerpAPI Tool:可以將 API KEY 儲存在 Flowise 的 Credentials。這個工具會將他不知道的內容去做 Google 搜尋,從結果來看效果還不錯。Calculator Tool:這是 FlowiseAI 內建的 Tools,可以針對複雜的數學進行運送。Chain Tool:顧名思義 input 的值會是一個 Chain,那我這邊放的是一個簡單的建立食譜的 Chain,使用的時機是將使用者若有料理的需求,就會該食物或料理的創造食譜。BuffferMemory:簡單來說就是儲存對話紀錄的 Nodes,若對話一直下去就會一直儲存,但若刪除對話內容的話,他的紀錄也會跟著被刪除,他是為了讓 AI 在回答時更大程度參考上下文的內容。今天我們實作了 RAG、Memory、Agent 三種在生成式 AI 中很常被用到的技術,也使用了結合 Google 搜尋的 SerpAPI。那有了實作的經驗之後,明天要將 RAG 的部分變成一個 Tools,然後搭配其他技術和功能,完成一組使用 Agentflows 的成果,作為是 Flowise 章節的結束。
今天一整天要幫我哥搬家,所以文章先產出,細節處會再修正,Agent 和 Tools 的也會再加上。


 iThome鐵人賽
iThome鐵人賽