接續上一章節,為了更方便觀察外部送進來的請求。新增了一個 API
@GET
@Path("/longtime")
@Produces(MediaType.APPLICATION_JSON)
public String day09(@QueryParam(value = "time") Long time) {
try {
log.infof("Sleep %d", time);
Thread.sleep(Duration.ofSeconds(time));
log.info("Get Data.");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "ithomeHello";
}
以及一個可觀察 Quarkus 生命週期的類別。
@ApplicationScoped
public class LifecycleBean {
@Inject
Logger log;
void onStart(@Observes StartupEvent event) {
log.info("The quarkus application is starting...");
}
void onStop(@Observes ShutdownEvent event) {
log.info("The quarkus application is stopping...");
}
}
統整以下場景,並使用上一章節方式觀察,
#!/bin/bash
curl http://localhost:9090/hello/longtime?time=5
curl http://localhost:9090/hello/longtime?time=10
curl http://localhost:9090/hello/longtime?time=20
將使用以下參數與配置進行驗證。
QUARKUS_SHUTDOWN_DELAY=35s
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: gracefulshutdown
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: gracefulshutdown
app.kubernetes.io/version: day08
template:
...
spec:
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: QUARKUS_SHUTDOWN_DELAY
value: "35s"
image: registry.hub.docker.com/cch0124/gracefulshutdown:day08.3
...
第一行是刪除 Pod 之後,馬上發出請求,可以看到在 35s 內接收了三個請求,但最後一個並未執行完成。其
QUARKUS_SHUTDOWN_DELAY 的設定秒數terminationGracePeriodSeconds 預設 30s 已經到了,所以對容器立即發出 KILL2024-08-31 09:39:07,855 INFO [org.cch.ExampleResource] (executor-thread-6) Sleep 5
2024-08-31 09:39:09,089 INFO [org.cch.out.DeviceToPgDatabase] (executor-thread-1) save completed.
2024-08-31 09:39:09,090 INFO [org.cch.out.AlertConsumer] (executor-thread-7) Is OK.
2024-08-31 09:39:09,345 INFO [io.sma.health] (vert.x-eventloop-thread-21) SRHCK01001: Reporting health down status: {"status":"DOWN","checks":[{"name":"SmallRye Reactive Messaging - readiness check","status":"UP","data":{"deviceIn":"[OK]","deviceOut":"[OK]"}},{"name":"Graceful Shutdown","status":"DOWN"},{"name":"Database connections health check","status":"UP","data":{"<default>":"UP"}}]}
2024-08-31 09:39:12,856 INFO [org.cch.ExampleResource] (executor-thread-6) Get Data.
2024-08-31 09:39:12,863 INFO [org.cch.ExampleResource] (executor-thread-6) Sleep 10
...
2024-08-31 09:39:14,090 INFO [org.cch.out.AlertConsumer] (executor-thread-1) Is OK.
...
2024-08-31 09:39:19,091 INFO [org.cch.out.AlertConsumer] (executor-thread-7) Is OK.
2024-08-31 09:39:19,346 INFO [io.sma.health] (vert.x-eventloop-thread-23) SRHCK01001: Reporting health down status: {"status":"DOWN","checks":[{"name":"SmallRye Reactive Messaging - readiness check","status":"UP","data":{"deviceIn":"[OK]","deviceOut":"[OK]"}},{"name":"Graceful Shutdown","status":"DOWN"},{"name":"Database connections health check","status":"UP","data":{"<default>":"UP"}}]}
2024-08-31 09:39:22,863 INFO [org.cch.ExampleResource] (executor-thread-6) Get Data.
2024-08-31 09:39:22,869 INFO [org.cch.ExampleResource] (executor-thread-6) Sleep 20
...
2024-08-31 09:39:24,091 INFO [org.cch.out.AlertConsumer] (executor-thread-7) Is OK.
2024-08-31 09:39:29,092 INFO [org.cch.out.AlertConsumer] (executor-thread-1) Is OK.
2024-08-31 09:39:29,345 INFO [io.sma.health] (vert.x-eventloop-thread-25) SRHCK01001: Reporting health down status: {"status":"DOWN","checks":[{"name":"SmallRye Reactive Messaging - readiness check","status":"UP","data":{"deviceIn":"[OK]","deviceOut":"[OK]"}},{"name":"Graceful Shutdown","status":"DOWN"},{"name":"Database connections health check","status":"UP","data":{"<default>":"UP"}}]}
2024-08-31 09:39:34,093 INFO [org.cch.out.AlertConsumer] (executor-thread-7) Is OK.
從目前的流程來看,可以使用下面簡易的圖來看。QUARKUS_SHUTDOWN_DELAY 值過大導致 Quarkus 並未正確關閉。因此變成要拉大 terminationGracePeriodSeconds 的秒數,來保護應用程式。
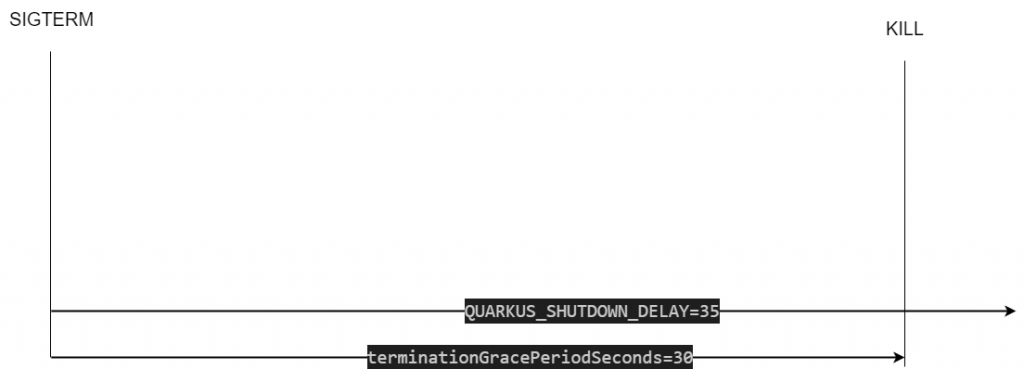
但是除了拉長外 preStop 是否可以 ? 將 YAML 新增 lifecycle.preStop 欄位。
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: gracefulshutdown
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: gracefulshutdown
app.kubernetes.io/version: day08
template:
...
spec:
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: QUARKUS_SHUTDOWN_DELAY
value: "35s"
image: registry.hub.docker.com/cch0124/gracefulshutdown:day08.3
lifecycle:
preStop:
exec:
command: ["sleep", "15"]
...
透過下圖可以來看,
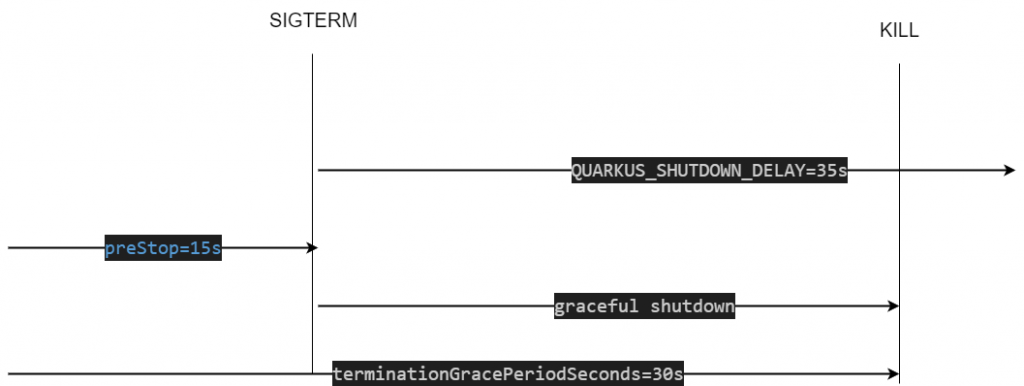
PreStop 延遲 15 秒PreStop 延遲同時間 Quarkus 持續處理請求PreStop 延遲 15 秒到之後發送 SIGTERM 訊號terminationGracePeriodSeconds 剩下 15 秒,terminationGracePeriodSeconds 15 秒到後發送 Kill 訊號,Quarkus 無法正常處理 35s 的事直接被殺掉正常優雅關閉的 Quarkus,在此範例中應該要出現以下訊息
[org.cch.LifecycleBean] (Shutdown thread) The quarkus application is stopping...
[io.quarkus] (Shutdown thread) gracefulshutdown stopped in 35.715s
對於 QUARKUS_SHUTDOWN_DELAY 而言,基本上是讓應用程式在這個期間有一個緩存,這過程中會將 rediness 探針狀態切換為 DOWN 狀態,使第三方服務不應該對此 Pod 作一個請求。
直接上 YAML
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: gracefulshutdown
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: gracefulshutdown
app.kubernetes.io/version: day08
template:
...
spec:
terminationGracePeriodSeconds: 60
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: QUARKUS_SHUTDOWN_DELAY
value: "15s"
- name: QUARKUS_SHUTDOWN_TIMEOUT
value: "30s"
image: registry.hub.docker.com/cch0124/gracefulshutdown:day08.3
lifecycle:
preStop:
exec:
command: ["sleep", "10"]
...
部署與驗證,配置了 QUARKUS_SHUTDOWN_TIMEOUT 執行完後會出現 All HTTP requests complete 訊息表示 HTTP 請求都已處理完成,因此這參數與 QUARKUS_SHUTDOWN_DELAY 是截然不同層面的配置。
2024-08-31 12:55:59,238 INFO [io.qua.ver.htt.run.fil.GracefulShutdownFilter] (executor-thread-1) All HTTP requests complete
2024-08-31 12:55:59,239 INFO [org.cch.LifecycleBean] (Shutdown thread) The quarkus application is stopping...
2024-08-31 12:56:05,607 INFO [io.quarkus] (Shutdown thread) gracefulshutdown stopped in 32.687s
下面為流程圖
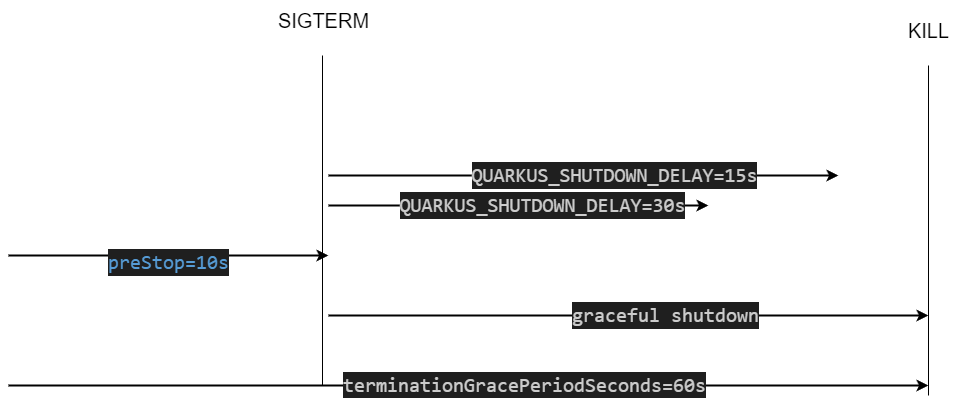
如果再刪除 Pod 過程中將,多打一個 curl http://localhost:9090/hello/longtime?time=35 35 秒的請求,依照上面配置會發生什麼 ?
沒錯,會被 QUARKUS_SHUTDOWN_DELAY 擋下,此時該請求是無法正常進到 Quarkus 服務的,因為 Endpoints 資源無 Pod 位置。如果我們嘗試將 QUARKUS_SHUTDOWN_TIMEOUT 調整成 5s 會發生什麼 ? 會出現以下訊息,因為請求 curl http://localhost:9090/hello/longtime?time=20 會發生 5s 超時,因此對於應用程式來說就會進行關閉流程,通常會回應給用戶端 503 狀態碼。
2024-08-31 13:13:49,271 ERROR [io.qua.run.shu.ShutdownRecorder] (Shutdown thread) Timed out waiting for graceful shutdown, shutting down anyway. [Error Occurred After Shutdown]
到這邊可以總結
在 Pod 和服務作優雅關閉流程
preStop 先執行preStop 先執行完成後,同時發送 SIGTERM 訊號給容器terminationGracePeriodSeconds 時間內完成將發送 KILL 訊號強制關閉Quarkus 配置的描述
QUARKUS_SHUTDOWN_DELAY 預處理,再將服務變成不可用時,緩衝時間。在這時間範圍是還可以接收流量。QUARKUS_SHUTDOWN_TIMEOUT HTTP 請求最多可等待時間。另外單純就 terminationGracePeriodSeconds 拉長時間,對 Quarkus 目前來看是沒有意義,因為收到 SIGTERM 訊號會立即將所有流量直接斷開。但是如下搭配 preStop 是能在 Quarkus 收到 SIGTERM 訊號前做一些延遲動作,這邊效果可以看上一章節。
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: gracefulshutdown
spec:
replicas: 1
...
template:
...
spec:
terminationGracePeriodSeconds: 60
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: registry.hub.docker.com/cch0124/gracefulshutdown:day08.3
lifecycle:
preStop:
exec:
command: ["sleep", "30"]
...
總而言之,服務本身的優雅關閉搭配 Pod 的優雅關閉,會是最好的實踐,即應用程式收到 SIGTERM 訊號時,可自己知道怎麼關閉服務,而不是讓 Kubernetes 資源來強制關機。服務本身對於關閉應用程式要處理很久的事物,如果大於 30s 就建議拉大預設的 terminationGracePeriodSeconds。

